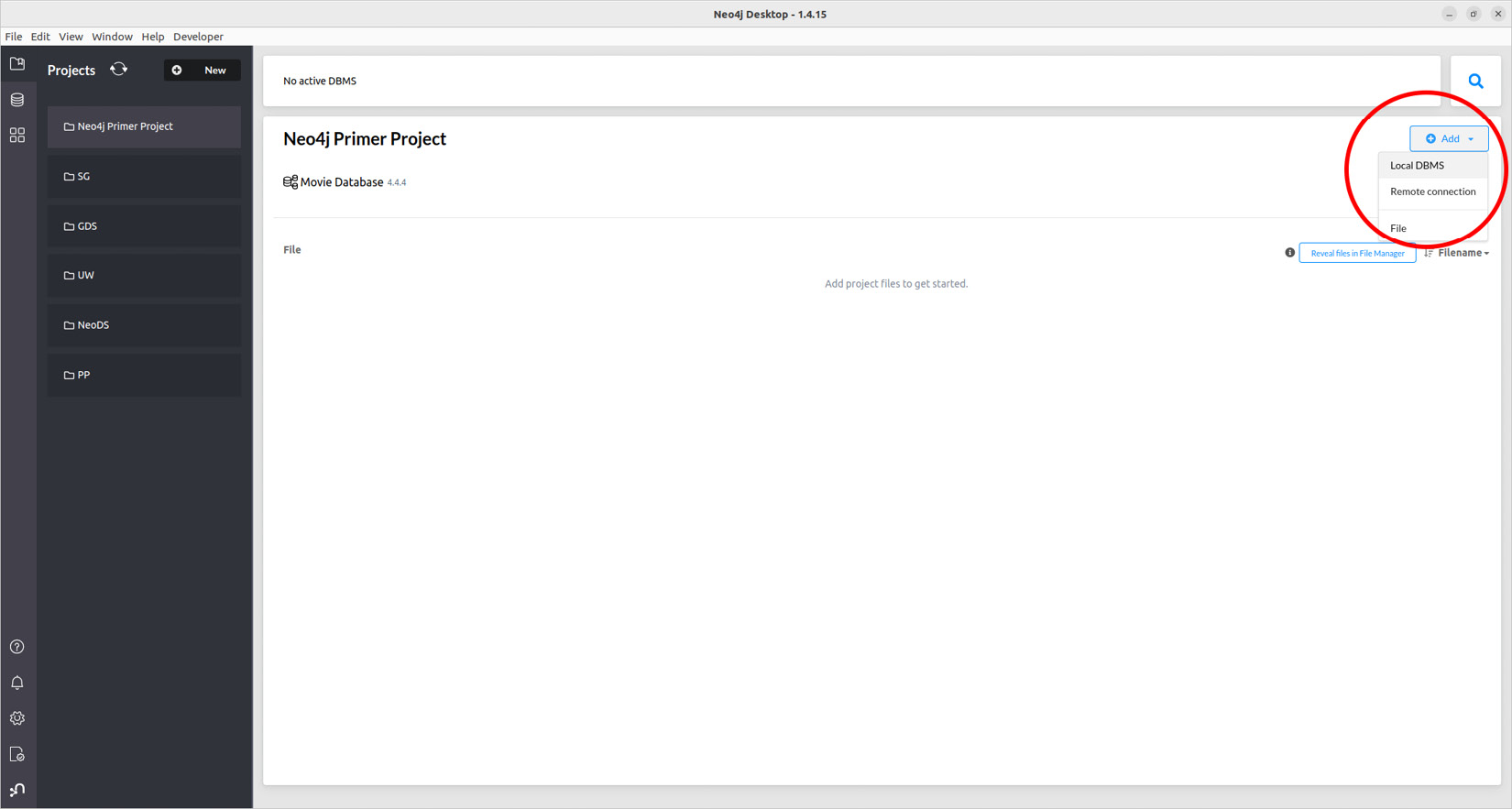
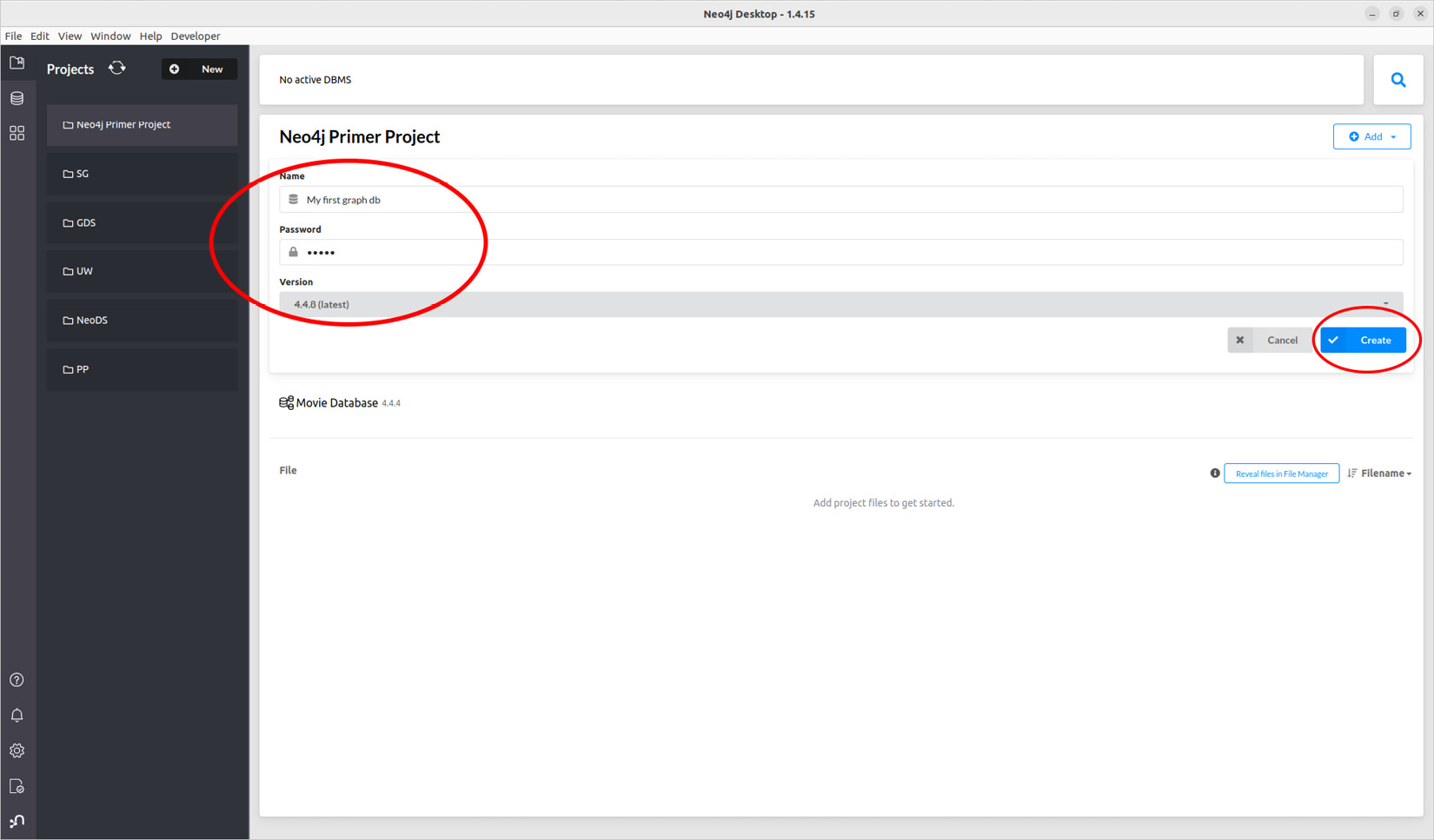
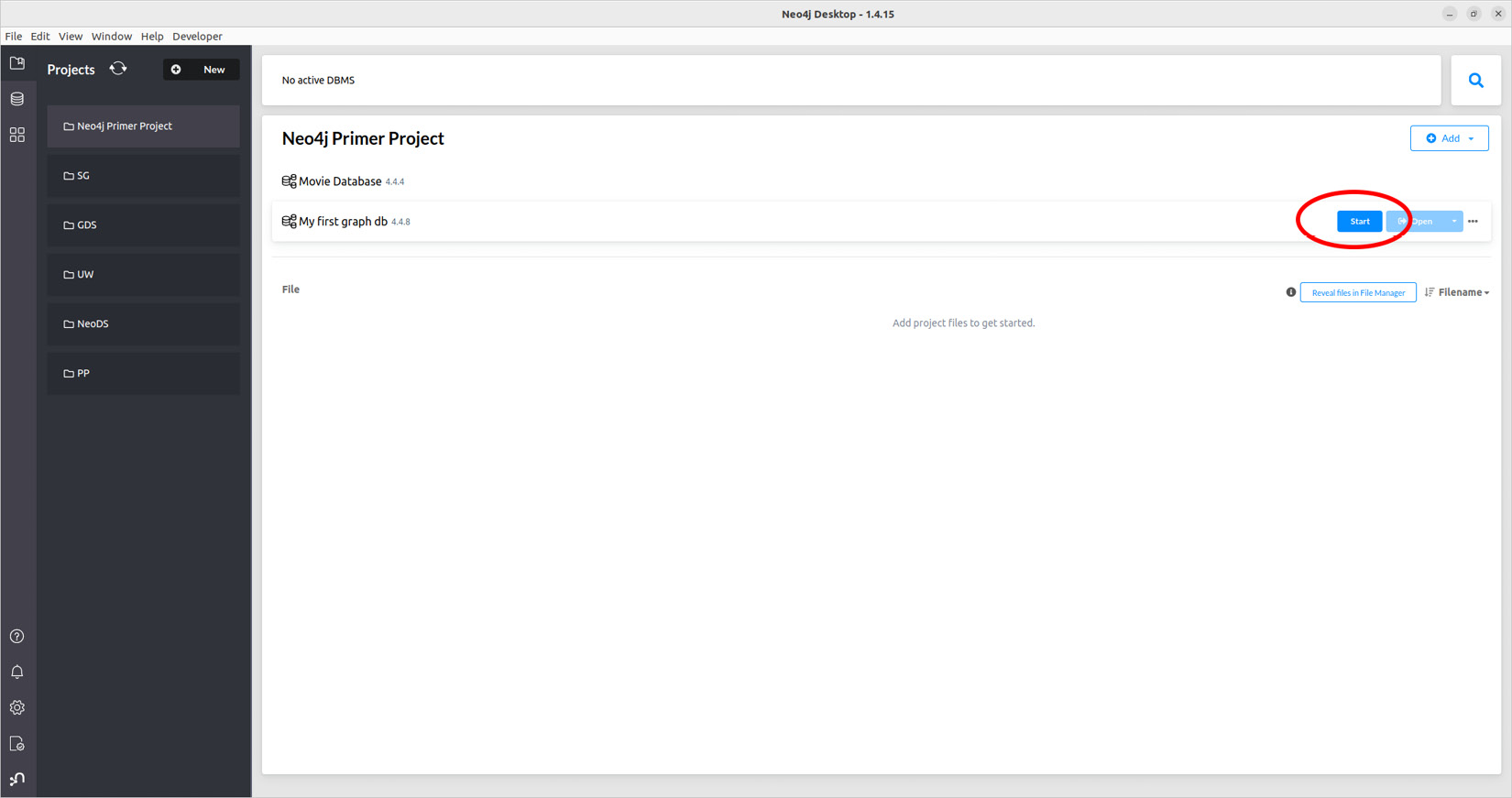
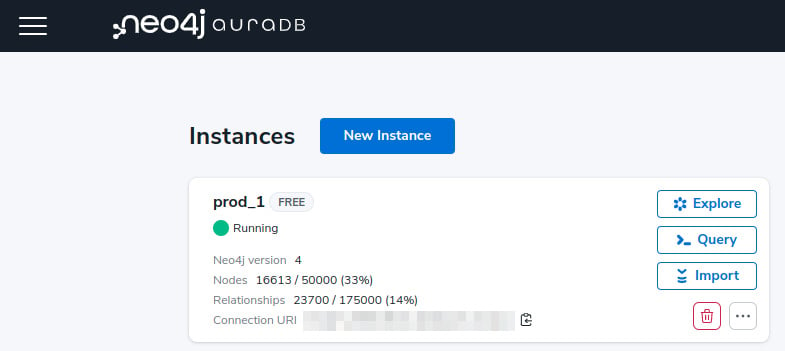
Data scientists know how to find or generate datasets that fit their needs. Randomly generating a variable distribution while following some probabilistic law is one of the first things you’ll learn in a statistics course. Similarly, graph datasets can be randomly generated, following some rules. However, this book is not a graph theory book, so we are not going to dig into these details here. Just be aware that this can be done. Please refer to the references in the Further reading section to learn more.
Regarding existing datasets, some of them are very popular and data scientists know about them because they have used them while learning data science and/or because they are the topic of well-known Kaggle competitions. Think, for instance, about the Titanic or house price datasets. Other datasets are also used for model benchmarking, such as the MNIST or ImageNet datasets in computer vision tasks.
The same holds for graph data science, where some datasets are very common for teaching or benchmarking purposes. If you investigate graph theory, you will read about the Zachary’s karate club (ZKC) dataset, which is probably one of the most famous graph datasets out there (side note: there is even a ZKC trophy, which is awarded to the first person in a graph conference that mentions this dataset). The ZKC dataset is very simple (30 nodes, as we’ll see in Chapter 3, Characterizing a Graph Dataset, and Chapter 4, Using Graph Algorithms to Characterize a Graph Dataset, on how to characterize a graph dataset), but bigger and more complex datasets are also available.
There are websites referencing graph datasets, which can be used for benchmarking in a research context or educational purpose, such as this book. Two of the most popular ones are the following:
- The Stanford Network Analysis Project (SNAP) (https://snap.stanford.edu/data/index.html) lists different types of networks in different categories (social networks, citation networks, and so on)
- The Network Repository Project, via its website at https://networkrepository.com/index.php, provides hundreds of graph datasets from real-world examples, classified into categories (for example, biology, economics, recommendations, road, and so on)
If you browse these websites and start downloading some of the files, you’ll notice the data comes in unfamiliar formats. We’re going to list some of them next.
A note about the graph dataset’s format
The datasets we are used to are mainly exchanged as CSV or JSON files. To represent a graph, with nodes on one side and edges on the other, several specific formats have been imagined.
The main data formats that are used to save graph data as text files are the following:
- Edge list: This is a text file where each row contains an edge definition. For instance, a graph with three nodes (
A, B, C) and two edges (A-B and C-A) is defined by the following edgelist file:A B
C A
- Matrix Market (with the
.mtx extension): This format is an extension of the previous one. It is quite frequent on the network repository website.
- Adjacency matrix: The adjacency matrix is an
NxN matrix (where N is the number of nodes in the graph) where the ij element is 1 if nodes i and j are connected through an edge and 0 otherwise. The adjacency matrix of the simple graph with three nodes and two edges is a 3x3 matrix, as shown in the following code block. I have explicitly displayed the row and column names only for convenience, to help you identify what i and j are: A B C
A 0 1 0
B 0 0 0
C 1 0 0
Note
The adjacency matrix is one way to vectorize a graph. We’ll come back to this topic in Chapter 7, Automatically Extracting Features with Graph Embeddings for Machine Learning.
- GraphML: Derived from XML, the GraphML format is much more verbose but lets us define more complex graphs, especially those where nodes and/or edges carry properties. The following example uses the preceding graph but adds a
name property to nodes and a length property to edges:<?xml version='1.0' encoding='utf-8'?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd"
>
<!-- DEFINING PROPERTY NAME WITH TYPE AND ID -->
<key attr.name="name" attr.type="string" for="node" id="d1"/>
<key attr.name="length" attr.type="double" for="edge" id="d2"/>
<graph edgedefault="directed">
<!-- DEFINING NODES -->
<node id="A">
<!-- SETTING NODE PROPERTY -->
<data key="d1">"Point A"</data>
</node>
<node id="B">
<data key="d1">"Point B"</data>
</node>
<node id="C">
<data key="d1">"Point C"</data>
</node>
<!-- DEFINING EDGES
with source and target nodes and properties
-->
<edge id="AB" source="A" target="B">
<data key="d2">123.45</data>
</edge>
<edge id="CA" source="C" target="A">
<data key="d2">56.78</data>
</edge>
</graph>
</graphml>
If you find a dataset already formatted as a graph, it is likely to be using one of the preceding formats. However, most of the time, you will want to use your own data, which is not yet in graph format – it might be stored in the previously described databases or CSV or JSON files. If that is the case, then the next section is for you! There, you will learn how to transform your data into a graph.
Modeling your data as a graph
The second answer to the main question in this section is: your data is probably a graph, without you being aware of it yet. We will elaborate on this topic in the next chapter (Chapter 2, Using Existing Data to Build a Knowledge Graph), but let me give you a quick overview.
Let’s take the example of an e-commerce website, which has customers (users) and products. As in every e-commerce website, users can place orders to buy some products. In the relational world, the data schema that’s traditionally used to represent such a scenario is represented on the left-hand side of the following screenshot:
Figure 1.3 – Modeling e-commerce data as a graph
The relational data model works as follows:
- A table is created to store users, with a unique identifier (
id) and a username (apart from security and personal information required for such a website, you can easily imagine how to add columns to this table).
- Another table contains the data about the available products.
- Each time a customer places an order, a new row is added to an order table, referencing the user by its ID (a foreign key with a one-to-many relationship, where a user can place many orders).
- To remember which products were part of which orders, a many-to-many relationship is created (an order contains many products and a product is part of many orders). We usually create a relationship table, linking orders to products (the order product table, in our example).
Note
Please refer to the colored version of the preceding figure, which can be found in the graphics bundle link provided in the Preface, for a better understanding of the correspondence between the two sides of the figure.
In a graph database, all the _id columns are replaced by actual relationships, which are real entities with graph databases, not just conceptual ones like in the relational model. You can also get rid of the order product table since information specific to a product in a given order such as the ordered quantity can be stored directly in the relationship between the order and the product node. The data model is much more natural and easier to document and present to other people on your team.
Now that we have a better understanding of what a graph database is, let’s explore the different implementations out there. Like the other types of databases, there is no single implementation for graph databases, and several projects provide graph database functionalities.
In the next section, we are going to discuss some of the differences between them, and where Neo4j is positioned in this technology landscape.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States