





















































Chapter 4
Modeling with Lines
In more than three centuries of science everything has changed except perhaps one thing: the love for the simple. – Jorge Wagensberg
Music—from classical compositions to Sheena is a Punk Rocker by The Ramones, passing through unrecognized hits from garage bands and Piazzolla’s Libertango—is made of recurring patterns. The same scales, combinations of chords, riffs, motifs, and so on appear over and over again, giving rise to a wonderful sonic landscape capable of eliciting and modulating the entire range of emotions that humans can experience. Similarly, the universe of statistics is built upon recurring patterns, small motifs that appear now and again. In this chapter, we are going to look at one of the most popular and useful of them, the linear model (or motif, if you want). This is a very useful model on its own and also the building block of many other models. If you’ve ever taken a statistics course, you may...
 ,(xn,yn)
,(xn,yn)
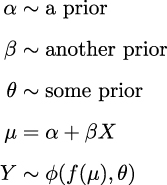
 is an arbitrary distribution; some common cases are Normal, Student’s t, Gamma, and NegativeBinomial. θ represents any auxiliary parameter the distribution may have, like σ for the Normal. We also have f, usually called the inverse link function. When
is an arbitrary distribution; some common cases are Normal, Student’s t, Gamma, and NegativeBinomial. θ represents any auxiliary parameter the distribution may have, like σ for the Normal. We also have f, usually called the inverse link function. When 










