Chapter 3
Hierarchical Models
Hierarchical models are one honking great idea – let’s do more of those! - The zen of Bayesian modeling
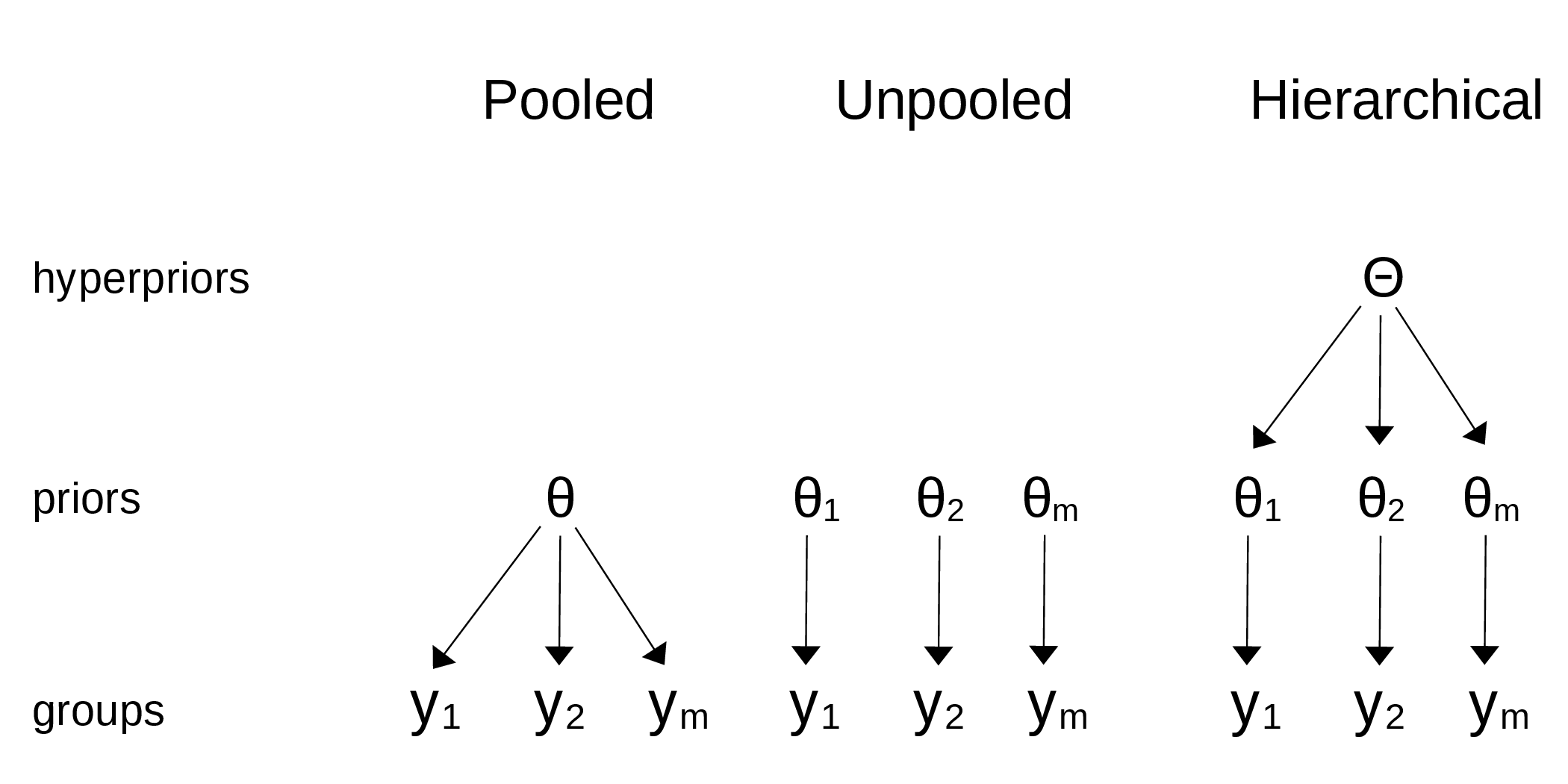
In Chapter 2, we saw a tips example where we had multiple groups in our data, one for each of Thursday, Friday, Saturday, and Sunday. We decided to model each group separately. That’s sometimes fine, but we should be aware of our assumptions. By modeling each group independently, we are assuming the groups are unrelated. In other words, we are assuming that knowing the tip for one day does not give us any information about the tip for another day. That could be too strong an assumption. Would it be possible to build a model that allows us to share information between groups? That’s not only possible, but is also the main topic of this chapter. Lucky you!
In this chapter, we will cover the following topics:
Hierarchical models
Partial pooling
Shrinkage