In this recipe, you will be introduced to the concept of a schema and its uses. A schema is a counterpart of a database, and together, these two define a namespace. There can be multiple schemas in a database, but one schema belongs to a single database. Schemas help in grouping tables and views together that are logically related. We will see how a schema is created and its use. Apart from user-created schemas, we will learn about schemas that are automatically available with a database, including the information schema provided by Snowflake.
Getting ready
The following examples can be run either via the Snowflake web UI or the SnowSQL command-line client.
How to do it…
Let's start with the creation of a user-defined schema in a user-defined database, followed by the listing of schemas:
- Let's first create a database in which we will test the schema creation:
CREATE DATABASE testing_schema_creation;
You should see a message stating that a schema was successfully created:
Figure 2.4 – Database created successfully
- Let's check whether the newly created database already has a schema in it:
SHOW SCHEMAS IN DATABASE testing_schema_creation;
You should see two rows in the result set, which are basically the two schemas that are automatically available with every new database:
Figure 2.5 – Schemas of the new database
- Let's now create a new schema. The syntax for creating a standard schema without any additional settings is quite simple, as shown in the following SQL code:
CREATE SCHEMA a_custom_schema
COMMENT = 'A new custom schema';
The command should successfully execute with the following message:
Figure 2.6 – New schema successfully created
- Let's verify that the schema has been created successfully and also look at the default values that were set automatically for its various attributes:
SHOW SCHEMAS LIKE 'a_custom_schema' IN DATABASE testing_schema_creation ;
The query should return one row displaying information such as the schema name, the database name in which the schema resides, and the time travel retention duration in days:
Figure 2.7 – Validating the schema
- Let's create another schema for which we will set the time travel duration to be
0 days and also set the type of the schema to be transient. It is common to use these settings on data for which Snowflake data protection features are not required, such as temporary data:CREATE TRANSIENT SCHEMA temporary_data
DATA_RETENTION_TIME_IN_DAYS = 0
COMMENT = 'Schema containing temporary data used by ETL processes';
The schema creation should succeed with the following message:
Figure 2.8 – New schema successfully created
- Let's view what the schema settings are by running a
SHOW SCHEMAS command as shown:SHOW SCHEMAS LIKE 'temporary_data' IN DATABASE testing_schema_creation ;
The output of SHOW SCHEMAS is shown here:
Figure 2.9 – Output of SHOW SCHEMAS
The output should show retention_time as zero or a blank value, indicating that there is no time travel storage for this schema, and also the options column should show TRANSIENT as the option, which essentially means that there will be no fail-safe storage for this schema.
How it works…
The standard CREATE SCHEMA command uses the defaults set at the database level. If you have not changed any of the configuration, the created schema will have fail-safe enabled by default. Also, time travel is enabled for the schema automatically and is set to be 1 day by default. Both these features have costs associated with them and in certain cases, you can choose to turn off these features.
For schemas that will store temporary tables, such as tables used for ETL processing, a schema can be created as a transient schema, which means that there is no fail-safe storage associated with the tables created in the schema, and therefore it would cost less. Similarly, such schemas can also be set to have time travel set to zero to reduce costs further. By default, the time travel for transient schemas is 1 day.
Do note that although we have set the schema to have no time travel and no fail-safe, we can still set individual tables within the schema to be protected by fail-safe and time travel. Setting these options at the schema level sets the default for all tables created inside that schema.
It is important to note that creating a new schema sets the current schema of the session to the newly created schema. The implication of this behavior is that any subsequent DDL commands such as CREATE TABLE would create the table under that new schema. This is like issuing the USE SCHEMA command to change the current schema.
There's more…
Every database in Snowflake will always have a public schema that is automatically created upon database creation. Additionally, under every database, you will also find an additional schema called the information schema. The information schema implements the SQL 92 standard information schema and adds additional information specific to Snowflake. The purpose of the information schema is to act as a data dictionary containing metadata that you can query to find information such as all the tables in the system, all columns along with their data types, and more. It is possible to add many additional schemas under a given database, which can help you organize your tables in a meaningful structure.
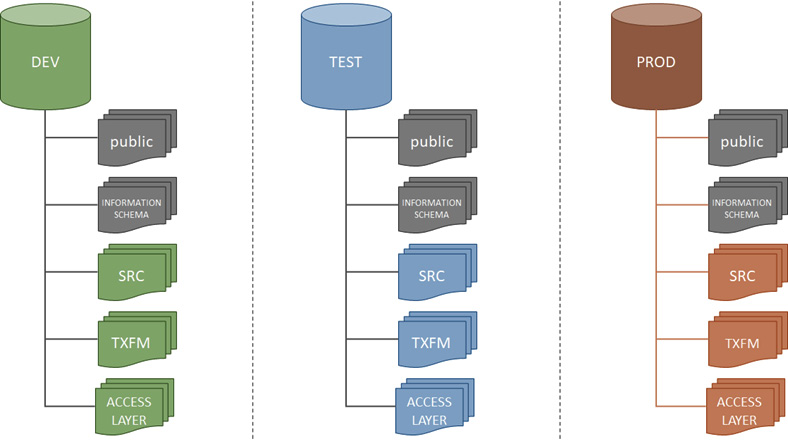
A good example of using databases and schemas to organize your data and your environment would be the approach of setting up production, testing, and development databases using the concept of schemas and databases. This approach is especially required if your organization has a single Snowflake account that is being used for development, testing, and production purposes at the same time. The approach is shown in the following diagram:
Figure 2.10 – A DEV, TEST, PROD setup using databases and schemas
In this approach, a database is created for each environment, for example, the PROD database for production data, the DEV database for development data, and so on. Within each database, the schema structures are identical; for example, each database has an SRC schema, which contains the source data. The purpose of this approach is to segregate the various environments but keep the structures identical enough to facilitate the development, testing, and productionization of data.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States