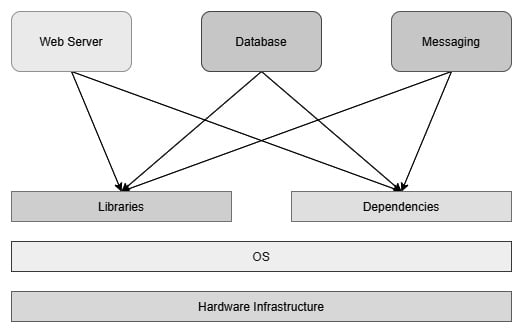
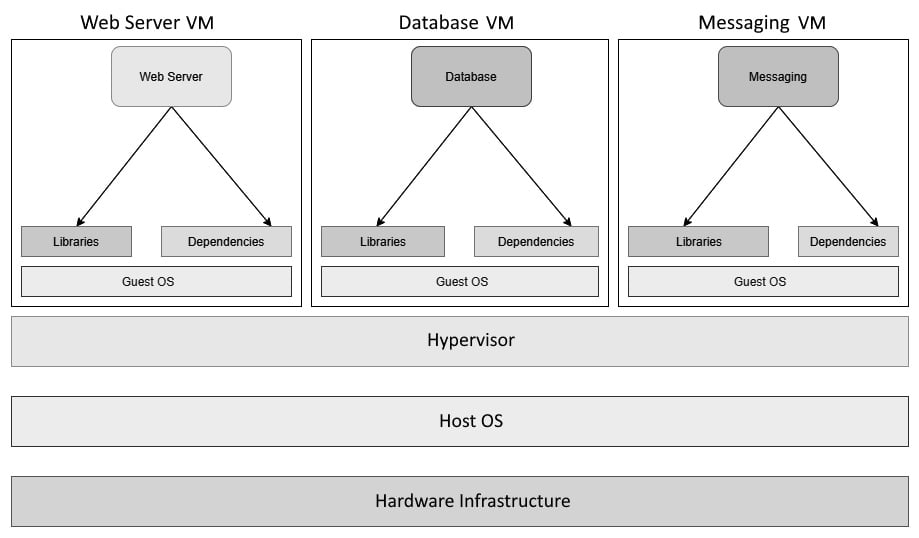
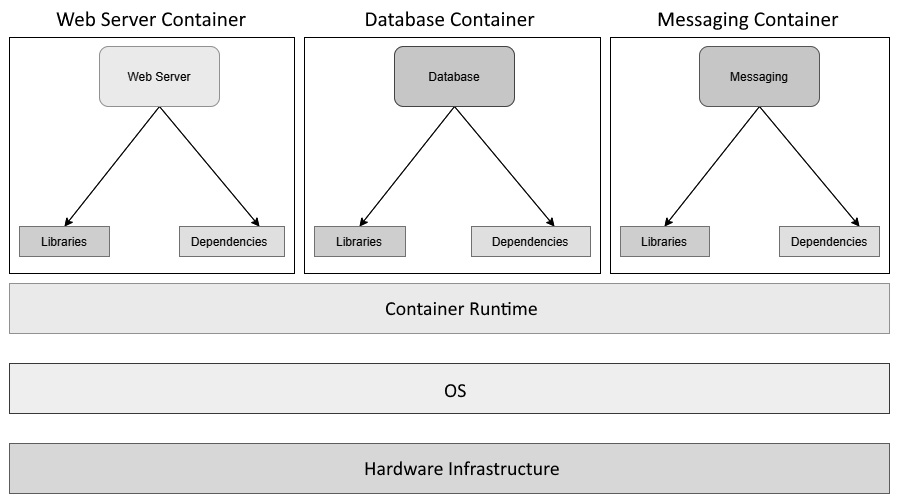
As we see the technology market moving toward containers, DevOps engineers have a crucial task–migrating applications running on virtual machines so that they can run on containers. Well, this is in most DevOps engineers' job descriptions at the moment and is one of the most critical things we do.
While, in theory, containerizing an application is simple as writing a few steps, practically speaking, it can be a complicated beast, especially if you are not using config management to set up your Virtual Machines. Virtual Machines running on current enterprises these days have been created by putting a lot of manual labor by toiling sysadmins, improving the servers piece by piece, and making it hard to reach out to the paper trail of hotfixes they might have made until now.
Since containers follow config management principles from the very beginning, it is not as simple as picking up the Virtual Machine image and using a converter to convert it into a Docker container. I wish there were such a software, but unfortunately, we will have to live without it for now.
Migrating a legacy application running on Virtual Machines requires numerous steps. Let's take a look at them in more detail.
Discovery
We first start with the discovery phase:
- Understand the different parts of your application.
- Assess what parts of the legacy application you can containerize and whether it is technically possible to do so.
- Define a migration scope and agree on the clear goals and benefits of the migration with timelines.
Application requirement assessment
Once the discovery is complete, we need to do the application requirement assessment.
- Assess if it is a better idea to break the application into smaller parts. If so, then what would the application parts be, and how will they interact with each other?
- Assess what aspects of the architecture, its performance, and its security you need to cater to regarding your application and think about the container world's equivalent.
- Understand the relevant risks and decide on mitigation approaches.
- Understand the migration principle and decide on a migration approach, such as what part of the application you should containerize first. Always start with the application with the least amount of external dependencies first.
Container infrastructure design
Once we've assessed all our requirements, architecture, and other aspects, we move on to container infrastructure design.
- Understand the current and future scale of operations when you make this decision. You can choose from a lot of options based on the complexity of your application. The right questions to ask include; how many containers do we need to run on the platform? What kind of dependencies do these containers have on each other? How frequently are we going to deploy changes to the components? What is the potential traffic the application can receive? What is the traffic pattern on the application?
- Based on the answers you get to the preceding questions, you need to understand what sort of infrastructure you will run your application on. Will it be on-premises or the cloud, and will you use a managed Kubernetes cluster or self-host and manage one? You can also look at options such as CaaS for lightweight applications.
- How would you monitor and operate your containers? Does it require installing specialist tools? Does it require integrating with the existing monitoring tool stack? Understand the feasibility and make an appropriate design decision.
- How would you secure your containers? Are there any regulatory and compliance requirements regarding security? Does the chosen solution cater to them?
Containerizing the application
When we've considered all aspects of the design, we can now start containerizing the application:
- This is where we look into the application and create a Dockerfile that contains the steps to create the container just the way it is currently. It requires a lot of brainstorming and assessment, mostly if config management tools don't build your application by running on a Virtual Machine such as Ansible. It can take a long time to figure out how the application was installed, and you need to write the exact steps for this.
- If you plan to break your application into smaller parts, you may need to build your application from scratch.
- Decide on a test suite that worked on your parallel Virtual Machine-based application and improve it with time.
Testing
Once we've containerized the application, the next step in the process is testing:
- To prove whether your containerized application works exactly like the one in the Virtual Machine, you need to do extensive testing to prove that you haven't missed any details or parts you should have considered previously. Run an existing test suite or the one you created for the container.
- Running an existing test suite can be the right approach, but you also need to consider the software's non-functional aspects. Benchmarking the original application is a good start, and you need to understand the overhead the container solution is putting in. You also need to fine-tune your application to fit the performance metrics.
- You also need to consider the importance of security and how you can bring it into the container world. Penetration testing will reveal a lot of security loopholes that you might not be aware of.
Deployment and rollout
Once we've tested our containers and are confident enough, we can roll out our application to production:
- Finally, we roll out our application to production and learn from there if further changes are needed. We then go back to the discovery process until we have perfected our application.
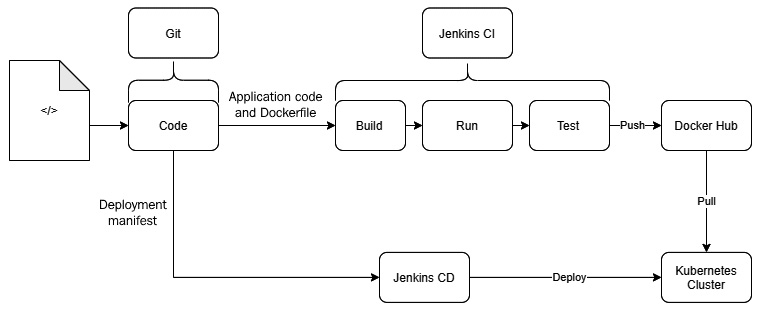
- Define and develop an automated runbook and a CI/CD pipeline to reduce cycle time and troubleshoot issues quickly.
- Doing A/B testing with the container applications running in parallel can help you realize any potential issues before you switch all the traffic to the new solution.
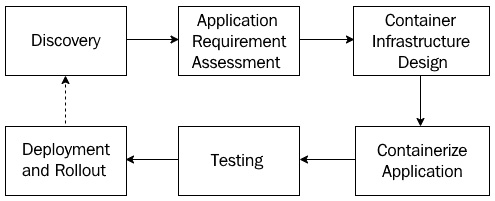
The following diagram summarizes these steps, and as you can see, this process is cyclic. This means you may have to revisit these steps from time to time, based on what you learned from the operating containers in production:
Figure 1.7 – Migrating from Virtual Machines to containers
Now let us understand what we need to do to ensure that we migrate from Virtual Machines to containers with the least friction and also attain the best possible outcome.
What applications should go in containers?
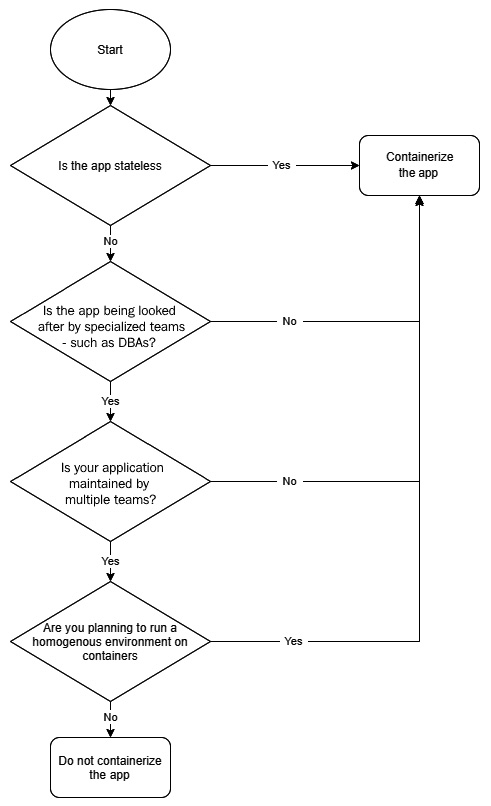
In our journey of moving from virtual machines to containers, you first need to assess what can and can't go in containers. Broadly speaking, there are two kinds of application workloads you can have – stateless and stateful. While stateless workloads do not store state and are computing powerhouses, such as APIs and functions, stateful applications such as databases require persistent storage to function.
Now, though it is possible to containerize any application that can run on a Linux Virtual Machine, stateless applications become the first low-hanging fruits you may want to look at. It is relatively easy to containerize these workloads because they don't have storage dependencies. The more storage dependencies you have, the more complex your application becomes in containers.
Secondly, you also need to assess the form of infrastructure you want to host your applications on. For example, if you plan to run your entire tech stack on Kubernetes, you would like to avoid a heterogeneous environment wherever possible. In that kind of scenario, you may also wish to containerize stateful applications. With web services and the middleware layer, most applications always rely on some form of state to function correctly. So, in any case, you would end up managing storage.
Though this might open up Pandora's box, there is no standard agreement within the industry regarding containerizing databases. While some experts are naysayers for its use in production, a sizeable population sees no issues. The primary reason behind this is because there is not enough data to support or disapprove of using a containerized database in production.
I would suggest that you proceed with caution regarding databases. While I am not opposed to containerizing databases, you need to consider various factors, such as allocating proper memory, CPU, disk, and every dependency you have in Virtual Machines. Also, it would help if you looked into the behavioral aspects within the team. If you have a team of DBAs managing the database within production, they might not be very comfortable dealing with another layer of complexity – containers.
We can summarize these high-level assessment steps using the following flowchart:
Figure 1.8 – Virtual Machine to container migration assessment
This flowchart accounts for the most common factors that are considered during the assessment. You would also need to factor in situations that might be unique to your organization. So, it is a good idea to take those into account as well before making any decisions.
Breaking the applications into smaller pieces
You get the most out of containers if you can run parts of your application independently of others.
This approach has numerous benefits, as follows:
- You can release your application more often as you can now change a part of your application without impacting the other; your deployments will also take less time to run as a result.
- Your application parts can scale independently of each other. For example, if you have a shopping app and your orders module is jam-packed, it can scale more than the reviews module, which may be far less busy. With a monolith, your entire application would scale with traffic, and this would not be the most optimized approach from a resource consumption point of view.
- Something that has an impact on one part of the application does not compromise your entire system. For example, if the reviews module is down, customers can still add items to their cart and checkout orders.
However, you should also not break your application into tiny components. This will result in considerable management overhead as you will not be able to distinguish between what is what. Going by the shopping website example, it is OK to have an order container, reviews container, shopping cart container, and a catalog container. However, it is not OK to have create order, delete order, and update order containers. That would be overkill. Breaking your application into logical components that fit your business is the right way to do it.
But should you bother with breaking your application into smaller parts as the very first step? Well, it depends. Most people would want to get a return on investment (ROI) out of your containerization work. Suppose you do a lift and shift from Virtual Machines to containers, even though you are dealing with very few variables and you can go into containers quickly. In that case, you don't get any benefits out of it – especially if your application is a massive monolith. Instead, you would be adding some application overhead on top because of the container layer. So, rearchitecting your application so that it fits in the container landscape is the key to going ahead.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States