Hyperscale cloud vendors such as Microsoft, AWS, and Google, where you can just swipe your credit card and get storage, a web server, or provision a VM of your choice, are a real game changer in the IT world and started an unstoppable revolution. The speed at which new applications are developed and rolled out gets faster and faster, and these cloud technologies reduce time-to-market dramatically. And the cloud vendors don't stop there. Let's examine the different types of offerings they provide you as their customer.
Understanding Infrastructure-as-a-Service
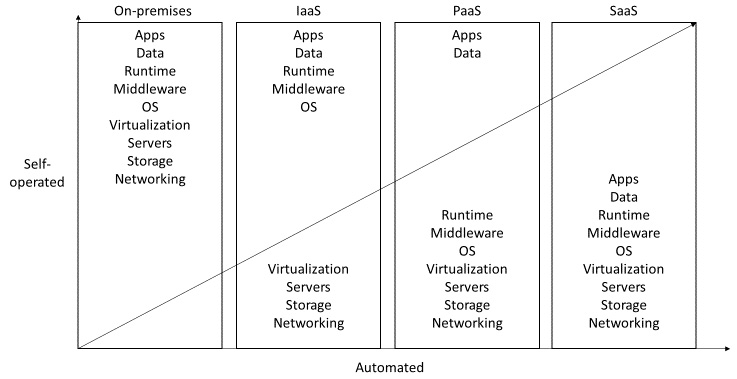
Infrastructure-as-a-Service (IaaS) was only the start. Foremost, we are talking about delivering VMs You can set up a system of VMs just as you would within your own data center, with domain controllers, database and application servers, and so on. Another example for IaaS would be storage that can be integrated just like a virtual network drive into the customers' workspaces.
Sure, a VM with a pre-installed OS and maybe some other software components is a nice thing to have. And you even can scale it if you need more power. But still, you would need to take care of patching the operating system and all the software components that have been installed, the backup and disaster recovery measurements, and so on.
Nowadays, cloud vendors are making these activities easier and help automate this process. But still, this is not the end of the speed, automation, and convenience that a cloud offering could bring:
Figure 1.1 – On-premises, IaaS, PaaS, and SaaS compared
We'll now check out PaaS.
Understanding Platform-as-a-Service
Platform-as-a-Service (PaaS) soon gained the attention of cloud users. Need a database to store data from your web app? You go to your cloud portal, click the necessary link, fill in some configuration information and click OK, and there, you are done... your web app now runs on a service that can offer far better Service-Level Agreements (SLAs) than the tower PC under the desk at your home.
For example, databases, as one interesting representative of a PaaS, offer automated patching with new versions, backup, and disaster recovery deeply integrated into the service. This is also available for a queue service or the streaming component offered on the cloud.
For databases, there are even point-in-time restores from backups that go quite far back in time, and automated geo redundancy and replication are possible, among many more functions. Without PaaS support, an administrator would need to invest a lot of time into providing a similar level of maintenance and service.
No wonder that other use cases made it to the Hyperscalers' (the big cloud vendors, which can offer nearly unlimited resources) offerings. This is also why they all (with differing levels and completeness, of course) offer PaaS capabilities to implement a Modern Data Warehouse/Data Lakehouse in their data centers nowadays.
Some of these offerings are as follows:
- Storage components that can store nearly unlimited volumes of data.
- Data integration tools that can access on-premises, cloud, and third-party software that reaches compute components.
- The ability to scale and process data in a timely manner.
- Databases that can hold the amount of data the customer needs and answer the queries against that data with enough power to fulfill the time requirements set by users.
- Reporting/dashboarding tools, or the connectivity for tools of other vendors, to consume the data in an understandable way.
- DevOps life cycle support is available to help you develop, version, deploy, and run an application and gain even more speed with a higher quality.
Understanding Software-as-a-Service
The next evolutionary step was into Software-as-a-Service (SaaS), where you can get an "all-you-can-eat" software service to fulfill your requirements, without implementing the software at all. Only the configuration, security, and connection need to be managed with a SaaS solution. Microsoft Dynamics 365 is an example of such a system. You can use an Enterprise Resource Planning (ERP) suite from the cloud without the need to have it licensed and installed in your data center. Sure, the right configuration and the development of the ERP in the cloud still needs to be done, but the Hyperscaler cloud vendor and/or the SaaS provider relieves you of which server hardware, backup and restore, SLAs, and so on to use.
However, not all cloud users want to or can rely on predefined software to solve their problems. The need for individual software is still high and, as we discussed previously, the virtualization options that are available on the cloud platforms are very attractive in this case.
Examining the possibilities of virtual machines
Development can follow a few different options. Microsoft's Azure, for example, offers different capabilities to support application development on this platform. Starting with VMs, you can make use of any setup and configuration for this application that you can think of. Spin the VM, install and run the app, and off you go.
But don't forget – everything that you need to run the app needs to be installed and configured upfront. Maybe there are VM images available that come predefined in a certain configuration. Still, you as the developer are, after spinning it up, responsible for keeping the operating system and all the installed components up-to-date and secure.
The cloud vendor, however, supports you with automation features to help you keep up with changes – to back up the VM, for example – but like every individual server or PC, a VM is a complete computer and brings that level of complexity.
Let's assume you need to run a small piece of software to offer a function or one or more microservices; a cloud-based VM may be overkill. Even with all the cloud advantages of having a VM without the need of spinning up and maintaining your own hardware and data center, this can be quite costly and more complex than what is really needed.
Again, the Hyperscaler can help as it has different offerings to overcome this complexity. Looking at Microsoft's example, there are different approaches to solving this issue.
Understanding Serverless Functions
One of these approaches is Azure Serverless Functions, which you can use to implement functionality in different languages. You can choose between C#, Java, JavaScript, PowerShell, or Python to create the function. Then, you can deploy it to the environment and just rely on the runtime environment. Seamless integration with the rest of the services, especially the data services on the platform, is available to you.
Serverless, in this case, means that the underlying infrastructure will scale with increasing and decreasing requests against the function, without needing the developer or the administrator to manually scale the backing components. This can be configured using different consumption plans, with different limits to keep control of the cost.
Cost, besides implementation speed and flexibility, is one of the most important factors when moving to cloud platforms. With the example of Serverless Functions, we find a great template for the elasticity of cloud services and the possibilities of saving money in comparison to on-premises projects.
Using a seamless scaling service for your functionality gives you the possibility to start small and start experimenting, without spending too much money. Should you find out that your development trajectory points to a dead end, you can directly stop all efforts. You can then archive or even delete the developed artifacts and restart your development with a new approach, without spending a fortune purchasing new hardware and software licenses.
Time is the investment here. Maybe these possibilities will lead to more and better judgement about the status and viability of a project that is underway. And maybe, in the future, less time will be wasted because of investments that need to be justified and followed. However, this may lead to quick-started, half-baked artifacts that are rolled out too early just because they can be started easily and cheaply. This is a situation that might lead to expensive replacement efforts and a "running in circles" situation. Therefore, a cost-effective runtime environment and a quick and easy development and deployment situation should still be approached carefully, and designed and planned to a certain degree.
Looking at the importance of containers
Container technologies are another chance to benefit from the cloud's elastic capabilities. They come with some more detailed possibilities for development and configuration in comparison to Serverless Functions. Every Hyperscaler nowadays offers one or more container technologies.
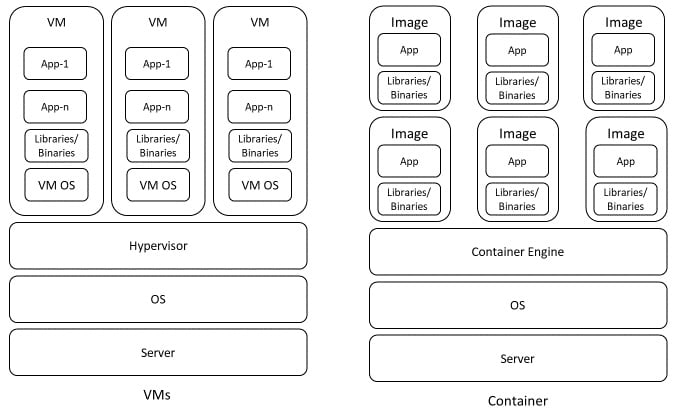
Containers enable you to deploy modularized functionalities into a runtime environment. They abstract from the OS, support all the necessary libraries and dependencies, and can hold any routine or executable that you might need. In comparison to VMs, containers can easily be ported and deployed from one OS to another. The containers that are running in a certain environment use the kernel of the OS and share it with each other.
VMs run their own OSes, apart from each other's, so they will also need far more maintenance and care. Within a container, you can concentrate on the logic and the code you want to implement, without the need to organize the "computer" around that. This also leads to a far smaller footprint for a container compared to VMs. Containers also boot far quicker than VMs and can be available quickly in an on-demand fashion. This leads to systems that can react nearly instantly to all kinds of events. A container failing, for example, can be mitigated by spinning up the image and redirecting the connection to it internally.
Therefore, in terms of their basic usage, containers are stateless to ensure quick. This adds up to the elasticity of cloud services. Developing and versioning of container modules eases their usage and increases the stability of applications based on this technology. You can roll back a buggy deployment easily, and deployments can be modularized down to small services (microservices approach).
Containers can be developed and implemented on your laptop and then deployed to a cloud repository, where they can be instantiated by the container runtime of choice.
In Microsoft Azure, the offering for containers comes from the container registry, where the typical container technologies can be placed and instantiated from. To run containers on Azure, you can use different offerings, such as Azure Container Instances or Azure Kubernetes Service (AKS). Azure Red Hat OpenShift and Azure Batch can also be used to run containers in some situations. It is also worth mentioning Azure Service Fabric and Azure App Service, which can host, use, or orchestrate containers on Azure:
Figure 1.2 – Virtual machines versus containers
Exploring the advantages of scalable environments
Modern Data Warehouse requirements may reach beyond the functionalities of the typical out-of-the-box components of the ETL/ELT tools. As serverless functions and containers can run a wide variety of programming languages, they can be used to add nearly any function that is not available by default. A typical example is consuming streaming data as it pours into the platform to the queuing endpoints. As some of the streaming components might not offer extended programming functionality, serverless functions and/or containers can add the needed features, and can also add improved performance while keeping the overall solution simple and easy to implement.
Implementing elastic storage and compute
Talking about the possibilities created by cloud computing in the field of data, analytics, and AI, I need to mention storage and compute and the distinction between the two. To scale cloud components to fulfill volume or performance requirements, there are often services where the two are closely coupled. Looking at VMs, for example, higher performance measures such as virtual CPUs automatically require more local storage, which will always cause higher costs in both dimensions. This is also true for scaling many databases. Adding vCores to a database will also add memory and will scale diskspace ranges. Looking at the databases on Azure, for example, the diskspace can be influenced in certain ranges, but these ranges are still coupled to the amount of compute that the database consumes.
The development of serverless services in the data and AI sector is leading to new patterns in storage and compute. Many use cases benefit from the separate scaling possibilities that this distinction offers. There are also complex computations on smaller datasets whose internal complexity needs some significant computational power, be it for a high amount of iterations or wider join requirements. Elastically increasing compute for a particular calculation is an opportunity to save money. Why?
As you spin up or scale a computational cluster and take it back down once the computation is done, you only pay for what you consume. The rest of the time, you run the clusters in "keep-the-lights-on" mode at a lower level to fulfill routine requests. If you don't need a compute component, you can take it down and switch it off:
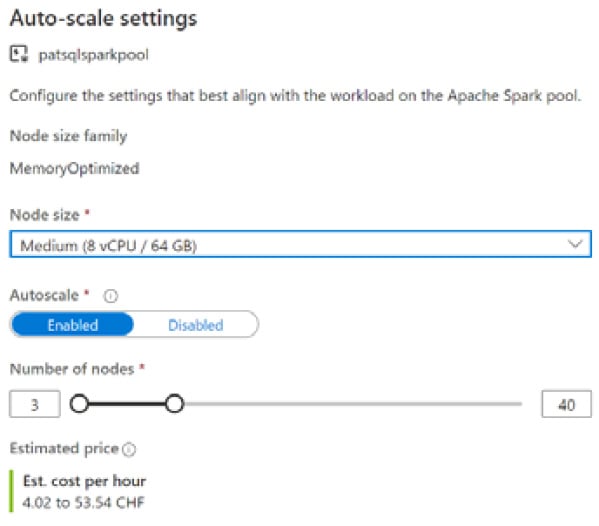
Figure 1.3 – Scaling options for Spark pools in Azure Synapse
More and more, we even see automatic scaling for compute components, such as in Spark clusters (as shown in the preceding screenshot). You can decide on lower and upper limits for the cluster to instantly react on computational peaks when they occur during a computation. The clusters will even go into hibernation mode if there is no computation going on. This can also be accomplished with the database technology that makes up the Modern Data Warehouse, for example, on Microsoft Azure.
As soon as a database is not experiencing high demand, you can scale it back down to a minimum to keep it working and answer random requests. Or, if it is not needed at all, you just switch it off and avoid any compute costs during that time. This comes in handy when you're working in development or test systems, or databases that are created for certain purposes and aren't needed 24/7. You can even do this with your production systems, which are only used during office times for an ELT/ETL load.
Hyperscaler cloud vendors don't limit you in terms of the amount and formats of data you can put into your storage service. They also often offer different storage tiers, where you can save money by deciding how much data needs to be in hot mode, a slightly more expensive mode for recurring read/write access, or "cool" mode, which is cheaper for longer periods without access. Even archive modes are available. They are the cheapest modes and intended for data that must be kept but will be accessed only in rare cases.
Cloud storage systems act just like a hard drive would in your laptop, but with far greater capacity. Looking at a Modern Data Warehouse that wants to access the storage, you would need sufficient performance when writing to or reading from such a storage. And performance is always worked on at the big cloud vendors.
Talking about Azure specifically, many measures are taken to improve performance, but also stability and reliance. One example is the fact that files are tripled and spread over different discs in the data center; they are also split into blocks, such as on HDFS, for parallel access and performance gains. This, with other, far more sophisticated techniques, increases the reading speed for analysis significantly and adds to the stability, availability, and reliability of the system.
The cloud vendors, with their storage, computational capabilities, and the elasticity of their service offerings, will lay the foundation for you to build successful and financial competitive systems. The nature of the pay-as-you-go models will make it easy for you to get started with a cloud project, pursue a challenge, and succeed with a good price/performance ratio. And, looking at the PaaS offerings, a project can be equipped with the required components in hours instead of weeks or even months. You can react, when the need arises, instead of purchasing new hardware and software over lengthy processes. If a project becomes obsolete or goes down the wrong path for any reason, deleting the related artifacts and eliminating the related cost can be done very easily.
Cloud technology can help you get things done more quickly, efficiently, and at a far lower cost. We will be talking about the advantages of cloud security later in this book.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States