


















 Download code from GitHub
Download code from GitHub
Chapter 2: Data Types and Operators
In the previous chapter, we learned about .NET Framework and understood the basic structure of a C# program. In this chapter, we will learn about data types and objects in C#. Alongside control statements, which we will explore in the next chapter, these are the building blocks of every program. We will discuss built-in data types, explain the difference between value types and reference types, and learn how to convert between types. We will also discuss the operators defined by the language as we move on.
The following topics will be covered in this chapter:
- Basic built-in data types
- Variables and constants
- Reference types and value types
- Nullable type
- Arrays
- Type conversion
- Operators
By the end of this chapter, you will be able to write a simple C# program using the aforementioned language features.
Basic data types
In this section, we will explore the basic data types. The Common Language Infrastructure (CLI) defines a set of standard types and operations that are supported by all programming languages targeting the CLI. These data types are provided in the System namespace. All of them, however, have a C# alias. These aliases are keywords in the C# language, which means they can only be used in the context of their designated purpose and not elsewhere, such as variable, class, or method names. The C# name and the .NET name, along with a short description of each type, are listed in the following table (listed alphabetically by the C# name):

The types listed in this table are called simple types or primitive types. Apart from these, there are two more built-in types:

Let's explore all of the primitive types in detail in the following sections.
The integral types
C# supports eight integer types that represent various ranges of integral numbers. The bits and range of each of them are shown in the following table:

As shown in the preceding table, C# defines both signed and unsigned integer types. The major difference between signed and unsigned integers is the way in which the high order bit is read. In the case of a signed integer, the high order bit is considered the sign flag. If the sign flag is 0, then the number is positive but if the sign flag is 1, then the number is negative.
The default value of all integral types is 0. All of these types define two constants called MinValue and MaxValue, which provide the minimum and maximum value of the type.
Integral literals, which are numbers that appear directly in code (such as 0, -42, and so on), can be specified as decimal, hexadecimal, or binary literals. Decimal literals do not require any suffix. Hexadecimal literals are prefixed with 0x or 0X, and binary literals are prefixed with 0b or 0B. An underscore (_) can be used as a digit separator with all numeric literals. Examples of such literals are shown in the following snippet:
int dec = 32; int hex = 0x2A; int bin = 0b_0010_1010;
An integral value without any suffix is inferred by the compiler as int. To indicate a long integer, use l or L for a signed 64-bit integer and ul or UL for an unsigned 64-bit integer.
The floating-point types
The floating-point types are used to represent numbers having fractional components. C# defines two floating-point types, as shown in the following table:

The float type represents a 32-bit, single-precision floating-point number, whereas double represents a 64-bit, double-precision floating-point number. These types are implementations of the IEEE Standard for Floating-Point Arithmetic (IEEE 754), which is a standard established by the Institute of Electrical and Electronics Engineers (IEEE) in 1985 for floating-point arithmetic.
The default value for floating-point types is 0. These types also define two constants called MinValue and MaxValue that provide the minimum and maximum value of the type. However, these types also provide constants that represent not-a-number (System.Double.NaN) and infinity (System.Double.NegativeInfinity and System.Double.PositiveInfinity). The following code listing shows several variables initialized with floating-point values:
var a = 42.99; float b = 19.50f; System.Double c = -1.23;
By default, a non-integer number such as 42.99 is considered a double. If you want to specify this as a float type, then you need to suffix the value with the f or F character, such as in 42.99f or 42.99F. Alternatively, you can also explicitly indicate a double literal with the d or D suffix, such as in 42.99d or 42.99D.
Floating-point types store fractional parts as inverse powers of two. For this reason, they can only represent exact values such as 10, 10.25, 10.5, and so on. Other numbers, such as 1.23 or 19.99, cannot be represented exactly and are only an approximation. Even if double has 15 decimal digits of precision, as compared to only 7 for float, precision loss starts to accumulate when performing repeated calculations.
This makes double and float difficult or even inappropriate to use in certain types of applications, such as financial applications, where precision is key. For this purpose, the decimal type is provided.
The decimal type
The decimal type can represent up to 28 decimal places. The details for the decimal type are shown in the following table:

The default value for the decimal type is 0. MinValue and MaxValue constants that define the minimum and maximum value of the type are also available. A decimal literal can be specified using the m or M suffix as shown in the following snippet:
decimal a = 42.99m; var b = 12.45m; System.Decimal c = 100.75M;
It is important to note that the decimal type minimizes errors during rounding but does not eliminate the need for rounding. For instance, the result of the operation 1m / 3 * 3 is not 1 but 0.9999999999999999999999999999. On the other hand, Math.Round(1m / 3 * 3) yields the value 1.
The decimal type is designed for use in applications where precision is key. Floats and doubles are much faster types (because they use binary math, which is faster to compute), while the decimal type is slower (as the name implies, it uses decimal math, which is slower to compute). The decimal type can be an order of magnitude slower than the double type. Financial applications, where small inaccuracies can accumulate to important values over repeated computations, are a typical use case for the decimal type. In such applications, speed is not important, but precision is.
The char type
The character type is used to represent a 16-bit Unicode character. Unicode defines a character set that is intended to represent the characters of most languages in the world. Characters are represented by enclosing them in single quotation marks (''). Examples of this include 'A', 'B', 'c' and '\u0058':

Character values can be literals, hexadecimal escape sequences that have the form '\xdddd', or Unicode representations that have the form '\udddd' (where dddd is a 16 hexadecimal value). The following listing shows several examples:
char a = 'A'; char b = '\x0065'; char c = '\u15FE';
The default value for the char type is decimal 0, or its equivalents, '\0', '\x0000', or '\u0000'.
The bool type
C# uses the bool keyword to represent the Boolean type. It can have two values, true or false, as shown in the following table:

The default value for the bool type is false. Unlike other languages (such as C++), integer values or any other values do not implicitly convert into the bool type. A Boolean variable can be either assigned a Boolean literal (true or false) or an expression that evaluates to bool.
The string type
A string is an array of characters. In C#, the type for representing a string is called string and is an alias for the .NET System.String. You can use any of these two types interchangeably. Internally, a string contains a read-only collection of char objects. This makes strings immutable, which means that you cannot change a string but need to create a new one every time you want to modify the content of an existing string. Strings are not null-terminated (unlike other languages such as C++) and can contain any number of null characters ('\0'). The string length will contain the total number of the char objects.
Strings can be declared and initialized in a variety of ways, as shown here:
string s1; // unitialized
string s2 = null; // initialized with null
string s3 = String.Empty; // empty string
string s4 = "hello world"; // initialized with text
var s5 = "hello world";
System.String s6 = "hello world";
char[] letters = { 'h', 'e', 'l', 'l', 'o'};
string s7 = new string(letters); // from an array of chars
It is important to note that the only situation when you use the new operator to create a string object is when you initialize it from an array of characters.
As mentioned before, strings are immutable. Although you have access to the characters of the string, you can read them, but you cannot change them:
char c = s4[0]; // OK s4[0] = 'H'; // error
The following are the methods that seem to be modifying a string:
Remove(): This removes a part of the string.ToUpper()/ToLower(): This converts all of the characters into uppercase or lowercase.
Neither of these methods modifies the existing string, but instead returns a new one.
In the following example, s6 is the string defined earlier, s8 will contain hello, s9 will contain HELLO WORLD, and s6 will continue to contain hello world:
var s8 = s6.Remove(5); // hello var s9 = s6.ToUpper(); // HELLO WORLD
You can convert any built-in type, such as integer or floating-point numbers, into a string using the ToString() method. This is actually a virtual method of the System.Object type, that is, the base class for any .NET type. By overriding this method, any type can provide a way to serialize an object to a string:
int i = 42; double d = 19.99; var s1 = i.ToString(); var s2 = d.ToString();
Strings can be composed in several ways:
- It can be done using the concatenating operator,
+. - Using the
Format()method: The first argument of this method is the format, in which each parameter is indicated positionally with the index specified in curly braces, such as{0},{1},{2}and so on. Specifying an index beyond the number of arguments results in a runtime exception. - Using string interpolation, which is practically a syntactic shortcut for using the
String.Format()method: The string must be prefixed with$and the arguments are specified directly in curly braces.
An example of all of these methods is shown here:
int i = 42;
string s1 = "This is item " + i.ToString();
string s2 = string.Format("This is item {0}", i);
string s3 = $"This is item {i}";
Some characters have a special meaning and are prefixed with a backslash (\). These are called escaped sequences. The following table lists all of them:

Escape sequences are necessary in certain cases, such as when you specify a Windows file path or when you need a text that spawns multiple lines. The following code shows several examples where escape sequences are used:
var s1 = "c:\\Program Files (x86)\\Windows Kits\\"; var s2 = "That was called a \"demo\""; var s3 = "This text\nspawns multiple lines.";
You can, however, avoid using escape sequences by using verbatim strings. These are prefixed with the @ symbol. When the compiler encounters such a string, it does not interpret escape sequences. If you want to use quotation marks in a string when using verbatim strings, you must double them. The following sample shows the preceding examples rewritten with verbatim strings:
var s1 = @"c:\Program Files (x86)\Windows Kits\"; var s2 = @"That was called a ""demo"""; var s3 = @"This text spawns multiple lines.";
Prior to C# 8, if you wanted to use string interpolation with verbatim strings, you had to first specify the $ symbol for string interpolation and then @ for verbatim strings. In C# 8, you can specify these two symbols in any order.
The object type
The object type is the base type for all other types in C#, even though you do not specify this explicitly, as we will see in the following chapters. The object keyword in C# is an alias for the .NET System.Object type. You can use these two interchangeably.
The object type provides some basic functionalities to all other classes in the form of several virtual methods that any derived class can override, if necessary. These methods are listed in the following table:

Apart from these, the object class contains several other methods. An important one to note is the GetType() method, which is not virtual and which returns a System.Type object with information about the type of the current instance.
Another important thing to notice is the way the Equals() method works because its behavior is different for reference and value types. We have not covered these concepts yet but will do so later in this chapter. For the time being, keep in mind that, for reference types, this method performs reference equality; this means it checks whether the two variables point to the same object on the heap. For value types, it performs value equality; this means that the two variables are of the same type and that the public and private fields of the two objects are equal.
The object type is a reference type. The default value of a variable of the object type is null. However, a variable of the object type can be assigned any value of any type. When you assign a value type value to object, the operation is called boxing. The reverse operation of converting the value of object into a value type is called unboxing. This will be detailed in a later section in this chapter.
You will learn more about the object type and its methods throughout this book.
Variables
Variables are defined as a named memory location that can be assigned to a value. There are several types of variables, including the following:
- Local variables: These are variables that are defined within a method and their scope is local to that method.
- Method parameters: These are variables that hold the arguments passed to a method during a function call.
- Class fields: These are variables that are defined in the scope of the class and are accessible to all of the class methods and depending on the accessibility of the field to other classes too.
- Array elements: These are variables that refer to elements in an array.
In this section, we will refer to local variables, which are variables declared in the body of a function. Such variables are declared using the following syntax:
datatype variable_name;
In this statement, datatype is the data type of the variable and variable_name is the name of the variable. Here are several examples:
bool f; char ch = 'x'; int a, b = 20, c = 42; a = -1; f = true;
In this example, f is an uninitialized bool variable. Uninitialized variables cannot be used in any expression. An attempt to do so will result in a compiler error. All variables must be initialized before they are used. A variable can be initialized when declared, such as with ch, b, and c in the preceding example, or at any later time, such as with a and f.
Multiple variables of the same type can be declared and initialized in a single statement, separated by a comma. This is exemplified in the preceding code snippet with the int variables a, b, and c.
Naming convention
There are several rules that must be followed for naming a variable:
- Variable names can consist of letters, digits, and underscore characters (
_) only. - You cannot use any special character other than underscore (
_) when naming a variable. Consequently, @sample, #tag, name%, and so on are illegal variable names. - The variable name must begin with a letter or an underscore character (
_). The name of the variable cannot start with a digit. Therefore,2smallas a variable name will throw a compile-time error. - Variable names are case-sensitive. Therefore,
personandPERSONare considered two different variables. - A variable name cannot be any reserved keyword of C#. Hence
true,false,double,float,var, and so on are illegal variable names. However, prefixing a keyword with@enables the compiler to treat them as identifiers, rather than keywords. Therefore, variables names such as@true,@return,@varare allowed. These are called verbatim identifiers. - Apart from the language rules that you must follow when naming variables, you should also make sure the names you choose are descriptive and easy to understand. You should always prefer that over short, abbreviated names that are hard to comprehend. There are various coding standards and naming conventions and you should adhere to one. These promote consistency and make the code easier to read, understand, and maintain.
When it comes to naming conventions, you should do the following when programming in C#:
- Use pascal case for classes, structures, enums, delegates, constructors, methods, properties, and constants. In Pascal case, each word in a name is capitalized; examples include
ConnectionString,UserGroup, andXmlReader. - Use camel case for fields, local variables, and method parameters. In camel case, the first word of a name is not capitalized, but all of the others are; examples include
userId,xmlDocument, anduiControl. - Do not use underscore in identifiers unless to prefix private fields, such as in
_firstName, and_lastName. - Prefer descriptive name over abbreviations. For example, prefer
labelTextoverlbltxtoremployeeIdovereid.
You can learn more about coding standards and naming conventions in C# by consulting additional resources.
Implicity-typed variables
As we have seen in previous examples, we need to specify the type of a variable when we are declaring it. However, C# provides us with another way to declare variables that allows the compiler to infer the variable type based on the value assigned to it during initialization. These are known as implicitly typed variables.
We can create an implicitly typed variable using the var keyword. Such variables must always be initialized on the declaration because the compiler infers the type of the variable from the value that it is initialized with. Here is an example:
var a = 10;
Since the a variable is initialized with an integer literal, a is considered as an int variable by the compiler.
When declaring variables with var, you must keep in mind the following:
- An implicitly typed variable must be initialized to a value at the time of declaration, otherwise, the compiler has no reference to infer the variable type and it results in a compile-time error.
- You cannot initialize it to null.
- The variable type cannot be changed once it is declared and initialized.
Information box
The
varkeyword is not a datatype but a placeholder for an actual type. Usingvarto declare variables is useful when the type name is long and you want to avoid typing a lot (for example,Dictionary<string, KeyValuePair<int, string>>) or you do not care about the actual type, only the value.
Now that you learned how you can declare variables, let's look at a key concept: the scope of variables.
Understanding the scope and lifetime of variables
A scope in C# is defined as a block between an opening curly brace and its corresponding closing curly brace. The scope defines the visibility and lifetime of a variable. A variable can be accessed only within the scope in which it is defined. A variable that is defined in a particular scope is not visible to the code outside that scope.
Let's understand this with the help of an example:
class Program
{
static void Main(string[] args)
{
for (int i = 1; i < 10; i++)
{
Console.WriteLine(i);
}
i = 20; // i is out of scope
}
}
In this example, the i variable is defined inside the for loop, hence it cannot be accessed outside the for loop as it goes out of scope once the control exits the loop. You will learn more about the for loop in the next chapter.
We can also have nested scopes. This means a variable defined in a scope can be accessed in another scope that is enclosed in that scope. However, the variables from the outer scope are visible to the inner scope but the inner scope variables are not accessible in the outer scope. The C# compiler won't allow you to create two variables with the same name within a scope.
Let's extend the code in the previous example to understand this:
class Program
{
static void Main(string[] args)
{
int a = 5;
for (int i = 1; i < 10; i++)
{
char a = 'w'; // compiler error
if (i % 2 == 0)
{
Console.WriteLine(i + a); // a is within the
// scope of Main
}
}
i = 20; // i is out of scope
}
}
Here, the integer variable a is defined outside the for loop but within the scope of Main. Hence, it can be accessed within the for loop as it is in the scope of this. However, the i variable, which is defined inside the for loop, cannot be accessed inside the scope of Main.
If we try to declare another variable with the same name in the scope, we will get a compile-time error. Consequently, we cannot declare a character variable a inside the for loop as we already have an integer variable with the same name.
Understanding constants
There are some scenarios in which we do not want to change the value of a variable after it is initialized. Examples can include mathematical constants (pi, Euler's number, and so on), physical constants (Avogadro's number, the Boltzmann constant, and so on), or any application-specific constants (the maximum allowed number of logins, the maximum number of retries for a failed operation, status codes, and many others). C# provides us with constant variables for this purpose. Once defined, the value of a constant variable cannot be changed during its scope. If you try to change the value of a constant variable after it is initialized, the compiler will throw an error.
To make a variable constant, we need to prefix it with the const keyword. The constant variables must be initialized at the time of declaration. Here is an example of an integer constant initialized with the value 42:
const int a = 42;
It is important to note that only the built-in types can be used to declare constants. User-defined types cannot be used for this purpose.
Reference types and value types
The data types in C# are divided into value types and reference types. There are several important differences between these two, such as copy semantics. We will look at these in detail in the following sections.
Value types
A variable of a value type contains the value directly. When a value type variable is assigned from another, the stored value is copied. The primitive data types we have seen earlier are all value types. All user-defined types declared as structures (with the struct keyword) are value types. Although all types are implicitly derived from the object, type value types do not support explicit inheritance, which is a topic discussed in Chapter 4, Understanding the Various User-Defined Types.
Let's see an example here:
int a = 20; DateTime dt = new DateTime(2019, 12, 25);
Value types are typically stored on the stack in memory, although this is an implementation detail and not a characteristic of value types. If you assign the value of a value type to another variable, then the value is copied to the new variable and changing one variable will not affect the other:
int a = 20; int b = a; // b is 20 a = 42; // a is 42, b is 20
In the preceding example, the value of a is initialized to 20 and then assigned to the variable b. At this point, both variables contain the same value. However, after assigning the value 42 to the a variable, the value of b remains unchanged. This is shown, conceptually, in the following diagram:

Figure 2.1 – A conceptual representation of the changes in the stack during the execution of the previous code
Here, you can see that, initially, a storage location corresponding to the a integer was allocated on the stack and had the value 20. Then, a second storage location was allocated and the value from the first was copied to it. Then, we changed the value of the a variable and therefore, the value available in the first storage location. The second one was left untouched.
Reference types
A variable of a reference type does not contain the value directly but a reference to a memory location where the actual value is stored. The built-in data types object and string are reference types. Arrays, interfaces, delegates, and any user-defined type defined as a class are also called reference types. The following example shows several variables of different reference types:
int[] a = new int[10]; string s = "sample"; object o = new List<int>();
Reference types are stored on the heap. Variables of a reference type can be assigned the null value that indicates that the variable does not store a reference to an instance of an object. When trying to use a variable assigned the null value the result is a runtime exception. When a variable of a reference type is assigned a value, the reference to the actual memory location of the object is copied and not the value of the object itself.
In the following example, a1 is an array of two integers. The reference to the array is copied to the a2 variable. When the content of the array changes, the changes are visible both through a1 and a2, since both these variables refer to the same array:
int[] a1 = new int[] { 42, 43 };
int[] a2 = a1; // a2 is { 42, 43 }
a1[0] = 0; // a1 is { 0, 43 }, a2 is { 0, 43 }
This example is explained conceptually in the following diagram:

Figure 2.2 – The conceptual representation of the stack and the heap during the execution of the preceding snippet
You can see in this diagram that a1 and a2 are variables on the stack pointing to the same array of integers allocated on the heap. When the first element of the array is changed through the a1 variable, the changes are automatically visible to the a2 variable because a1 and a2 refer to the same object.
Although the string type is a reference type, it appears to behave differently. Take the following example:
string s1 = "help"; string s2 = s1; // s2 is "help" s1 = "demo"; // s1 is "demo", s2 is "help"
Here, s1 is initialized with the "help" literal and then the reference to the actual array heap object is copied to the s2 variable. At this point, they both refer to the "help" string. However, s1 is later assigned a new string, "demo". At this point, s2 will continue to refer to the "help" string. The reason for this is that strings are immutable. That means when you modify a string object, a new string is created, and the variable will receive the reference to the new string object. Any other variables referring to the old string will continue to do so.
Boxing and unboxing
We briefly mentioned boxing and unboxing earlier in this chapter when we talked about the object type. Boxing is the process of storing a value type inside an object, and unboxing is the opposite operation of converting the value of an object to a value type. Let's understand this with the help of an example:
int a = 42; object o = a; // boxing o = 43; int b = (int)o; // unboxing Console.WriteLine(x); // 42 Console.WriteLine(y); // 43
In the preceding code, a is a variable of the type integer that is initialized with the value 42. Being a value type, the integer value 42 is stored on the stack. On the other hand, o is a variable of type object. This is a reference type. That means it only contains a reference to a heap memory location where the actual object is stored. So, when a is assigned to o, the process called boxing occurs.
During the boxing process an object is allocated on the heap, the value of a (which is 42) is copied to it, and then a reference to this object is assigned to the o variable. When we later assigned the value 43 to o, only the boxed object changes and not a. Lastly, we copy the value of the object referred by o to a new variable called b. This will have the value 43 and, being an int, is also stored on the stack.
The process described here is shown graphically in the following diagram:

Figure 2.3 – Conceptual representation of the stack showing the boxing and unboxing process described previously
Now that you understand the difference between value and reference types, let's look at the topic of nullable types.
Nullable types
Reference types have the default value null, which indicates that a variable is not assigned to the instance of any object. Value types do not have such an option. However, there are cases when no value is a valid value for a value type too. To represent such cases, you can use a nullable type.
A nullable type is an instance of System.Nullable<T>, a generic value type that can represent the values of an underlying T type, which can only be a value type, as well as an additional null value. The following sample shows a few examples:
Nullable<int> a; Nullable<int> b = null; Nullable<int> c = 42;
You can use the shorthand syntax, T?, instead of Nullable<T>; these two are interchangeable. The following examples are alternatives for the preceding ones:
int? a; int? b = null; int? c = 42;
You can use the HasValue property to check whether a nullable type object has a value, and Value to access the underlying value:
if (c.HasValue) Console.WriteLine(c.Value);
The following is a list of some of the characteristics of nullable types:
- You assign values to a nullable type object the same way you would assign to the underlying type.
- You can use the
GetValueOrDefault()method to get either the assigned value or the default value of the underlying type if no value is assigned. - Boxing is performed on the underlying type. If the nullable type object has not assigned any value, the result of boxing is a
nullobject. - You can use the null-coalescing operator,
??, to access the value of the object of a nullable type (for example,int d = c ?? -1;).
In C# 8, nullable reference types and non-nullable reference types have been introduced. That is a feature that you must opt for in the project properties. It allows you to make sure that only objects of reference types that are declared nullable, using the T? syntax can be assigned the null value. Attempts to do so on non-nullable reference types will result in a compiler warning (not an error, because that has the potential to affect large portions of existing code):
string? s1 = null; // OK, nullable type string s2 = null; // error, non-nullable type
You will learn more about nullable reference types in Chapter 15, New Features of C# 8.
Arrays
An array is a data structure that holds multiple values (including zero or a single one) of the same data type. It is a fixed-size sequence of homogeneous elements that are stored in contiguous memory locations. Arrays in C# are zero-indexed, meaning that the position of the first element of an array is zero and the position of the last element of the array is a total number of elements minus one.
The array type is a reference type and therefore arrays are allocated on the heap. The default value for the elements of numeric arrays is zero and for arrays of reference types, the default value is null. The type of the elements of an array can be of any type, including another array type.
Arrays in C# can be one-dimensional, multi-dimensional, or jagged. Let's explore these in detail.
One-dimensional arrays
A one-dimensional array can be defined using the syntax datatype[] variable_name. Arrays can be initialized when they are declared. If an array variable is not initialized, its value is null. You can specify the number of elements of the array when you initialize it, or you can skip this and let the compiler infer it from the initialization expression. The following sample shows various ways of declaring and initializing arrays:
int[] arr1;
int[] arr2 = null;
int[] arr3 = new int[6];
int[] arr4 = new int[] { 1, 1, 2, 3, 5, 8 };
int[] arr5 = new int[6] { 1, 1, 2, 3, 5, 8 };
int[] arr6 = { 1, 1, 2, 3, 5, 8 };
In this example, arr1 and arr2 have the value null. arr3 is an array of six integer elements all set to 0 because no initialization was provided. arr4, arr5, and arr6 are arrays of six integers, all containing the same values.
Once initialized, the size of the array cannot be changed. If you need to do so, you must either create a new array object or instead use a variable-size container, such as List<T>, which we will look at in Chapter 7, Collections.
You can access the elements of the array using the indexer, or with an enumerator. The following snippets are equivalent:
for(int i = 0; i < arr6.Length; ++i) Console.WriteLine(arr6[i]); foreach(int element in arr6) Console.WriteLine(element);
Although the effect of these two loops is the same, there is a subtle difference—using an enumerator does not make it possible to modify the elements of the array. Accessing the elements by their index using the index operator does provide write access to the elements. Using an enumerator is possible because array types derive implicitly from the base type, System.Array, which implements IEnumerable and IEnumerable<T>.
This is shown in the following example:
for (int i = 0; i < arr6.Length; ++i) arr6[i] *= 2; // OK foreach (int element in arr6) element *= 2; // error
In the first loop, we access the elements of the array by their index and can modify them. However, in the second loop, an iterator is used, and this provides read-only access to the elements. Trying to modify them produces a compile-time error.
Multi-dimensional arrays
A multi-dimensional array is an array with more than one dimension. It is also called a rectangular array. This can be, for instance, a two-dimensional array (a matrix) or a three-dimensional array (a cube). The maximum number of dimensions is 32.
A two-dimensional array can be defined using the following syntax: datatype[,] variable_name;. Multi-dimensional arrays are declared and initialized in a similar fashion with single-dimensional arrays. You can specify the rank (which is the number of elements) of each dimension or you can leave it to the compiler to infer it from an initialization expression. The following snippet shows different ways of declaring and initializing two-dimensional arrays:
int[,] arr1;
arr1 = new int[2, 3] { { 1, 2, 3 }, { 4, 5, 6 } };
int[,] arr2 = null;
int[,] arr3 = new int[2,3];
int[,] arr4 = new int[,] { { 1, 2, 3 }, { 4, 5, 6 } };
int[,] arr5 = new int[2,3] { { 1, 2, 3 }, { 4, 5, 6 } };
int[,] arr6 = { { 1, 2, 3 }, { 4, 5, 6 } };
In this example, arr1 is initially null and then assigned a reference to an array of two rows and three columns. Similarly, arr2 is also null. On the other hand, arr3, arr4, arr5, and arr6 are arrays of two rows and three columns; arr3 has all of the elements set to zero, while the others are initialized with the specified values. The arrays in this example have the following form:
1 2 3 4 5 6
You can retrieve the number of elements of each dimension using the GetLength() or GetLongLength() methods (the first returns a 32-bit integer, the second a 64-bit integer). The following example prints the content of the arr6 array to the console:
for (int i = 0; i < arr6.GetLength(0); ++i)
{
for (int j = 0; j < arr6.GetLength(1); ++j)
{
Console.Write($"{arr6[i, j]} ");
}
Console.WriteLine();
}
Arrays with more than two dimensions are created and handled in a similar way. The following example shows how to declare and initialize a three-dimensional array of 4 x 3 x 2 elements:
int[,,] arr7 = new int[4, 3, 2]
{
{ { 11, 12}, { 13, 14}, {15, 16 } },
{ { 21, 22}, { 23, 24}, {25, 26 } },
{ { 31, 32}, { 33, 34}, {35, 36 } },
{ { 41, 42}, { 43, 44}, {45, 46 } }
};
Another form of multi-dimensional arrays is the so-called jagged array. We will learn about this next.
Jagged arrays
Jagged arrays are arrays of arrays. These consist of other arrays, and each array inside a jagged array can be of a different size. We can declare a two-dimensional jagged array, for instance, using the syntax datatype [][] variable_name;. The following snippet shows various examples of declaring and initializing jagged arrays:
int[][] arr1;
int[][] arr2 = null;
int[][] arr3 = new int[2][];
arr3[0] = new int[3];
arr3[1] = new int[] { 1, 1, 2, 3, 5, 8 };
int[][] arr4 = new int[][]
{
new int[] { 1, 2, 3 },
new int[] { 1, 1, 2, 3, 5, 8 }
};
int[][] arr5 =
{
new int[] { 1, 2, 3 },
new int[] { 1, 1, 2, 3, 5, 8 }
};
int[][,] arr6 = new int[][,]
{
new int[,] { { 1, 2}, { 3, 4 } },
new int[,] { {11, 12, 13}, { 14, 15, 16} }
};
In this example, arr1 and arr2 are both set to null. On the other hand, arr3 is an array of two arrays. Its first element is set to an array of three elements that are initialized with zero; its second element is set to an array of six elements initialized from the provided values.
The arr4 and arr5 arrays are equivalent, but arr5 uses the shorthand syntax for array initialization. arr6 mixes jagged arrays with multi-dimensional arrays. It is an array of two arrays, the first one being a two-dimensional array of 2x2, and the second a two-dimensional array of 2x3 elements.
The elements of a jagged array can be accessed using the arr[i][j] syntax (this example is for two-dimensional arrays). The following snippet shows how to print the content of the arr5 array shown earlier:
for(int i = 0; i < arr5.Length; ++i)
{
for(int j = 0; j < arr5[i].Length; ++j)
{
Console.Write($"{arr5[i][j]} ");
}
Console.WriteLine();
}
Now that we have looked at the type of arrays we can use in C#, let's move to another important topic, which is conversion between various data types.
Type conversion
Sometimes we need to convert one data type into another, and that is where type conversion comes in picture. Type conversion can be classified into several categories:
- Implicit type conversion
- Explicit type conversion
- User-defined conversions
- Conversions with helper classes
Let's explore these in detail.
Implicit type conversion
For built-in numeric types, when we assign the value of a variable to one of another data type, implicit type conversion occurs if both types are compatible and the range of destination type is more than that of the source type. For example, int and float are compatible types. Therefore, we can assign an integer variable to a variable of the float type. Similarly, the double type is large enough to hold values from any other numerical type, including long and float, as shown in the following example:
int i = 10; float f = i; long l = 7195467872; double d = l;
The following table shows the implicit type conversion between numeric types in C#:

There are several things to note about implicit numeric conversions:
- You can convert any integral type to any floating-point type.
- There is no implicit conversion to the
char,byte, andsbytetypes. - There is no implicit conversion from
doubleanddecimal; this includes no implicit conversion fromdecimaltodoubleorfloat.
For reference types, the implicit conversion is always possible between a class and one of its direct or indirect base classes or interfaces. Here is an example with an implicit conversion from string to object:
string s = "example"; object o = s;
The object type (which is an alias for System.Object) is the base class for all .NET types, including string (which is an alias for System.String). Therefore, an implicit conversion from string into object exists.
Explicit type conversion
When an implicit conversion between two types is not possible because there is a risk of losing information (such as while assigning the value of a 32-bit integer to a 16-bit integer), explicit type conversion is necessary. Explicit type conversion is also called a cast. To perform casting, we need to specify the target data type in parentheses in front of the source variable.
For example, double and int are incompatible types. Consequently, we need to do an explicit type conversion between them. In the following example, we assign a double value (d) to an integer using explicit type conversion. However, while doing this conversion, the fractional part of the double variable will be truncated. Hence, the value of i will be 12:
double d = 12.34; int i = (int)d;
The following table shows the list of predefined explicit conversions between numeric types in C#:

There are several things to note about explicit numeric conversions:
- An explicit conversion may result in precision loss or in throwing an exception, such as
OverflowException. - When converting from an integral type to another integral type, the result depends on the so-called checked context and may result either in a successful conversion, which may discard extra most-significant bytes, or in an overflow exception.
- When you convert a floating-point type to an integral type, the value is rounded toward zero to the nearest integral value. The operation may, however, also result in an overflow exception.
C# statements can execute either in a checked or unchecked context, which is control either with the check and unchecked keywords or with the compiler option, -checked. When none of these are specified, the context is considered unchecked for non-constant expressions. For constant expressions, which can be evaluated at compile time, the default context is always checked. In a checked context, overflow checking is enabled for integral-type arithmetic operations and conversions. In an unchecked context, these checks are suppressed. When overflow checking is enabled and overflow occurs, the runtime throws a System.OverflowException exception.
For reference types, an explicit cast is required when you want to convert from a base class or interface into a derived class. The following example shows a cast from an object to a string value:
string s = "example"; object o = s; // implicit conversion string r = (string)o; // explicit conversion
The conversion from string into object is performed implicitly. However, the opposite requires an explicit conversion in the (string)o form, as shown in the preceding snippet.
User-defined type conversions
A user-defined conversion can define an implicit or explicit conversion or both from one type into another. The type that defines these conversions must be either the source or the target type. To do so, you must use the operator keyword followed by implicit or explicit. The following example shows a type called fancyint, which defines implicit and explicit conversions from and to int:
public readonly struct fancyint
{
private readonly int value;
public fancyint(int value)
{
this.value = value;
}
public static implicit operator int(fancyint v) => v.value;
public static explicit operator fancyint(int v) => new fancyint(v);
public override string ToString() => $"{value}";
}
You can use this type as follows:
fancyint a = new fancyint(42); int i = a; // implicit conversion fancyint b = (fancyint)i; // explicit conversion
In this example, a is an object of the fancyint type. The value of a can be implicitly converted into int, because an implicit conversion operator is defined. However, the conversion from int to fancyint is defined as explicit, therefore a cast is necessary, as in (fancyint)i.
Conversions with helper classes
Conversion with a helper class or method is useful to convert between incompatible types, such as between a string and an integer or a System.DateTime object. There are various helper classes provided by the framework, such as the System.BitConverter class, the System.Convert class, and the Parse() and TryParse() methods of the built-in numeric types. However, you can provide your own classes and methods to convert between any types.
The following listing shows several examples of conversion using helper classes:
DateTime dt1 = DateTime.Parse("2019.08.31");
DateTime.TryParse("2019.08.31", out DateTime dt2);
int i1 = int.Parse("42"); // successful, i1 = 42
int i2 = int.Parse("42.15"); // error, throws exception
int.TryParse("42.15", out int i3); // error, returns false,
// i3 = 0
It is important to note the key difference between Parse() and TryParse(). The former tries to perform parsing and if that succeeds, it returns the parsed value; but if it fails, it throws an exception. The latter does not throw an exception, but returns bool, indicating the success or failure, and sets the second out parameter to the parsed value if successful or to the default value if it fails.
Operators
C# provides an extensive set of operators for built-in types. Operators are broadly classified in the following categories: arithmetic, relational, logical, bitwise, assignment, and other operators. Some operators can be overloaded for user-defined types. This topic will be further discussed in Chapter 5, Object-Oriented Programming in C#.
When evaluating an expression, operator precedence and associativity determine the order in which the operations are performed. You can change this order by using parentheses, just like you would do with a mathematical expression.
The following table lists the order of the operators with the highest precedence at the top and the lowest at the bottom. Operators that are listed together, on the same row, have equal precedence:

For operators with the same precedence, associativity determines which one is evaluated first. There are two types of associativity:
- Left-associativity: This determines operators to be evaluated from left to right. All of the binary operators are left-associative except for the assignment operators and the null coalescing operators.
- Right-associativity: This determines operators to be evaluated from right to left. The assignment operator, the null-coalescing operator, and the conditional operator are right-associative.
In the following sections, we will take a closer look at each category of operators.
Arithmetic operators
Arithmetic operators perform arithmetic operations on the numerical type and can be unary or binary operators. A unary operator has a single operand, and a binary operator has two operands. The following set of arithmetic operators are defined in C#:
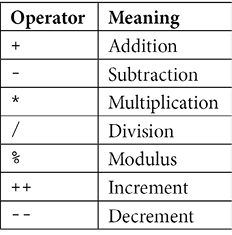
+, -, and * will work as per the mathematical rules of addition, subtraction, and multiplication respectively. However, the / operator behaves a bit differently. When applied to an integer, it will truncate the remainder of the division. For example, 20/3 will return 6. To get the remainder, we need to use the modulus operator. For example, 20%3 will return 2.
Among these, the increment and decrement operators require special attention. These operators have two forms:
- A postfix form
- A prefix form
The increment operator will increase the value of its operand by 1, whereas the decrement operator will decrease the value of its operand by 1. In the following example, the a variable is initially 10, but after applying the increment operator, its value will be 11:
int a = 10; a++;
The prefix and the postfix variants differ in the following way:
- The prefix operator first performs the operation and then returns the value.
- The postfix operator first retains the value, then increments it, and then returns the original value.
Let's understand this with the help of the following code snippet. In the following example, a is 10. When a++ is assigned to b, b takes the value 10 and a is incremented to 11:
int a = 10; int b = a++;
However, if we change this so that we assign ++a to b, then a will be incremented to 11, and that value will be assigned to b, so both a and b will have the value 11:
int a = 10; int b = ++a;
The next category of operators that we will learn about is the relational operator.
Relational operators
Relational operators, also called comparison operators, perform a comparison on their operands. C# defines the following sets of relational operators:

The result of a relational operator is a bool value. These operators support all of the built-in numerical and floating-point types. However, enumerations also support these operators. For operands of the same enumeration type, the corresponding values of the underlying integral types are compared. Enumerations will be later discussed in Chapter 4, Understanding the Various User-Defined Types.
The next code listing shows several relational operators being used:
int a = 42;
int b = 10;
bool v1 = a != b;
bool v2 = 0 <= a && a <= 100;
if(a == 42) { /* ... */ }
The <, >, <=, and >= operators can be overloaded for user-defined types. However, if a type overloads < or >, it must overload both of them. Similarly, if a type overloads <= or >=, it must overload both of them.
Logical operators
Logical operators perform a logical operation on bool operands. The following set of logical operators are defined in C#:

The following example shows these operands in use:
bool a = true, b = false; bool c = a && b; bool d = a || !b;
In this example, since a is true and b is false, c will be false and d will be true.
Bitwise and shift operators
A bitwise operator will work directly on the bits of their operands. A bitwise operator can only be used with integer operands. The following table lists all of the bitwise and shift operators:

In the following example, a is 10, which in binary is 1010, and b is 5, which in binary is 0101. The result of the bitwise AND is 0000, so c will have the value 0, and the result of bitwise OR is 1111, so d will have the value 15:
int a = 10; // 1010 int b = 5; // 0101 int c = a & b; // 0000 int d = a | b; // 1111
The left-shift operator shifts the left-hand operand to the left by the number of bits defined by the right-hand operand. Similarly, the right-shift operator shifts the left-hand operand to the right by the number of bits defined by the right-hand operand. The left-shift operator discards the higher-order bits that are outside the range of the result type and sets the lower-order bits to zero. The right-shift operator discards the lower-order bits and the higher-order bits are set as follows:
- If the value that is shifted is
intorlong, an arithmetic shift is performed. That means the sign bit is propagated to the right on the higher-order empty bits. As a result, for a positive number, the higher-order bits are set to zero (because the sign bit is 0) and for a negative number, the higher-order bits are set to one (because the sign bit is 1). - If the value that is shifted is
uintorulong, a logical shift is performed. In this case, the higher-order bits are always set to0.
The shift operations are only defined for int, uint, long, and ulong. If the left-hand operand is of another integral type, it is converted to int before the operation is applied. The result of a shift operation will always contain at least 32 bits.
The following listing shows examples of shifting operations:
// left-shifting int x = 0b_0000_0110; x = x << 4; // 0b_0110_0000 uint y = 0b_1111_0000_0000_0000_1111_1110_1100_1000; y = y << 2; // 0b_1100_0000_0000_0011_1111_1011_0010_0000; // right-shifting int x = 0b_0000_0000; x = x >> 4; // 0b_0110_0000 uint y = 0b_1111_0000_0000_0000_1111_1110_1100_1000; y = y >> 2; // 0b_0011_1100_0000_0000_0011_1111_1011_0010;
In this example, we initialized the x and y variables with binary literals to make it easier to understand how shifting works. The value of the variables after shifting is also shown in binary in the comments.
Assignment operators
An assignment operator assigns a value to its left operand based on the value of its right operand. The following assignment operators are available in C#:

In this table, we have the simple assignment operator (=) that assigns the right-hand value to the left operand, and then we have compound assignment operators, that first perform an operation (arithmetical, shifting, or bitwise) and then assign the result of the operation to the left operand. Therefore, operations such as a = a + 2 and a += 2 are equivalent.
Other operators
Apart from the operators discussed so far, there are other useful operators in C# that work both on built-in types and user-defined types. These include the conditional operator, the null-conditional operators, the null-coalescing operator, and the null-coalescing assignment operator. We will look at these operators in the following pages.
The ternary conditional operator
The ternary conditional operator is denoted by ?: and often simply referred to as the conditional operator. It allows you to return a value from two available options based on whether a Boolean condition evaluates to true or false.
The syntax of the ternary operator is as follow:
condition ? consequent : alternative;
If the Boolean condition evaluates to true, the consequent expression will be evaluated, and its result returned. Otherwise, the alternative expression will be evaluated, and its result returned. The ternary conditional operator can also be perceived as a shorthand for an if-else statement.
In the following example, the function called max() returns the maximum of two integers. The conditional operator is used to check whether a is greater or equal to b, in which case the value of a is returned; otherwise, the result is the value of b:
static int max(int a, int b)
{
return a >= b ? a : b;
}
There is another form of this operator called conditional ref expression (available since C# 7.2) that allows returning the reference to the result of one of the two expressions. The syntax, in this case, is as follows:
condition ? ref consequent : ref alternative;
The result reference can be assigned to a ref local or ref read-only local variable and uses it as a reference return value or as a ref method parameter. The conditional ref expression requires the type of consequent and alternative to be the same.
In the following example, the conditional ref expression is used to select between two alternatives based on user input. If an even number is introduced, the v variable will hold a reference to a; otherwise, it will hold a reference to b. The value of v is incremented and then a and b are printed to the console:
int a = 42;
int b = 21;
int.TryParse(Console.ReadLine(), out int alt);
ref int v = ref (alt % 2 == 0 ? ref a : ref b);
v++;
Console.WriteLine($"a={a}, b={b}");
While the conditional operator checks whether a condition is true or not, the null-conditional operator checks whether an operand is null or not. We will look at this operator in the next section.
The null-conditional operators
The null-conditional operator has two forms: ?. (also known as the Elvis operator) to apply member access and ?[] to apply element access for an array. These operators apply the operation to their operand if and only if that operand is not null. Otherwise, the result of applying the operator is also null.
The following example shows how to use the null-conditional operator to invoke a method called run() from an instance of a class called foo, through an object that might be null. Notice that the result is a nullable type (int?) because if the operand of ?. is null, then the result of its evaluation is also null:
class foo
{
public int run() { return 42; }
}
foo f = null;
int? i = f?.run()
The null-conditional operators can be chained together. However, if one operator in the chain is evaluated to null, the rest of the chain is short-circuited and does not evaluate.
In the following example, the bar class has a property of the foo type. An array of bar objects is created and we try to retrieve the value from the execution of the run() method from the f property of the first bar element in the array:
class bar
{
public foo f { get; set; }
}
bar[] bars = new bar[] { null };
int? i = bars[0]?.f?.run();
We can avoid the use of a nullable type if we combine the null-conditional operator with the null-coalescing operator and provide a default value in case the null-conditional operator returns null. An example is shown here:
int i = bars[0]?.f?.run() ?? -1;
The null-coalescing operator is discussed in the following section.
The null-coalescing and null-coalescing assignment operators
The null-coalescing operator, denoted by ??, will return the left-hand operand if it is not null; otherwise, it will evaluate the right-hand operand and return its result. The left-hand operand cannot be a non-nullable value type. The right-hand operand is only evaluated if the left-hand operand is null.
The null-coalescing assignment operator, denoted by ??=, is a new operator added in C# 8. It assigns the value of its right-hand operand to its left-hand operand, if and only if the left-hand operand evaluates to null. If the left-hand operand is not null, then the right-hand operand is not evaluated.
Both ?? and ??= are right-associative. That means, the expression a ?? b ?? c is evaluated as a ?? (b ?? c). Similarly, the expression a ??= b ??= c is evaluated as a ??= (b ??= c).
Take a look at the following code snippet:
int? n1 = null; int n2 = n1 ?? 2; // n2 is set to 2 n1 = 5; int n3 = n1 ?? 2; // n3 is set to 5
We have defined a nullable variable, n1, and initialized it to null. The value of n2 will be set to 2 as n1 is null. After assigning n1 a non-null value, we will apply the conditional operator on n1 and integer 2. In this case, since n1 is not null, the value of n3 will be the same as that of n1.
The null-coalescing operator can be used multiple times in an expression. In the following example, the GetDisplayName() function returns the value of name if this is not null; otherwise, it returns the value of email if it is not null; if email is also null, then it returns "unknown":
string GetDisplayName(string name, string email)
{
return name ?? email ?? "unknown";
}
The null-coalescing operator can also be used in argument checking. If a parameter is expected to be non-null, but it is in fact null, you can throw an exception from the right-hand operand. This is shown in the following example:
class foo
{
readonly string text;
public foo(string value)
{
text = value ?? throw new
ArgumentNullException(nameof(value));
}
}
The null-coalescing assignment operator is useful in replacing code that checks whether a variable is null before assigning it with a simpler, more succinct form. Basically, the ??= operator is syntactic sugar for the following code:
if(a is null) a = b;
This can be replaced with a ??= b.
Summary
In this chapter, we learned about built-in data types in C#, which are the numerical types, floating-point types, Boolean and character types, string, and object. Moreover, we also covered nullable types and array types. We learned about variables and constants and looked at the differences between value types and reference types. In addition to this, we covered the concepts of type conversion and casting. At the end of this chapter, we learned about the various types of operators available in C#.
In the next chapter, we will explore control statements and exceptions in C#.
Test what you learned
- What are the integral built-in types in C#?
- What are the differences between the floating-point types and the
decimaltype? - How do you concatenate strings?
- What are escape sequences and how are they related to verbatim strings?
- What is an implicitly typed variable? Can these variables be initialized with
null? - What are value types? What are reference types? What are the main differences between them?
- What are boxing and unboxing?
- What is a nullable type and how do you declare a nullable integer variable?
- How many types of arrays exist and what is the difference between them?
- What are the available type conversions and how do you provide user-defined type conversion?






