There are different aspects of the code that have to be considered when reviewing it. Primarily, the code being reviewed should only be the code that was modified by the programmer and submitted for review. That's why you should aim to make small submissions often. Small amounts of code are much easier to review and comment on.
Let's go through different aspects a code reviewer should assess for a complete and thorough review.
Company's coding guidelines and business requirement(s)
All code being reviewed should be checked against the company's coding guidelines and the business requirement(s) the code is addressing. All new code should adhere to the latest coding standards and best practices employed by the company.
There are different types of business requirements. These requirements include those of the business and the user/stakeholder as well as functional and implementation requirements. Regardless of the type of requirement the code is addressing, it must be fully checked for correctness in meeting requirements.
For example, if the user/stakeholder requirement states that as a user, I want to add a new customer account, does the code under review meet all the conditions set out in this requirement? If the company's coding guidelines stipulate that all code must include unit tests that test the normal flow and exceptional cases, then have all the required tests been implemented? If the answer to any of these questions is no, then the code must be commented on, the comments addressed by the programmer, and the code resubmitted.
Naming conventions
The code should be checked to see whether the naming conventions have been followed for the various code constructs, such as classes, interfaces, member variables, local variables, enumerations, and methods. Nobody likes cryptic names that are hard to decipher, especially if the code base is large.
Here are a couple of questions that a reviewer should ask:
- Are the names long enough to be human-readable and understandable?
- Are they meaningful in relation to the intent of the code, but short enough to not irritate other programmers?
As the reviewer, you must be able to read the code and understand it. If the code is difficult to read and understand, then it really needs to be refactored before being merged.
Formatting
Formatting goes a long way to making code easy to understand. Namespaces, braces, and indentation should be employed according to the guidelines, and the start and end of code blocks should be easily identifiable.
Again, here is a set of questions a reviewer should consider asking in their review:
- Is code to be indented using spaces or tabs?
- Has the correct amount of white space been employed?
- Are there any lines of code that are too long that should be spread over multiple lines?
- What about line breaks?
- Following the style guidelines, is there only one statement per line? Is there only one declaration per line?
- Are continuation lines correctly indented using one tab stop?
- Are methods separated by one line?
- Are multiple clauses that make up a single expression separated by parentheses?
- Are classes and methods clean and small, and do they only do the work they are meant to do?
Testing
Tests must be understandable and cover a good subset of use cases. They must cover the normal paths of execution and exceptional use cases. When it comes to testing the code, the reviewer should check for the following:
- Has the programmer provided tests for all the code?
- Is there any code that is untested?
- Do all the tests work?
- Do any of the tests fail?
- Is there adequate documentation of the code, including comments, documentation comments, tests, and product documentation?
- Do you see anything that stands out that, even if it compiles and works in isolation, could cause bugs when integrated into the system?
- Is the code well documented to aid maintenance and support?
Let's see how the process goes:
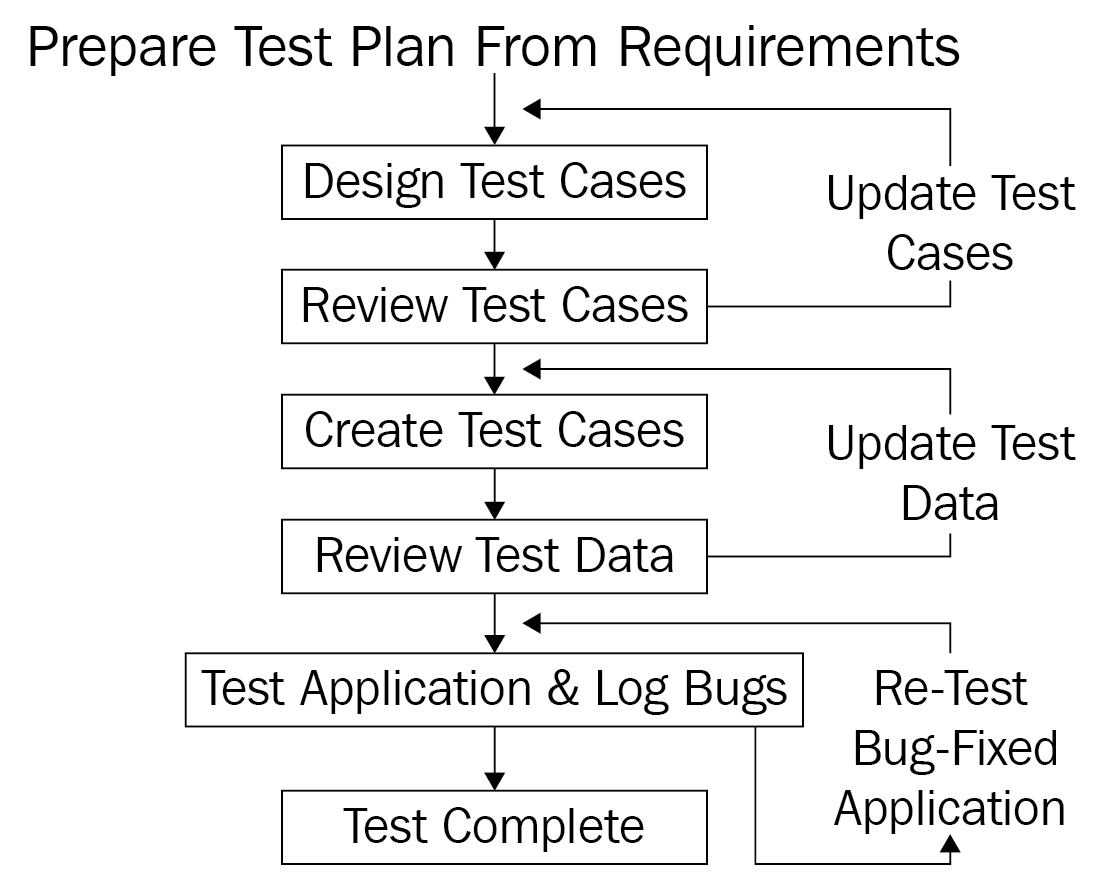
Untested code has the potential to raise unexpected exceptions during testing and production. But just as bad as code that is not tested are tests that are not correct. This can lead to bugs that are hard to diagnose, can be annoying for the customer, and make more work for you further down the line. Bugs are technical debt and looked upon negatively by the business. Moreover, you may have written the code, but others may have to read it as they maintain and extend the project. It is always a good idea to provide some documentation for your colleagues.
Now, concerning the customer, how are they going to know where your features are and how to use them? Good documentation that is user-friendly is a good idea. And remember, not all your users may be technically savvy. So, cater to the less technical person that may need handholding, but do it without being patronizing.
As a technical authority reviewing the code, do you detect any code smells that may become a problem? If so, then you must flag, comment, and reject the pull request and get the programmer to resubmit their work.
As a reviewer, you should check that those exceptions are not used to control the program flow and that any errors raised have meaningful messages that are helpful to developers and to the customers who will receive them.
Architectural guidelines and design patterns
The new code must be checked to see whether it conforms to the architectural guidelines for the project. The code should follow any coding paradigms that the company employs, such as SOLID, DRY, YAGNI, and OOP. In addition, where possible, the code should employ suitable design patterns.
This is where the Gang-of-Four (GoF) patterns come into play. The GOF comprises four authors of a C++ book called Design Patterns: Elements of Reusable Object-Oriented Software. The authors were Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides.
Today, their design patterns are heavily used in most, if not all, object-oriented programming languages. Packt has books that cover design patterns, including .NET Design Patterns, by Praseen Pai and Shine Xavier. Here is a really good resource that I recommend that you visit: https://www.dofactory.com/net/design-patterns. The site covers each of the GoF patterns and provides the definition, UML class diagram, participants, structural code, and some real-world code for the patterns.
GoF patterns consist of creational, structural, and behavioral design patterns. Creational design patterns include Abstract Factory, Builder, Factory Method, Prototype, and Singleton. Structural design patterns include Adapter, Bridge, Composite, Decorator, Façade, Flyweight, and Proxy. Behavioral design patterns include Chain of Responsibility, Command, Interpreter, Iterator, Mediator, Memento, Observer, State, Strategy, Template Method, and Visitor.
The code should also be properly organized and placed in the correct namespace and module. Check the code also to see whether it is too simplistic or over-engineered.
Performance and security
Other things that may need to be considered include performance and security:
- How well does the code perform?
- Are there any bottlenecks that need to be addressed?
- Is the code programmed in such a way to protect against SQL injection attacks and denial-of-service attacks?
- Is code properly validated to keep the data clean so that only valid data gets stored in the database?
- Have you checked the user interface, documentation, and error messages for spelling mistakes?
- Have you encountered any magic numbers or hard coded values?
- Is the configuration data correct?
- Have any secrets accidentally been checked in?
A comprehensive code review will encompass all of the preceding aspects and their respective review parameters. But let's find out when it is actually the right time to even be performing a code review.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand



















