


















 Download code from GitHub
Download code from GitHub
By opening this book, you are taking the first step in disrupting your own knowledge by approaching solutions to complex problems with machine learning. You will be achieving this with the use of Microsoft's ML.NET framework. Having spent several years applying machine learning to cybersecurity, I'm confident that the knowledge you garner from this book will not only open career opportunities to you but also open up your thought processes and change the way you approach problems. No longer will you even approach a complex problem without thinking about how machine learning could possibly solve it.
Over the course of this book, you will learn about the following:
- How and when to use five different algorithms that ML.NET provides
- Real-world end-to-end examples demonstrating ML.NET algorithms
- Best practices when training your models, building your training sets, and feature engineering
- Using pre-trained models in both TensorFlow and ONNX formats
This book does assume that you have a reasonably solid understanding of C#. If you have other experience with a strongly typed object-oriented programming language such as C++ or Java, the syntax and design patterns are similar enough to not hinder your ability to follow the book. However, if this is your first deep dive into a strongly typed language such as C#, I strongly suggest picking up Learn C# in 7 Days, by Gaurav Aroraa, published by Packt Publishing, to get a quick foundation. In addition, no prior machine learning experience is required or expected, although a cursory understanding will accelerate your learning.
In this chapter, we will cover the following:
- The importance of learning about machine learning today
- The model-building process
- Exploring types of learning
- Exploring various machine learning algorithms
- Introduction to ML.NET
By the end of the chapter, you should have a fundamental understanding of what it takes to build a model from start to finish, providing the basis for the remainder of the book.
The importance of learning about machine learning today
In recent years, machine learning and artificial intelligence have become an integral part of many of our lives in use cases as diverse as finding cancer cells in an MRI and facial and object recognition during a professional basketball game. Over the course of just the four years between 2013 and 2017, machine learning patents alone grew 34%, while spending is estimated to grow to $57.6B by 2021 (https://www.forbes.com/sites/louiscolumbus/2018/02/18/roundup-of-machine-learning-forecasts-and-market-estimates-2018/#794d6f6c2225).
Despite its status as a growing technology, the term machine learning was coined back in 1959 by Arthur Samuel—so what caused the 60-year gap before its adoption? Perhaps the two most significant factors were the availability of technology able to process model predictions fast enough, and the amount of data being captured every minute digitally. According to DOMO Inc, a study in 2017 concluded that 2.5 quintillion bytes were generated daily and that at that time, 90% of the world's data was created between 2015 and 2017 (https://www.domo.com/learn/data-never-sleeps-5?aid=ogsm072517_1&sf100871281=1). By 2025, it is estimated that 463 exabytes of data are going to be created daily (https://www.visualcapitalist.com/how-much-data-is-generated-each-day/), much of which will come from cars, videos, pictures, IoT devices, emails, and even devices that have not made the transition to the smart movement yet.
The amount that data has grown in the last decade has led to questions about how a business or corporation can use such data for better sales forecasting, anticipating a customer's needs, or detecting malicious bytes in a file. Traditional statistical approaches could potentially require exponentially more staff to keep up with current demands, let alone scale with the data captured. Take, for instance, Google Maps. With Google's acquisition of Waze in 2013, users of Google Maps have been provided with extremely accurate routing suggestions based on the anonymized GPS data of its users. With this model, the more data points (in this case GPS data from smartphones), the better predictions Google can make for your travel. As we will discuss later in this chapter, quality datasets are a critical component of machine learning, especially in the case of Google Maps, where, without a proper dataset, the user experience would be subpar.
In addition, the speed of computer hardware, specifically specialized hardware tailored for machine learning, has also played a role. The use of Application-Specific Integrated Circuits (ASICs) has grown exponentially. One of the most popular ASICs on the market is the Google Tensor Processing Unit (TPU). Originally released in 2016, it has since gone through two iterations and provides cloud-based acceleration for machine learning tasks on Google Cloud Platform. Other cloud platforms, such as Amazon's AWS and Microsoft's Azure, also provide FPGAs.
Additionally, Graphics Processing Units (GPUs) from both AMD and NVIDIA are accelerating both cloud-based and local workloads, with ROCm Platform and CUDA-accelerated libraries respectively. In addition to accelerated workloads, typical professional GPUs offered by AMD and NVIDIA provide a much higher density of processors than the traditional CPU-only approach. For instance, the AMD Radeon Instinct MI60 provides 4,096 stream processors. While not a full-fledged x86 core, it is not a one-to-one comparison, and the peak performance of double-precision floating-point tasks is rated at 7.373 TFLOPs compared to the 2.3 TFLOPs in AMD's extremely powerful EPYC 7742 server CPU. From a cost and scalability perspective, utilizing GPUs in even a workstation configuration would provide an exponential reduction in training time if the algorithms were accelerated to take advantage of the more specialized cores offered by AMD and NVIDIA. Fortunately, ML.NET provides GPU acceleration with little additional effort.
From a software engineering career perspective, with this growth and demand far outpacing the supply, there has never been a better time to develop machine learning skills as a software engineer. Furthermore, software engineers also possess skills that traditional data scientists do not have – for instance, being able to automate tasks such as the model building process rather than relying on manual scripts. Another example of where a software engineer can provide more value is by adding both unit tests and efficacy tests as part of the full pipeline when training a model. In a large production application, having these automated tests is critical to avoid production issues.
Finally, in 2018, for the first time ever, data was considered more valuable than oil. As industries continue to adopt the use of data gathering and existing industries take advantage of the data they have, machine learning will be intertwined with the data. Machine learning to data is what refining plants are to oil.
The model building process
Before diving into ML.NET, an understanding of core machine learning concepts is required. These concepts will help create a foundation for you to build on as we start building models and learning the various algorithms ML.NET provides over the course of this book. At a high level, producing a model is a complex process; however, it can be broken down into six main steps:

Over the next few sections, we will go through each of these steps in detail to provide you with a clear understanding of how to perform each step and how each step relates to the overall machine learning process as a whole.
Defining your problem statement
Effectively, what problem are you attempting to solve? Being specific at this point is crucial as a less concise problem can lead to considerable re-work. For example, take the following problem statement: Predicting the outcome of an election. My first question upon hearing that problem statement would be, at what level? County, state, or national? Each level more than likely requires considerably more features and data to properly predict than the last. A better problem statement, especially early on in your machine learning journey, would be for a specific position at a county level, such as Predicting the 2020 John Doe County Mayor. With this more direct problem statement, your features and dataset are much more focused and more than likely attainable. Even with more experience in machine learning, proper scoping of your problem statement is critical. The five Ws of Who, What, When, Where, and Why should be followed to keep your statement concise.
Defining your features
The second step in machine learning is defining your features. Think of features as components or attributes of the problem you wish to solve. In machine learning – specifically, when creating a new model – features are one of the biggest impacts on your model's performance. Properly thinking through your problem statement will promote an initial set of features that will drive differentiation between your dataset and model results. Going back to the Mayor example in the preceding section, what features would you consider data points for the citizen? Perhaps start by looking at the Mayor's competition and where he/she sits on issues in ways that differ from other candidates. These values could be turned into features and then made into a poll for citizens of John Doe County to answer. Using these data points would create a solid first pass at features. One aspect here that is also found in model building is running several iterations of feature engineering and model training, especially as your dataset grows. After model evaluation, feature importance is used to determine what features are actually driving your predictions. Occasionally, you will find that gut-instinct features can actually be inconsequential after a few iterations of model training and feature engineering.
In Chapter 11, Training and Building Production Models, we will deep dive into best practices when defining features and common approaches to complex problems to obtain a solid first pass at feature engineering.
Obtaining a dataset
As you can imagine, one of the most important aspects of the model building process is obtaining a high-quality dataset. A dataset is used to train the model on what the output should be in the case of the aforementioned case of supervised learning. In the case of unsupervised learning, labeling is required for the dataset. A common misconception when creating a dataset is that bigger is better. This is far from the truth in a lot of cases. Continuing the preceding example, what if all of the poll results answered the same way for every single question? At that point, your dataset is composed of all the same data points and your model will not be able to properly predict any of the other candidates. This outcome is called overfitting. A diverse but representative dataset is required for machine learning algorithms to properly build a production-ready model.
In Chapter 11, Training and Building Production Models, we will deep dive into the methodology of obtaining quality datasets, looking at helpful resources, ways to manage your datasets, and transforming data, commonly referred to as data wrangling.
Feature extraction and pipeline
Once your features and datasets have been obtained, the next step is to perform feature extraction. Feature extraction, depending on the size of your dataset and your features, could be one of the most time-consuming elements of the model building process.
For example, let's say that the results from the aforementioned fictitious John Doe County Election Poll had 40,000 responses. Each response was stored in a SQL database captured from a web form. Performing a SQL query, let's say you then returned all of the data into a CSV file, using which your model can be trained. At a high level, this is your feature extraction and pipeline. For more complex scenarios, such as predicting malicious web content or image classification, the extraction will include binary extraction of specific bytes in files. Properly storing this data to avoid having to re-run the extraction is crucial to iterating quickly (assuming the features did not change).
In Chapter 11, Training and Building Production Models, we will deep dive into ways to version your feature-extracted data and maintain control over your data, especially as your dataset grows in size.
Model training
After feature extraction, you are now prepared to train your model. Model training with ML.NET, thankfully, is very straightforward. Depending on the amount of data extracted in the feature extraction phase, the complexity of the pipeline, and the specifications of the host machine, this step could take several hours to complete. When your pipeline becomes much larger and your model becomes more complex, you may find yourself requiring potentially more compute resources than your laptop or desktop can provide; tooling such as Spark exists to help you scale to n number of nodes.
In Chapter 11, Training and Building Production Models, we will discuss tooling and tips for scaling this step using an easy-to-use open source project.
Model evaluation
Once the model is trained, the last step is to evaluate the model. The typical approach to model evaluation is to hold out a portion of your dataset for evaluation. The idea behind this is to take known data, submit it to your trained model, and measure the efficacy of your model. The critical part of this step is to hold out a representative dataset of your data. If your holdout set is swayed one way or the other, then you will more than likely get a false sense of either high performance or low performance. In the next chapter, we will deep dive into the various scoring and evaluation metrics. ML.NET provides a relatively easy interface to evaluate a model; however, each algorithm has unique properties to verify, which we will review as we deep dive into the various algorithms.
Exploring types of learning
Now that you understand the steps that make up the model building process, the next major component to introduce is the two main types of learning. There are several other types of machine learning, such as reinforcement learning. However, for the scope of this book, we will focus on the two types used for the algorithms ML.NET provides—supervised learning and unsupervised learning. If you are curious about the other types of learning, check out Machine Learning Algorithms, Giuseppe Bonaccorso, Packt Publishing.
Supervised learning
Supervised learning is the more common of the two types, and, as such, it is also used for most of the algorithms we will cover in this book. Simply put, supervised learning entails you, as the data scientist, passing the known outputs as part of the training to the model. Take, for instance, the election example discussed earlier in this chapter. With supervised learning, every data point in the election polls that is used as a feature along with whom they say will vote for, are sent to the model during training. This step is traditionally called labeling in classification algorithms, in which the output values will be one of the pre-training labels.
Unsupervised learning
Conversely, in unsupervised learning, the typical use case is when figuring out the input and output labels proves to be difficult. Using the election scenario, when you are unsure of what features are really going to provide data points for the model to determine a voter's vote, unsupervised learning could provide value and insight. The benefit of this approach is that the algorithm of your choice determines what features drive your labeling. For instance, using a clustering algorithm such as k-means, you could submit all of the voter data points to the model. The algorithm would then be able to group voter data into clusters and predict unseen data. We will deep dive into unsupervised learning with clustering in Chapter 5, Clustering Model.
Exploring various machine learning algorithms
At the heart of machine learning are the various algorithms used to solve complex problems. As mentioned in the introduction, this book will cover five algorithms:
- Binary classification
- Regression
- Anomaly detection
- Clustering
- Matrix factorization
Each will be the focus of a chapter later in the book, but for now, let's get a quick overview of them.
Binary classification
One of the easiest algorithms to understand is binary classification. Binary classification is a supervised machine learning algorithm. As the name implies, the output of a model trained with a binary classification algorithm will return a true or false conviction (as in 0 or 1). Problems best suited to a binary classification model include determining whether a comment is hateful or whether a file is malicious. ML.NET provides several binary classification model algorithms, which we will cover in Chapter 4, Classification Model, along with a working example of determining whether a file is malicious or not.
Regression
Another powerful yet easy-to-understand algorithm is regression. Regression is another supervised machine learning algorithm. Regression algorithms return a real value as opposed to a binary algorithm or ones that return from a set of specific values. You can think of regression algorithms as an algebra equation solver where there are a number of known values and the goal is to predict the one unknown value. Some examples of problems best suited to regression algorithms are predicting attrition, weather forecasting, stock market predictions, and house pricing, to name a few.
In addition, there is a subset of regression algorithms called logistic regression models. Whereas a traditional linear regression algorithm, as described earlier, returns the predicted value, a logistic regression model will return the probability of the outcome occurring.
ML.NET provides several regression model algorithms, which we will cover in Chapter 3, Regression Model.
Anomaly detection
Anomaly detection, as the name implies, looks for unexpected events in the data submitted to the model. Data for this algorithm, as you can probably guess, requires data over a period of time. Anomaly detection in ML.NET looks at both spikes and change points. Spikes, as the name implies, are temporary, whereas change points are the starting points of a longer change.
ML.NET provides an anomaly detection algorithm, which we will cover in Chapter 6, Anomaly Detection Model.
Clustering
Clustering algorithms are unsupervised algorithms and offer a unique solution to problems where finding the closest match to related items is the desired solution. During the training of the data, the data is grouped based on the features, and then during the prediction, the closest match is chosen. Some examples of the use of clustering algorithms include file type classification and predicting customer choices.
ML.NET uses the k-means algorithm specifically, which we will deep dive into in Chapter 5, Clustering Model.
Matrix factorization
Last but not least, the matrix factorization algorithm provides a powerful and easy-to-use algorithm for providing recommendations. This algorithm is tailored to problems where historical data is available and the problem to solve is predicting a selection from that data, such as movie or music predictions. Netflix's movie suggestion system uses a form of matrix factorization for its suggestions about what movies it thinks you will enjoy.
We will cover matrix factorization in detail in Chapter 7, Matrix Factorization Model.
What is ML.NET?
Now that you have a fairly firm understanding of the core machine learning concepts, we can now dive into Microsoft's ML.NET framework. ML.NET is Microsoft's premier machine learning framework. It provides an easy-to-use framework to train, create, and run models with relative ease all in the confines of the .NET ecosystem.
Microsoft's ML.NET was announced and released (version 0.1) in May 2018 at Microsoft's developer conference BUILD in Seattle, Washington. The project itself is open source with an MIT License on GitHub (https://github.com/dotnet/machinelearning) and has seen a total of 17 updates since the first release at the time of writing.
Some products using ML.NET internally at Microsoft include Chart Decisions in Excel, Slide Designs in PowerPoint, Windows Hello, and Azure Machine Learning. This emphasizes the production-readiness of ML.NET for your own production deployments.
ML.NET, from the outset, was designed and built to facilitate the use of machine learning for C# and F# developers using an architecture that would come naturally to someone familiar with .NET Framework. Until ML.NET arrived, there was not a full-fledged and supported framework where you could not only train but also run a model without leaving the .NET ecosystem. Google's TensorFlow, for instance, has an open-source wrapper written by Miguel de Icaza available on GitHub (https://github.com/migueldeicaza/TensorFlowSharp); however, at the time of writing this book, most workflows require the use of Python to train a model, which can then be consumed by a C# wrapper to run a prediction.
In addition, Microsoft was intent on supporting all of the major platforms .NET developers have grown accustomed to publishing their applications in the last several years. Here are some examples of a few of the platforms, with the frameworks they targeted in parentheses:
- Web (ASP.NET)
- Mobile (Xamarin)
- Desktop (UWP, WPF, and WinForms)
- Gaming (MonoGame and SharpDX)
- IoT (.NET Core and UWP)
Later in this book, we will implement several real-world applications on most of these platforms to demonstrate how to integrate ML.NET into various application types and platforms.
Technical details of ML.NET
With the release of ML.NET 1.4, the targeting of .NET Core 3.0 or later is recommended to take advantage of the hardware intrinsics added as part of .NET Core 3.0. For those unfamiliar, .NET Core 2.x (and earlier) along with .NET Framework are optimized for CPUs with Streaming SIMD Extensions (SSE). Effectively, these instructions provide an optimized path for performing several CPU instructions on a dataset. This approach is referred to as Single Instruction Multiple Data (SIMD). Given that the SSE CPU extensions were first added in the Pentium III back in 1999 and later added by AMD in the Athlon XP in 2001, this has provided an extremely backward-compatible path. However, this also does not allow code to take advantage of all the advancements made in CPU extensions made in the last 20 years. One such advancement is the Advanced Vector Extensions (AVX) available on most Intel and AMD CPUs created in 2011 or later.
This provides eight 32-bit operations in a single instruction, compared to the four SSE provides. As you can probably guess, machine learning can take advantage of this doubling of instructions. For CPUs in .NET Core 3 that are not supported yet (such as ARM), .NET Core 3 automatically falls back to a software-based implementation.
Components of ML.NET
As mentioned previously, ML.NET was designed to be intuitive for experienced .NET developers. The architecture and components are very similar to the patterns found in ASP.NET and WPF.
At the heart of ML.NET is the MLContext object. Similar to AppContext in a .NET application, MLContext is a singleton class. The MLContext object itself provides access to all of the trainer catalogs ML.NET offers (some are offered by additional NuGet packages). You can think of a trainer catalog in ML.NET as a specific algorithm such as binary classification or clustering.
Here are some of the ML.NET catalogs:
- Anomaly detection
- Binary classification
- Clustering
- Forecasting
- Regression
- Time series
These six groups of algorithms were reviewed earlier in this chapter and will be covered in more detail in subsequent dedicated chapters in this book.
In addition, added recently in ML.NET 1.4 was the ability to import data directly from a database. This feature, while in preview at the time of writing, can facilitate not only an easier feature extraction process, but also expands the possibilities of making real-time predictions in an existing application or pipeline possible. All major databases are supported, including SQL Server, Oracle, SQLite, PostgreSQL, MySQL, DB2, and Azure SQL. We will explore this feature in Chapter 4, Classification Model, with a console application using a SQLite database.
The following diagram presents the high-level architecture of ML.NET:
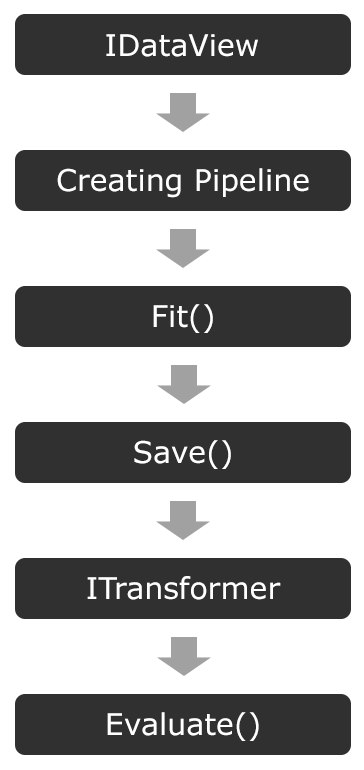
Here, you can see an almost exact match to the traditional machine learning process. This was intentionally done to reduce the learning curve for those familiar with other frameworks. Each step in the architecture can be summarized as follows:
- IDataView: This is used to store the loaded training data into memory.
- Creating a Pipeline: The pipeline creation maps the IDataView object properties to values to send to the model for training.
- Fit(): Regardless of the algorithm, after the pipeline has been created, calling Fit() kicks off the actual model training.
- Save(): As the name implies, this saves the model (in a binary format) to a file.
- ITransformer: This loads the model back into memory to run predictions.
- Evaluate(): As the name implies, this evaluates the model (Chapter 2, Setting Up the ML.NET Environment will dive further into the evaluation architecture).
Over the course of this book, we will dive into these methods more thoroughly.
Extensibility of ML.NET
Lastly, ML.NET, like most robust frameworks, provides considerable extensibility. Microsoft has since launched added extensibility support to be able to run the following externally trained model types, among others:
- TensorFlow
- ONNX
- Infer.Net
- CNTK
TensorFlow (https://www.tensorflow.org/), as mentioned previously, is Google's machine learning framework with officially supported bindings for C++, Go, Java, and JavaScript. Additionally, TensorFlow can be accelerated with GPUs and, as previously mentioned, Google's own TPUs. In addition, like ML.NET, it offers the ability to run predictions on a wide variety of platforms, including iOS, Android, macOS, ARM, Linux, and Windows. Google provides several pre-trained models. One of the more popular models is the image classification model, which classifies objects in a submitted image. Recent improvements in ML.NET have enabled you to create your own image classifier based on that pre-trained model. We will be covering this scenario in detail in Chapter 12, Using TensorFlow with ML.NET.
ONNX (https://onnx.ai/), an acronym for Open Neural Network Exchange Format, is a widely used format in the data science field due to the ability to export to a common format. ONNX has converters for XGBoost, TensorFlow, scikit-learn, LibSVM, and CoreML, to name a few. Microsoft's native support of the ONNX format in ML.NET will not only allow better extensibility with existing machine learning pipelines but also increase the adoption of ML.NET in the machine learning world. We will utilize a pre-trained ONNX format model in Chapter 13, Using ONNX with ML.NET.
Infer.Net is another open source Microsoft machine learning framework that focuses on probabilistic programming. You might be wondering what probabilistic programming is. At a high level, probabilistic programming handles the grey area where traditional variable types are definite, such as Booleans or integers. Probabilistic programming uses random variables that have a range of values that the result could be, akin to an array. The difference between a regular array and the variables in probabilistic programming is that for every value, there is a probability that the specific value would occur.
A great real-world use of Infer.Net is the technology behind Microsoft's TrueSkill. TrueSkill is a rating system that powers the matchmaking in Halo and Gears of War, where players are matched based on a multitude of variables, play types, and also, maps can all be attributed to how even two players are. While outside the scope of this book, a great whitepaper diving further into Infer.Net and probabilistic programming, in general, can be found here: https://dotnet.github.io/infer/InferNet_Intro.pdf.
CNTK, also from Microsoft, which is short for Cognitive Toolkit, is a deep learning toolkit with a focus on neural networks. One of the unique features of CNTK is its use of describing neural networks via a directed graph. While outside the scope of this book (we will cover neural networks in Chapter 12 with TensorFlow), the world of feed-forward Deep Neural Networks, Convolutional Neural Networks, and Recurrent Neural Networks is extremely fascinating. To dive further into neural networks specifically, I would suggest Hands-On Neural Network Programming with C#, also from Packt.
Additional extensibility into Azure and other model support such as PyTorch (https://pytorch.org/) is on the roadmap, but no timeline has been established at the time of writing.
Summary
In this chapter, you have learned the importance of discovering machine learning. In addition, you have also learned the core concepts of machine learning, including the differences in learning and the various algorithms we will cover later in this book. You have also received an introduction to ML.NET. The core concepts in this chapter are the foundation for the rest of the book and we will be building on them with each subsequent chapter. In the next chapter, we will be setting up your environment and training your first model in ML.NET!






