


Common data structures in R
Data structures provide an organized way to store various data points that follow either the same or different types. This section will look at the typical data structures used in R, including the vector, matrix, data frame, and list.
Vector
A vector is a one-dimensional array that can hold a series of elements of any consistent data type, including numeric, integer, character, logical, or factor. We can create a vector by filling in comma-separated elements in the input argument of the combine function, c(). The arithmetic operations between two vectors are similar to the single-element example earlier, provided that their lengths are equal. There needs to be a one-to-one correspondence between the elements of the two vectors; if not, the calculation may give an error. Let’s look at an exercise.
Exercise 1.04 – working with vectors
We will create two vectors of the same length in this exercise and add them up. As an extension, we will also attempt the same addition using a vector of a different length. We will also perform a pairwise comparison between the two vectors:
- Create two vectors named
vec_aandvec_band extract simple summary statistics such asmeanandsum:>>> vec_a = c(1,2,3) >>> vec_b = c(1,1,1) >>> sum(vec_a) 6 >>> mean(vec_a) 2
The sum and mean of a vector can be generated using the
sum()andmean()function, respectively. We will cover more ways to summarize a vector later. - Add up
vec_aandvec_b:>>> vec_a + vec_b 2 3 4
The addition between two vectors is performed element-wise. The result can also be saved into another variable for further processing. How about adding a single element to a vector?
- Add
vec_aand1:>>> vec_a + 1 2 3 4
Under the hood, element one is broadcasted into vector
c(1,1,1), whose length is decided byvec_a. Broadcasting is a unique mechanism that replicates the elements of the short vector into the required length, as long as the length of the longer vector is a multiple of the short vector’s length. The same trick may not apply when it is not a multiple. - Add
vec_aandc(1,1):>>> vec_a + c(1,1) 2 3 4 Warning message: In vec_a + c(1, 1) : longer object length is not a multiple of shorter object length
We still get the same result, except for a warning message saying that the longer vector’s length of three is not a multiple of the shorter vector length of two. Pay attention to this warning message. It is not recommended to follow such practice as the warning may become an explicit error or become the implicit cause of an underlying bug in an extensive program.
- Next, we will perform a pairwise comparison between the two vectors:
vec_a > vec_b FALSE TRUE TRUE vec_a == vec_b TRUE FALSE FALSE
Here, we have used evaluation operators such as
>(greater than) and==(equal to), returning logical results (TRUEorFALSE) for each pair.Note, there are multiple logical comparison operators in R. The common ones include the following:
<for less than<=for less than or equal to>for greater than>=for greater than or equal to==for equal to!=for not equal to
Besides the common arithmetic operations, we may also be interested in selected partial components of a vector. We can use square brackets to select specific elements of a vector, which is the same way to select elements in other data structures such as in a matrix or a data frame. In between the square brackets are indices indicating what elements to select. For example, we can use vec_a[1] to select the first element of vec_a. Let’s go through an exercise to look at different ways to subset a vector.
Exercise 1.05 – subsetting a vector
We can pass in the select index (starting from 1) to select the corresponding element in the vector. We can wrap the indices via the c() combine function and pass in the square brackets to select multiple elements. Selecting multiple sequential indices can also be achieved via a shorthand notation by writing the first and last index with a colon in between. Let’s run through different ways of subsetting a vector:
- Select the first element in
vec_a:>>> vec_a[1] 1
- Select the first and third elements in
vec_a:>>> vec_a[c(1,3)] 1 3
- Select all three elements in
vec_a:>>> vec_a[c(1,2,3)] 1 2 3
Selecting multiple elements in this way is not very convenient since we need to type every index. When the indices are sequential, a nice shorthand trick is to use the starting and end index separated by a colon. For example,
1:3would be the same asc(1,2,3):>>> vec_a[1:3] 1 2 3
We can also perform more complex subsetting by adding a conditional statement within the square brackets as the selection criteria. For example, the logical evaluation introduced earlier returns either
TrueorFalse. An element whose index is marked astruein the square bracket would be selected. Let’s see an example. - Select elements in
vec_athat are bigger than the corresponding elements invec_b:>>> vec_a[vec_a > vec_b] 2 3
The result contains the last two elements since only the second and third indices are set as
true.
Matrix
Like a vector, a matrix is a two-dimensional array consisting of a collection of elements of the same data type arranged in a fixed number of rows and columns. It is often faster to work with a data structure exclusively containing the same data type since the program does not need to differentiate between different types of data. This makes the matrix a popular data structure in scientific computing, especially in an optimization procedure that involves intensive computation. Let’s get familiar with the matrix, including different ways to create, index, subset, and enlarge a matrix.
Exercise 1.06 – creating a matrix
The standard way to create a matrix in R is to call the matrix() function, where we need to supply three input arguments:
- The elements to be filled in the matrix
- The number of rows in the matrix
- The filling direction (either by row or by column)
We will also rename the rows and columns of the matrix:
- Use
vec_aandvec_bto create a matrix calledmtx_a:>>> mtx_a = matrix(c(vec_a,vec_b), nrow=2, byrow=TRUE) >>> mtx_a [,1] [,2] [,3] [1,] 1 2 3 [2,] 1 1 1
First, the input vectors,
vec_aandvec_b, are combined via thec()function to form a long vector, which then gets sequentially arranged into two rows (nrow=2) row-wise (byrow=TRUE). Feel free to try out different dimension configurations, such as setting three rows and two columns when creating the matrix.Pay attention to the row and column names in the output. The rows are indexed by the first index in the square bracket, while the second indexes the columns. We can also rename the matrix as follows.
- Rename the matrix
mtx_avia therownames()andcolnames()functions:>>> rownames(mtx_a) = c("r1", "r2") >>> colnames(mtx_a) = c("c1", "c2", "c3") >>> mtx_a c1 c2 c3 r1 1 2 3 r2 1 1 1
Let’s look at how to select elements from the matrix.
Exercise 1.07 – subsetting a matrix
We can still use the square brackets to select one or more matrix elements. The colon shorthand trick also applies to matrix subsetting:
- Select the element at the first row and second column of the
mtx_amatrix:>>> mtx_a[1,2] 2
- Select all elements of the last two columns across all rows in the
mtx_amatrix:>>> mtx_a[1:2,c(2,3)] c2 c3 r1 2 3 r2 1 1
- Select all elements of the second row of the
mtx_amatrix:>>> mtx_a[2,] c1 c2 c3 1 1 1
In this example, we have used the fact that the second (column-level) index indicates that all columns are selected when left blank. The same applies to the first (row-level) index as well.
We can also select the second row using the row name:
>>> mtx_a[rownames(mtx_a)=="r2",] c1 c2 c3 1 1
Selecting elements by matching the row name using a conditional evaluation statement offers a more precise way of subsetting the matrix, especially when counting the exact index becomes troublesome. Name-based indexing also applies to columns.
- Select the third row of the
mtx_amatrix:>>> mtx_a[,3] r1 r2 3 1 >>> mtx_a[,colnames(mtx_a)=="c3"] r1 r2 3 1
Therefore, we have multiple ways to select the specific elements of interest from a matrix.
Working with a matrix requires similar arithmetic operations compared to a vector. In the next exercise, we will look at summarizing a matrix both row-wise and column-wise and performing basic operations such as addition and multiplication.
Exercise 1.08 – arithmetic operations with a matrix
Let’s start by making a new matrix:
- Create another matrix named
mtx_bwhose elements are double those inmtx_a:>>> mtx_b = mtx_a * 2 >>> mtx_b c1 c2 c3 r1 2 4 6 r2 2 2 2
Besides multiplication, all standard arithmetic operators (such as
+,-, and/) apply in a similar element-wise fashion to a matrix, backed by the same broadcasting mechanism. Operations between two matrices of the same size are also performed element-wise. - Divide
mtx_abymtx_b:>>> mtx_a / mtx_b c1 c2 c3 r1 0.5 0.5 0.5 r2 0.5 0.5 0.5
- Calculate the row-wise and column-wise sum and mean of
mtx_ausingrowSums(),colSums(),rowMeans(), andcolMeans()respectively:>>> rowSums(mtx_a) r1 r2 6 3 >>> colSums(mtx_a) c1 c2 c3 2 3 4 >>> rowMeans(mtx_a) r1 r2 2 1 >>> colMeans(mtx_a) c1 c2 c3 1.0 1.5 2.0
When running an optimizing procedure, we often need to save some intermediate metrics, such as model loss and accuracy, for diagnosis. These metrics can be saved in a matrix form by gradually appending new data to the current matrix. Let’s look at how to expand a matrix both row-wise and column-wise.
Exercise 1.09 – expanding a matrix
Adding a column or multiple columns to a matrix can be achieved via the cbind() function, which merges a new matrix or vector column-wise. Similarly, an additional matrix or vector can be concatenated row-wise via the rbind() function:
- Append
mtx_btomtx_acolumn-wise:>>> cbind(mtx_a, mtx_b) c1 c2 c3 c1 c2 c3 r1 1 2 3 2 4 6 r2 1 1 1 2 2 2
We may need to rename the columns since some of them overlap. This also applies to the row-wise concatenation as follows.
- Append
mtx_btomtx_arow-wise:>>> rbind(mtx_a, mtx_b) c1 c2 c3 r1 1 2 3 r2 1 1 1 r1 2 4 6 r2 2 2 2
So, we’ve seen the matrix in operation. How about data frames next?
Data frame
A data frame is a standard data structure where variables are stored as columns and observations as rows in an object. It is an advanced version of a matrix in that the elements for each column can be of different data types.
The R engine comes with several default datasets stored as data frames. In the next exercise, we will look at different ways to examine and understand the structure of a data frame.
Exercise 1.10 – understanding data frames
The data frame is a famous data structure representing rectangular-shaped data similar to Excel. Let’s examine a default dataset in R as an example:
- Load the
irisdataset:>>> data("iris") >>> dim(iris) 150 5Checking the dimension using the
dim()function suggests that theirisdataset contains 150 rows and five columns. We can initially understand its contents by looking at the first and last few observations (rows) in the dataset. - Examine the first and last five rows using
head()andtail():>>> head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa >>> tail(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 145 6.7 3.3 5.7 2.5 virginica 146 6.7 3.0 5.2 2.3 virginica 147 6.3 2.5 5.0 1.9 virginica 148 6.5 3.0 5.2 2.0 virginica 149 6.2 3.4 5.4 2.3 virginica 150 5.9 3.0 5.1 1.8 virginica
Note that the row names are sequentially indexed by integers starting from one by default. The first four columns are numeric, and the last is a character (or factor). We can look at the structure of the data frame more systematically.
- Examine the structure of the
irisdataset usingstr():>>> str(iris) 'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
The
str()function summarizes the data frame structure, including the total number of observations and variables, the complete list of variable names, data type, and the first few observations. The number of categories (levels) is also shown if the column is a factor.We can also create a data frame by passing in vectors as columns of the same length to the
data.frame()function. - Create a data frame called
df_awith two columns that correspond tovec_aandvec_brespectively:>>> df_a = data.frame("a"=vec_a, "b"=vec_b) >>> df_a a b 1 1 1 2 2 1 3 3 1
Selecting the elements of a data frame can be done in a similar fashion to matrix selection. Other functions such as subset() make the selection more flexible. Let’s go through an example.
Exercise 1.11 – selecting elements in a data frame
In this exercise, we will first look at different ways to select a particular set of elements and then introduce the subset() function to perform customized conditional selection:
- Select the second column of the
df_adata frame:>>> df_a[,2] 1 1 1
The row-level indexing is left blank to indicate that all rows will be selected. We can also make it explicit by referencing all row-level indices:
>>> df_a[1:3,2] 1 1 1
We can also select by using the name of the second column as follows:
>>> df_a[,"b"] 1 1 1
Alternatively, we can use the shortcut
$sign to reference the column name directly:>>> df_a$b 1 1 1
The
subset()function provides an easy and structured way to perform row-level filtering and column-level selection. Let’s see how it works in practice. - Select the rows of
df_awhere columnais greater than two:>>> subset(df_a, a>2) a b 3 3 1
Note that row index three is also shown as part of the output.
We can directly use column
awithin the context of thesubset()function, saving us from using the$sign instead. We can also select the column by passing the column name to theselectargument. - Select column
bwhere columnais greater than two indf_a:>>> subset(df_a, a>2, select="b") b 3 1
Another typical operation in data analysis is sorting one or more variables of a data frame. Let’s see how it works in R.
Exercise 1.12 – sorting vectors and data frames
The order() function can be used to return the ranked position of the elements in the input vector, which can then be used to sort the elements via updated indexing:
- Create the
c(5,1,10)vector invec_cand sort it in ascending order:>>> vec_c = c(5,1,10) >>> order(vec_c) 2 1 3 >>> vec_c[order(vec_c)] 1 5 10
Since the smallest element in
vec_cis1, the corresponding ranked position is1. Similarly,5is set as the second rank and10as the third and highest rank. The ranked positions are then used to reshuffle and sort the original vector, the same as how we would select its elements via positional indexing.The
order()function ranks the elements in ascending order by default. What if we want to sort by descending order? We could simply add a minus sign to the input vector. - Sort the
df_adata frame by columnain descending order:>>> df_a[order(-df_a$a),] a b 3 3 1 2 2 1 1 1 1
Data frames will be the primary structures we will work with in this book. Let’s look at the last and most complex data structure: list.
List
A list is a flexible data structure that can hold different data types (numeric, integer, character, logical, factor, or even list itself), each possibly having a different length. It is the most complex structure we have introduced so far, gathering various objects in a structured way. To recap, let’s compare the four data structures in terms of the contents, data type, and length in Figure 1.8. In general, all four structures can store elements of any data type. Vectors (one-dimensional array) and matrices (two-dimensional array) require the contents to be homogeneous data types. A data frame contains one or more vectors whose data types could differ, and a list could contain entries of different data types. Matrices and data frames follows a rectangular shape and so require the same length for each column. However, the entries in a list could be of arbitrary lengths (subject to memory constraint) different from each other.
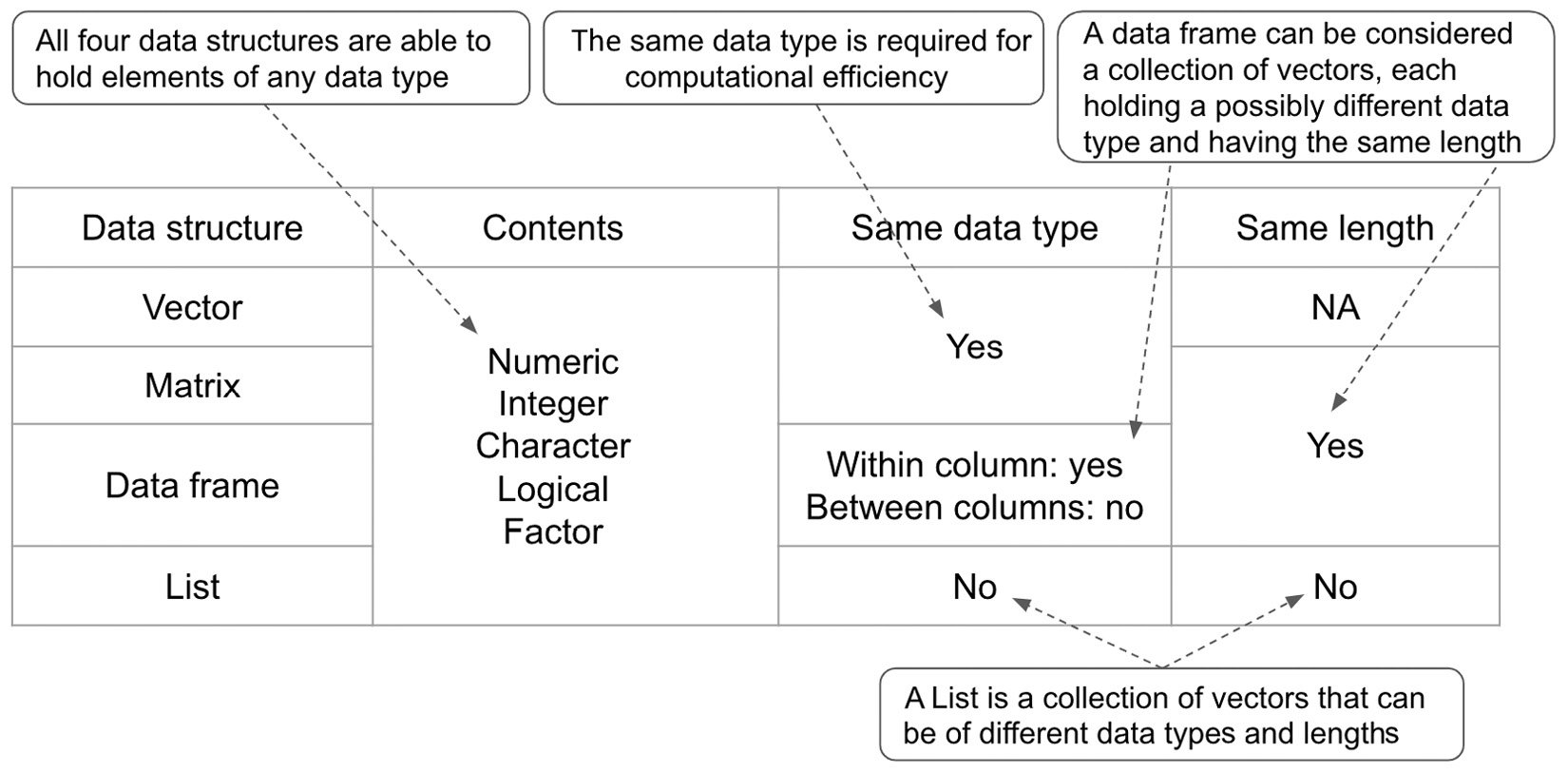
Figure 1.8 – Comparing four different data structures in terms of contents, data type, and length
Let’s look at how to create a list.
Exercise 1.13 – creating a list
In this exercise, we will go through different ways to manipulate a list, including creating and renaming a list, and accessing, adding, and removing elements in a list:
- Create a list using the previous
a,vec_a, anddf_avariables:>>> ls_a = list(a, vec_a, df_a) >>> ls_a [[1]] [1] 1 [[2]] [1] 1 2 3 [[3]] a b 1 1 1 2 2 1 3 3 1
The output shows that the list elements are indexed by double square brackets, which can be used to access the entries in the list.
- Access the second entry in the list,
ls_a:>>> ls_a[[2]] 1 2 3
The default indices can also be renamed to enable entry selection by name.
- Rename the list based on the original names and access the
vec_avariable:>>> names(ls_a) <- c("a", "vec_a", "df_a") ls_a $a [1] 1 $vec_a [1] 1 2 3 $df_a a b 1 1 1 2 2 1 3 3 1 >>> ls_a[['vec_a']] 1 2 3 >>> ls_a$vec_a 1 2 3We can access a specific entry in the list by using the name either in square brackets or via the
$sign. - Add a new entry named
new_entrywith the content"test"in thels_alist:>>> ls_a[['new_entry']] = "test" >>> ls_a $a [1] 1 $vec_a [1] 1 2 3 $df_a a b 1 1 1 2 2 1 3 3 1 $new_entry [1] "test"
The result shows that
"test"is now added to the last entry ofls_a. We can also remove a specific entry by assigningNULLto it. - Remove the entry named
df_ainls_a:>>> ls_a[['df_a']] = NULL >>> ls_a $a [1] 1 $vec_a [1] 1 2 3 $new_entry [1] "test"
The entry named
df_ais now successfully removed from the list. We can also update an existing entry in the list. - Update the entry named
vec_ato bec(1,2):>>> ls_a[['vec_a']] = c(1,2) >>> ls_a $a [1] 1 $vec_a [1] 1 2 $new_entry [1] "test"
The entry named
vec_ais now successfully updated.
The flexibility and scalability of the list structure make it a popular choice for storing heterogeneous data elements, similar to the dictionary in Python. In the next section, we will extend our knowledge base by going over the control logic in R, which gives us more flexibility and precision when writing long programs.