he goal of tree-based methods is to segment the feature space into a number of simple rectangular regions, to subsequently make a prediction for a given observation based on either mean or mode (mean for regression and mode for classification, to be precise) of the training observations in the region to which it belongs. Unlike most other classifiers, models produced by decision trees are easy to interpret. In this chapter, we will be covering the following decision tree-based models on HR data examples for predicting whether a given employee will leave the organization in the near future or not. In this chapter, we will learn the following topics:
- Decision trees - simple model and model with class weight tuning
- Bagging (bootstrap aggregation)
- Random Ffrest - basic random forest and application of grid search on hypyerparameter tuning
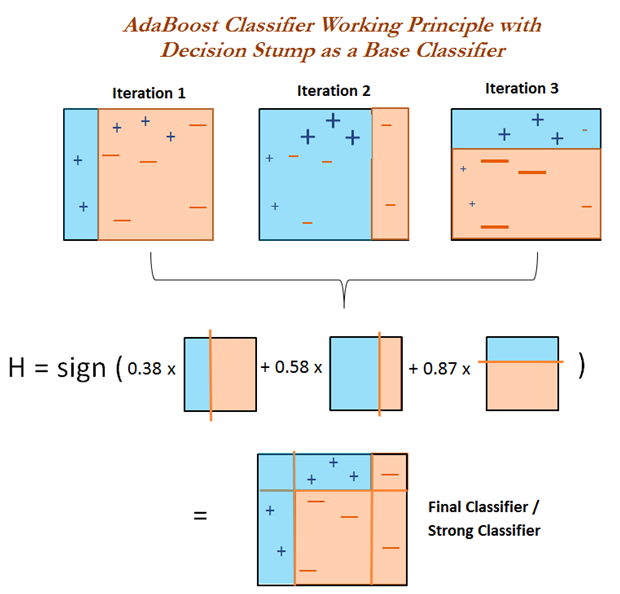
- Boosting (AdaBoost, gradient boost, extreme gradient boost - XGBoost)
- Ensemble of ensembles (with heterogeneous and...