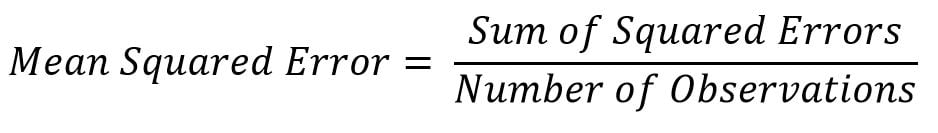Chapter 7. Recommendation Engines
Recommendation engines (REs) are most famously used for explaining what machine learning is to any unknown person or a newbie who wants to understand the field of machine learning. A classic example could be how Amazon recommends books similar to the ones you have bought, which you may also like very much! Also, empirically, the recommender engine seems to be an example of large-scale machine learning that everyone understands, or perhaps already understood. But, nonetheless, recommendation engines are being used everywhere. For example, the people you may know feature in Facebook or LinkedIn, which recommends by showing the most probable people you might like to befriend or professionals in your network who you might be interested in connecting with. Of course, these features drive their businesses big time and it is at the heart of the company's driving force.
The idea behind an RE is to predict what people might like and to uncover relationships between...
Content-based methods try to use the content or attributes of the item, together with some notion of similarity between two pieces of content, to generate similar items with respect to the given item. In this case, cosine similarity is used to determine the nearest user or item to provide recommendations.
Example: If you buy a book, then there is a high chance you'll buy related books which have frequently gone together with all the other customers, and so on.
As we will be working on this concept, it would be nice to reiterate the basics. Cosine similarity is a measure of similarity between two nonzero vectors of an inner product space that measures the cosine of the angle between them. Cosine of 00 is 1 and it is less than 1 for any other angle:
Here, Ai and Bi are components of vector A and B respectively:
Example: Let us assume A = [2, 1, 0, 2, 0, 1, 1, 1], B = [2, 1, 1, 1, 1, 0, 1, 1] are the two vectors and we would like to calculate the cosine...
Collaborative filtering is a form of wisdom-of-the-crowd approach, where the set of preferences of many users with respect to items is used to generate estimated preferences of users for items with which they have not yet rated/reviewed. It works on the notion of similarity. Collaborative filtering is a methodology in which similar users and their ratings are determined not by similar age and so on, but by similar preferences exhibited by users, such as similar movies watched, rated, and so on.
Advantages of collaborative filtering over content-based filtering
Collaborative filtering provides many advantages over content-based filtering. A few of them are as follows:
- Not required to understand item content: The content of the items does not necessarily tell the whole story, such as movie type/genre, and so on.
- No item cold-start problem: Even when no information on an item is available, we still can predict the item rating without waiting for a user to purchase it.
- Captures...
Evaluation of recommendation engine model
Evaluation of any model needs to be calculated in order to determine how good the model is with respect to the actual data so that its performance can be improved by tuning hyperparameters and so on. In fact, the entire machine learning algorithm's accuracy is measured based on its type of problem. In the case of classification problems, confusion matrix, whereas in regression problems, mean squared error or adjusted R-squared values need to be computed.
Mean squared error is a direct measure of the reconstruction error of the original sparse user-item matrix (also called A) with two low-dimensional dense matrices (X and Y). It is also the objective function which is being minimized across the iterations:
Root mean squared errors provide the dimension equivalent to the original dimension of the variable measure, hence we can analyze how much magnitude the error component has with the original value. In our example, we have computed the root mean square...