


Types of data processing – OLTP and OLAP
Traditionally, data storage systems have been classified as Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP). OLTP systems are responsible for day-to-day business executions. For instance, when you call your phone carrier’s customer service to add a new value pack to your phone plan, the customer service agent quickly pulls up the account information for your phone number and adds your desired value pack. The system that’s used by the customer service agent is designed to be fast so that the customer wait time can be minimized, which allows the customer service agent to be more efficient and serve customers faster. The system is also designed so that it updates the data quickly so that a large number of concurrent transactions can be processed. This allows the customer service agent to confirm that the value pack has been successfully applied to the account. Other examples include banking and shopping applications.
These faster updates are achieved by using a normalized data model. Normalization is the process of structuring the dataset as per a set of normal-forms to reduce redundancy and enhance data integrity. The normalized data model ensures that you don’t update multiple tables with the same information for a user operation. This is done by reducing the redundancy of the data in these systems. For example, if a customer updates their preferred_name, we can make this change in one table; the rest of the dependent tables will use customer_id to fetch updated information. So, a typical SQL query for the CRM application that’s used by the customer service agent contains the customer_id = 'xxxxxx' expression or data_plan_id = 'xxxxxx' in the WHERE clause.
These OLTP systems are not designed for obtaining or analyzing trends – for example, a query for gathering the mobile data usage (volume) of all customers over the last 2 years. Such queries involve joining a lot of tables on the OLTP side because of normalizations and usually results in poor performance as the amount of data scales up.
This problem can be solved by using OLAP systems. OLAP systems typically use the data warehouse of an organization, where they are utilized for executing complex queries over a large amount of data. They generally store historical datasets.
So, while both OLAP and OLTP have different ways of storing data and are designed for different use cases, the data on which they operate can be the same – the data is just modeled differently. Since both systems work on the same data, the data must be moved from one system to another. OLTP systems support live business transactions, so data generally originates there. This data is then brought into a data warehouse through an Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT) tool so that it can then be consumed by OLAP systems. The following table explains the differences between OLTP and OLAP:
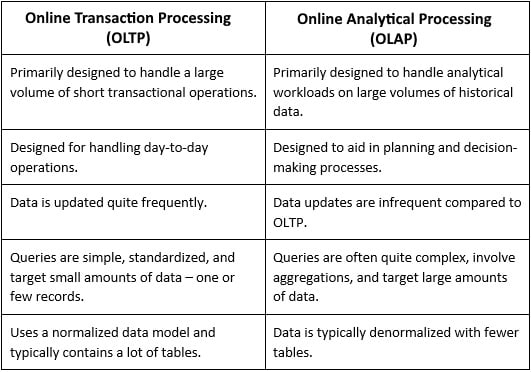
Table 1.1 – Differences between OLTP and OLAP
Now that we understand the fundamentals of the OLTP and OLAP models, let’s explore different data management systems, such as data warehouses, data marts, data lakes, data lakehouses, and data meshes.