


In this recipe, we are going to solve the continuous Mountain Car problem using the advantage actor-critic algorithm, a continuous version this time of course. You will see how it differs from the discrete version.
As we have seen in A2C for environments with discrete actions, we sample actions based on the estimated probabilities. How can we model a continuous control, since we can't do such sampling for countless continuous actions? We can actually resort to Gaussian distribution. We can assume that the action values are under a Gaussian distribution:

Here, the mean, 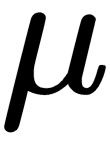 , and deviation,
, and deviation,  , are computed from the policy network. With this tweak, we can sample actions from the constructed Gaussian distribution by current mean and deviation. The loss function in continuous A2C is similar to...
, are computed from the policy network. With this tweak, we can sample actions from the constructed Gaussian distribution by current mean and deviation. The loss function in continuous A2C is similar to...