





















































In this chapter, we will focus on policy gradient methods as one of the most popular reinforcement learning techniques over recent years. We will start with implementing the fundamental REINFORCE algorithm and will proceed with an improvement algorithm baseline. We will also implement a more powerful algorithm, actor-critic, and its variations, and apply it to solve the CartPole and Cliff Walking problems. We will also experience an environment with continuous action space and resort to Gaussian distribution to solve it. By way of a fun section at the end, we will train an agent based on the cross-entropy method to play the CartPole game.
The following recipes will be covered in this chapter:
- Implementing the REINFORCE algorithm
- Developing the REINFORCE algorithm with baseline
- Implementing the actor-critic algorithm
- Solving...


 is the return, which is the cumulative discounted reward until time, t...
is the return, which is the cumulative discounted reward until time, t...



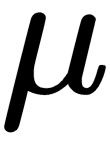 , and deviation,
, and deviation,  , are computed from the policy network. With this tweak, we can sample actions from the constructed Gaussian distribution by current mean and deviation. The loss function in continuous A2C is similar to...
, are computed from the policy network. With this tweak, we can sample actions from the constructed Gaussian distribution by current mean and deviation. The loss function in continuous A2C is similar to...


















