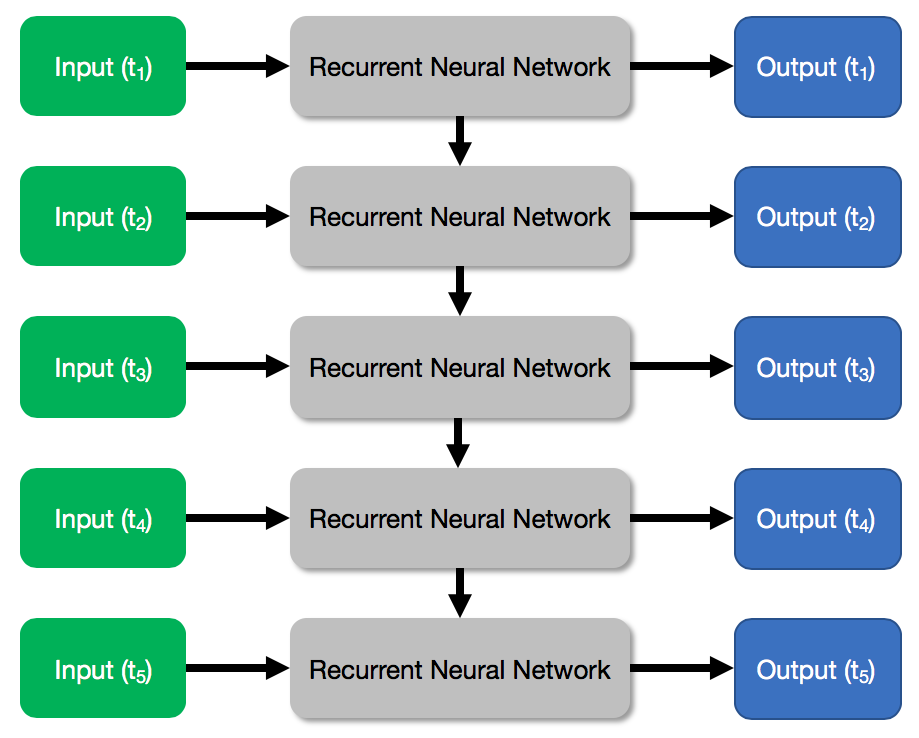
In previous chapters, we looked at neural network architectures, such as the basic MLP and feedforward neural networks, for classification and regression tasks. We then looked at CNNs, and we saw how they are used for image recognition tasks. In this chapter, we will turn our attention to recurrent neural networks (RNNs) (in particular, to long short-term memory (LSTM) networks) and how they can be used in sequential problems, such as Natural Language Processing (NLP). We will develop and train a LSTM network to predict the sentiment of movie reviews on IMDb.
In this chapter, we'll cover the following topics:
- Sequential problems in machine learning
- NLP and sentiment analysis
- Introduction to RNNs and LSTM networks
- Analysis of the IMDb movie reviews dataset
- Word embeddings
- A step-by-step guide to building and training an LSTM...