


Traditional data platforms
Before we get into architecting data platforms in a modern way, it is important to understand the traditional data platforms and know their strengths and limitations. Once we understand the challenges of traditional data platforms in solving new business use cases, we can design a modern data platform in a holistic matter.
Three-tier architecture
Throughout the 1980s and 1990s, the three-tier architecture became a popular way of producing, processing, and storing data. Almost every organization used this pattern as it met the business needs with ease. The three tiers of this architecture were the presentation tier, the application tier, and the data tier:
- The presentation tier was the front-facing module and was created either as a thick client – that is, software was installed on the client’s local machine – or as a thin client – that is, a browser-based application.
- The application tier would receive the data from the presentation tier and process this data with business logic hosted on the application server.
- The data tier was the final resting place for the business data. The data tier was typically a relational database where data was stored in rows and columns of tables.
Figure 00.2 represents a typical three-tier architecture:

Figure 00.2 – A traditional three-tier architecture pattern
This three-tier architecture worked well to meet the transactional nature of businesses. To a certain extent, this system was able to help with creating a basic reporting mechanism to help organizations understand what was happening with their business. But the kind of technology used in this architecture fell short of going a step further – to identify and understand why certain things were happening with their business. So, a new architecture pattern was required that could decouple this transitional system from the analytics type of operations. This paved the way for the creation of an enterprise data warehouse (EDW).
Enterprise data warehouse (EDW)
The need for a data warehouse came from the realistic expectations of organizations to derive business intelligence out of the data they were collecting so that they could get better insights from this data and make the necessary adjustments to their business practices. For example, if a retailer is seeing a steady decline in sales from a particular region, they would want to understand what is contributing to this decline.
Now, let’s capture the data flow. All the transactional data is captured by the presentation tier, processed by the application tier, and stored in the data tier of the three-tier architecture. The database behind the data tier is always online and optimized for processing a large number of transactions, which come in the form of INSERT, UPDATE, and DELETE statements. This database also emphasizes fast query processing while maintaining atomicity, consistency, isolation, and durability (ACID) compliance. For this reason, this type of data store is called OLTP.
To further analyze this data, a path needs to be created that will bring the relevant data over from the OLTP system into the data warehouse. This is where the extract, transform, and load (ETL) layer comes into the picture. And once the data has been brought over to the data warehouse, organizations can create the business intelligence (BI) they need via the reporting and dashboarding capabilities provided by the visualization tier. We will cover the ETL and BI layers in detail in later chapters, but the focus right now is walking through the process and the history behind them.
The data warehouse system is distinctly different from the transactional database system. Firstly, the data warehouse does not constantly get bombarded by transactional data from customer-facing applications. Secondly, the types of operations that are happening in the data warehouse system are specific to mining information insights from all the data, including historical data. Therefore, this system is constantly doing operations such as data aggregation, roll-ups (data consolidation), drill-downs, and slicing and dicing the data. For this reason, the data warehouse is called OLAP.
The following figure shows the OLTP and OLAP systems working together:

Figure 00.3 – The OLTP and OLAP systems working together
The preceding diagram shows all the pieces together. This architectural pattern is still relevant and works great in many cases. However, in the era of cloud computing, business use cases are also rapidly evolving. In the following sections, we will take a look at variations of this design pattern, as well as their advantages and shortcomings.
Bottom-up data warehouse approach
Ralph Kimball, one of the original architects of data warehousing, proposed the idea of designing the data warehouse with a bottom-up approach. This involved creating many smaller purpose-built data marts inside a data warehouse. A data mart is a subset of the larger data warehouse with a focus on catering to use cases for a specific line of business (LOB) or a specific team. All of these data marts can be combined to form an enterprise-wide data warehouse. The design of data marts is also kept simple by having the data model as a star schema to a large extent. A star schema keeps the data in sets of denormalized tables. There are known as fact tables, and they store all the transactional and event data. Since these tables store all the fast-moving granular data, they accumulate a large number of records over a short period. Then, there are the dimension tables, which typically store characteristics data such as details about people and organizations, product information, geographical information, and so forth. Since such information doesn’t rapidly get produced or changed over a short period, compared to fact tables, dimension tables are relatively smaller in terms of the number of records stored. The following figure shows a bottom-up EDW design approach where individual data marts contribute toward a bigger data warehouse:
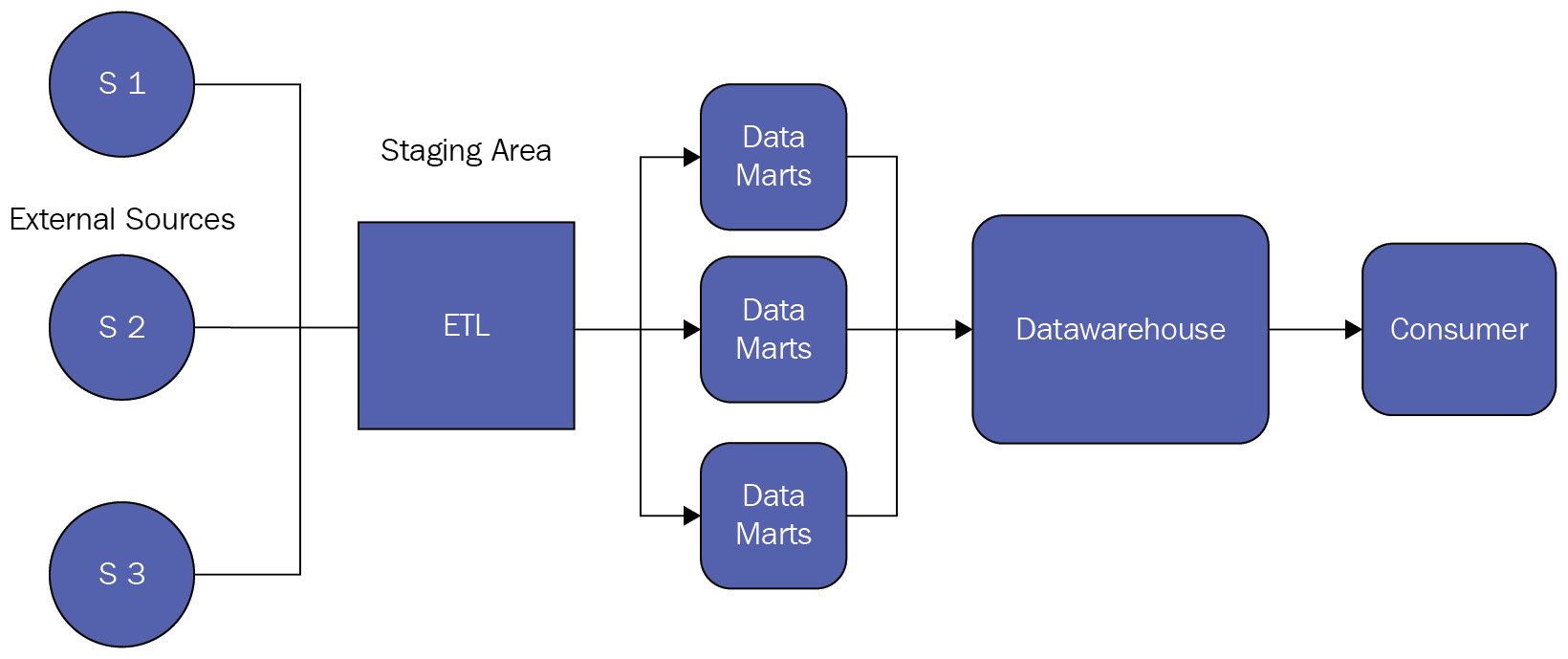
Figure 00.4 – Bottom-up EDW design
Benefits of the bottom-up approach
Let’s look at a few benefits of the bottom-up approach:
- The EDW gets systemically built over a certain period with business-specific groupings of data marts.
- The data model’s design is typically created via star schemas, which makes the model denormalized in nature. Some data becomes redundant in this approach but overall, it helps in making the data marts perform better.
- An EDW is easier to create since the time taken to set up individual business-specific data marts is shorter compared to setting up an enterprise-wide warehouse.
- An EDW that contains data marts also makes it better suited for setting up data lakes. We will cover everything about data lakes in subsequent chapters.
Shortcomings of the bottom-up approach
Now, let’s look at the shortcomings of the bottom-up approach:
- It is challenging to achieve a fully harmonized integration layer because the EDW is purpose-built for each use case in the form of data marts. Data redundancy also makes it difficult to create a single source of truth.
- Normalized schemas create data redundancy, which makes the tables grow very large. This slows down the performance of ETL job pipelines.
- Since the data marts are tightly coupled to the specific business use cases, managing structural changes and their dependencies on the data warehouse becomes a cumbersome process.
Top-down data warehouse approach
Bill Inmon, widely recognized as the father of data warehouses, proposed the idea of designing the data warehouse with a top-down approach. In this approach, a single source of truth for the data in the form of an EDW is constructed first using a normalized data model to reduce data redundancy. Data from different sources is mapped to a single data model, which means that all the source elements are transformed and formatted to fit in this enterprise-wide structure that’s created in the data warehouse. The following figure shows a top-down EDW design approach where the warehouse is built first before smaller data marts are created for consumers:
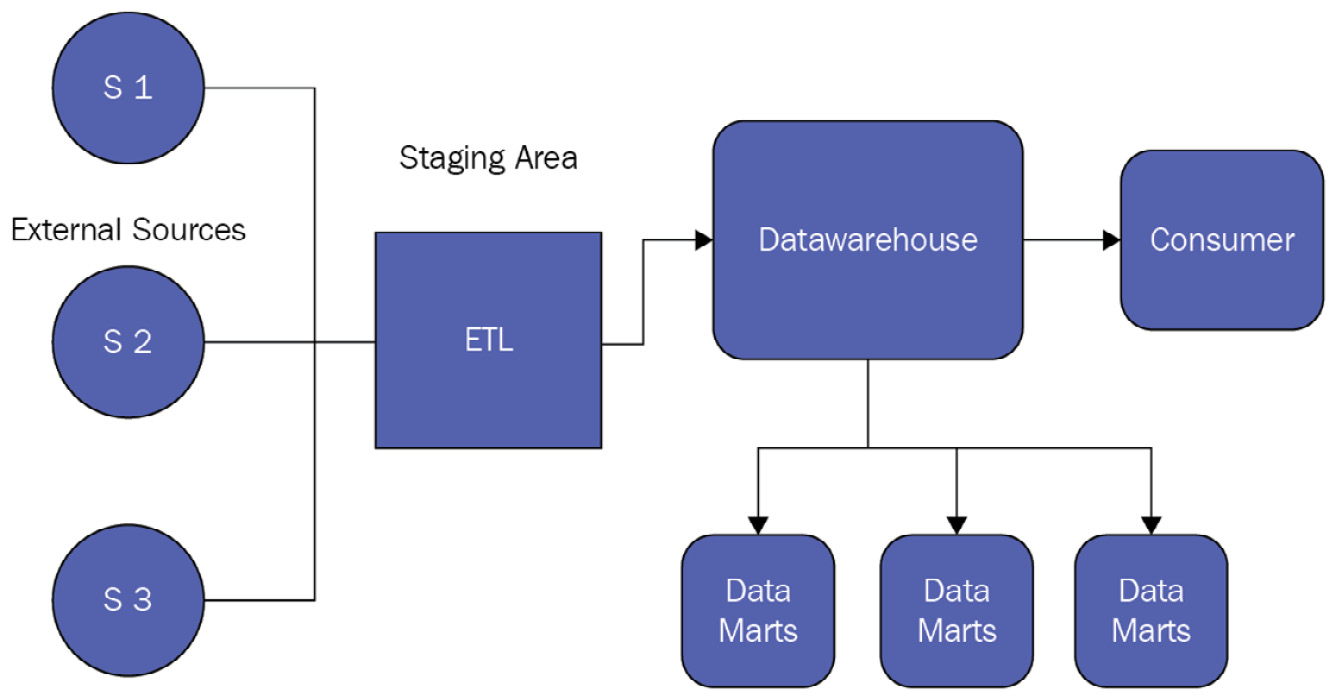
Figure 00.5 – Top-down EDW design
Benefits of the top-down approach
Let’s look at a few benefits of the top-down approach:
- The data model is highly normalized, which reduces data redundancy
- Since it’s not tied to a specific LOB or use case, the data warehouse can evolve independently at an enterprise level
- It provides flexibility for any business requirement changes or data structure updates
- ETL pipelines are simpler to create and maintain
Shortcomings of the top-down approach
Now, let’s look at the shortcomings of the top-down approach:
- A normalized data model increases the complexity of schema design
- A large number of joins on the normalized tables can make the system compute-intensive and expensive over time
- Additional logic is required to create a business-specific data consumption layer, which means additional ETL processes are needed to create data marts from the unified EDW