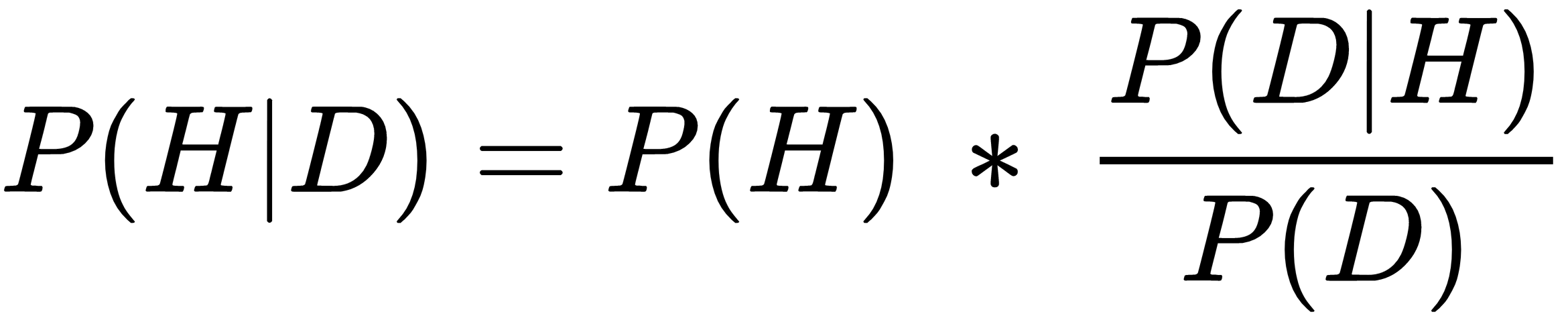In this chapter, we take a brief tour of an alternative approach to statistical inference called Bayesian statistics. It is not intended to be a full primer, but will simply serve as an introduction to the Bayesian approach. We will also explore the associated Python-related libraries and learn how to use pandas and matplotlib to help with the data analysis. The various topics that will be discussed are as follows:
- Introduction to Bayesian statistics
- The mathematical framework for Bayesian statistics
- Probability distributions
- Bayesian versus frequentist statistics
- Introduction to PyMC and Monte Carlo simulations
- Bayesian analysis example – switchpoint detection