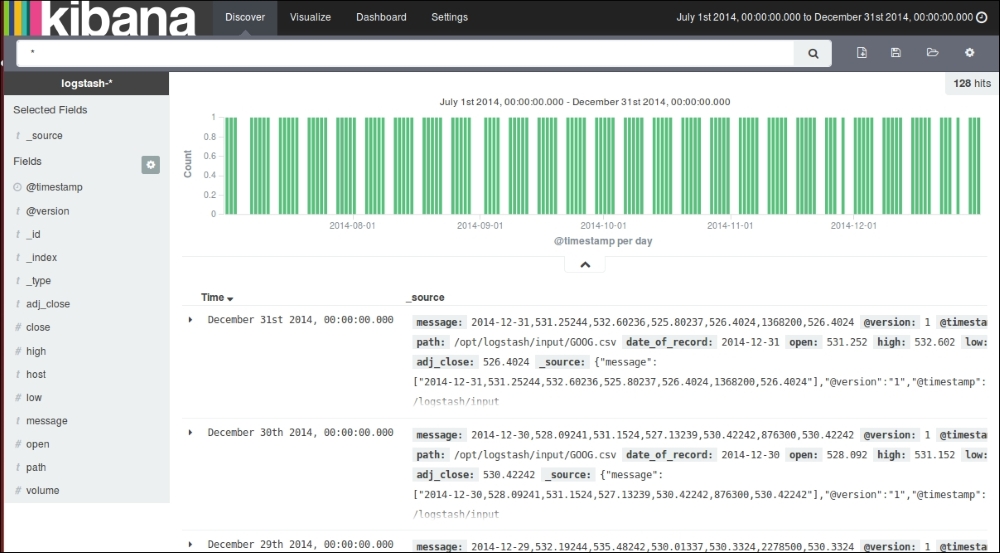
In the previous chapter, we got familiar with each component of ELK Stack—Elasticsearch, Logstash, and Kibana. We got the components installed and configured. In this chapter, we will build our first basic data pipeline using ELK Stack. This will help us understand how easy it is to get together the components of ELK Stack to build an end-to-end analytics pipeline.
While running the example in this chapter, we assume that you already installed Elasticsearch, Logstash, and Kibana as described in Chapter 1, Introduction to ELK Stack.