


- Meta learning produces a versatile AI model that can learn to perform various tasks without having to be trained from scratch. We train our meta learning model on various related tasks with a few data points, so for a new but related task, the model can make use of what it learned from the previous tasks without having to be trained from scratch.
- Learning from fewer data points is called few-shot learning or k-shot learning, where k denotes the number of data points in each of the classes in the dataset.
- In order to make our model learn from a few data points, we will train it in the same way. So, when we have a dataset D, we sample some data points from each of the classes present in our dataset and we call it the support set.
- We sample different data points from each of the classes that differ from the support set and call it the query set.
- In a metric-based meta learning setting, we will learn the appropriate metric space. Let's say we want to find out the similarities between two images. In a metric-based setting, we use a simple neural network, which extracts the features from the two images and finds the similarities by computing the distance between the features of those two images.
- We train our model in an episodic fashion; that is, in each episode, we sample a few data points from our dataset D, and prepare our support set and learn on the support set. So, over a series of episodes, our model will learn how to learn from a smaller dataset.
- A siamese network is a special type of neural network, and it is one of the simplest and most commonly used one-shot learning algorithms. Siamese networks basically consist of two symmetrical neural networks that share the same weights and architecture and are joined together at the end using an energy function, E.
- The contrastive loss function can be expressed as follows:

In the preceding equation, the value of Y is the true label, which will be 1 when the two input values are similar and 0 if the two input values are dissimilar, and E is our energy function, which can be any distance measure. The term margin is used to hold the constraint; that is, when two input values are dissimilar and if their distance is greater than a margin, then they do not incur a loss.
The energy function tells us how similar the two inputs are. It is basically any similarity measure, such as Euclidean distance and cosine similarity.
The input to the siamese networks should be in pairs, (X1,X2), along with their binary label, Y ∈ (0, 1),stating whether the input pairs are genuine pairs (the same) orimposite pairs (different).
The applications of siamese networks are endless; they've been stacked with various architectures for performing various tasks, such as human action recognition, scene change detection, and machine translation.
- Prototypical networks are simple, efficient, and one of the most popularly used few-shot learning algorithms. The basic idea of the prototypical network is to create a prototypical representation of each class and classify a query point (new point) based on the distance between the class prototype and the query point.
- We compute embeddings for each of the data points to learn the features.
- Once we learn the embeddings of each data point, we take the mean embeddings of data points in each class and form the class prototype. So, a class prototype is basically the mean embeddings of data points in a class.
- In a Gaussian prototypical network, along with generating embeddings for the data points, we add a confidence region around them, which is characterized by a Gaussian covariance matrix. Having a confidence region helps to characterize the quality of individual data points, and it is useful with noisy and less homogeneous data.
- Gaussian prototypical networks differ from vanilla prototypical networks in that in a vanilla prototypical network, we learn only the embeddings of a data point, but in a Gaussian prototypical network, along with learning embeddings, we also add a confidence region to them.
- The radius and diagonal are the different components of the covariance matrix used in a Gaussian prototypical network.
- A relation network consists of two important functions: the embedding function, denoted by , and the relation function, denoted by
 .
.
- Once we have the feature vectors of the support set, , and query set,
 , we combine them using an operator,
, we combine them using an operator, . Here,
. Here, can be any combination operator; we use concatenation as an operator to combine the feature vectors of the support set and the query set—that is,
can be any combination operator; we use concatenation as an operator to combine the feature vectors of the support set and the query set—that is, .
.
- The relation function, , will generate a relation score ranging from 0 to 1, representing the similarity between samples in the support set,
 , and samples in the query set,
, and samples in the query set, .
.
Our loss function can be represented as follows:

- In matching networks, we use two embedding functions, and
 , to learn the embeddings of the query set
, to learn the embeddings of the query set and the support set
and the support set , respectively.
, respectively.
The output,
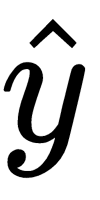
, for the query point,

, can be predicted as follows:
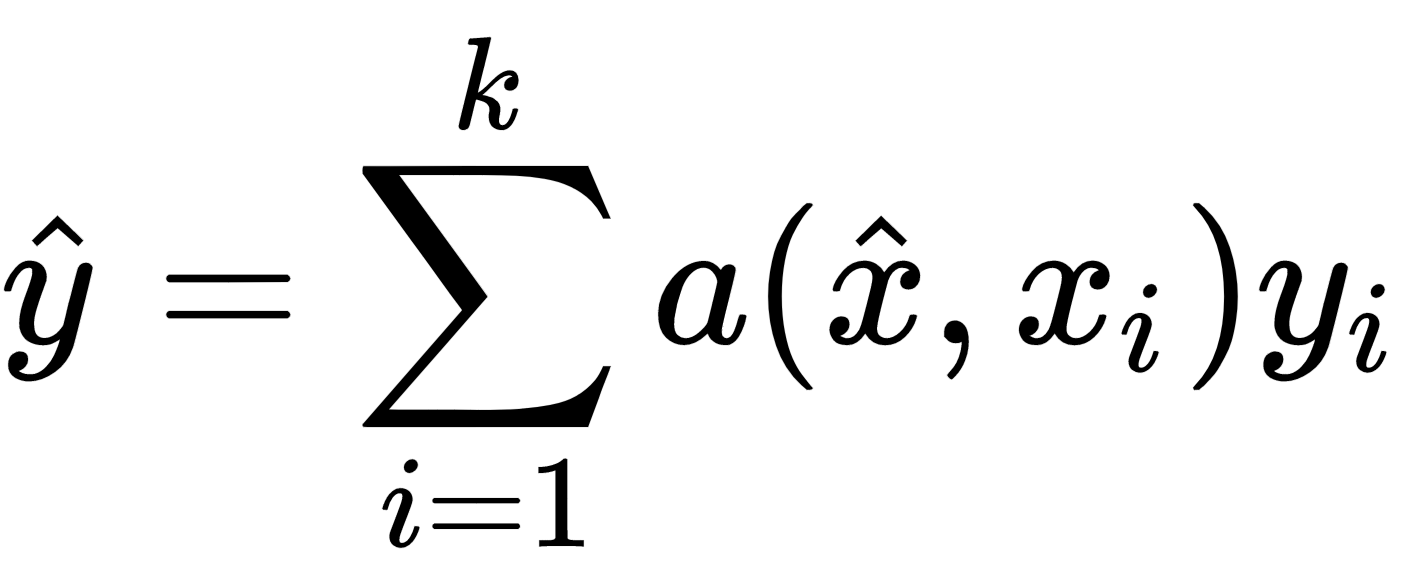
- NTM is an interesting algorithm that has the ability to store and retrieve information from memory. The idea of NTM is to augment the neural network with external memory—that is, instead of using hidden states as memory, it uses external memory to store and retrieve information.
- The controller is basically a feed-forward neural network or recurrent neural network. It reads from and writes to memory.
- The read head and write head are the pointers containing addresses of the memory that it has to read from and write to.
- The memory matrix or memory bank, or simply the memory, is where we will store the information. Memory is basically a two-dimensional matrix composed of memory cells. The memory matrix contains N rows and M columns. Using the controller, we access the content from the memory. So, the controller receives input from the external environment and emits the response by interacting with the memory matrix.
- Location-based addressing and content-based addressing are the different types of addressing mechanisms used in NTM.
- An interpolation gate is used to decide whether we should use the weights we obtained at the previous time step,, or use the weights obtained through content-based addressing,
 .
.
- Computing the least-used weight vector, , from the usage weight vector,
 , is very simple. We simply set the index of the lowest value usage weight vector to 1 and the rest of the values to 0, as the lowest value in the usage weight vector means that it is least recently used.
, is very simple. We simply set the index of the lowest value usage weight vector to 1 and the rest of the values to 0, as the lowest value in the usage weight vector means that it is least recently used.
- MAML is one of the recently introduced and most commonly used meta learning algorithms, and it has lead to a major breakthrough in meta learning research. The basic idea of MAML is to find better initial parameters so that, with good initial parameters, the model can learn quickly on new tasks with fewer gradient steps.
- MAML is model agnostic, meaning that we can apply MAML for any models that are trainable with gradient descent.
- ADML is a variant of MAML that makes use of both clean and adversarial samples to find the better and robust initial model parameter, θ.
- In FGSM, we get the adversarial sample of our image and we calculate the gradients of our loss with respect to our image, more clearly input pixels of our image instead of the model parameter.
- The context parameter is a task-specific parameter that's updated on the inner loop. It is denoted by ∅ and it is specific to each task and represents the embeddings of an individual task.
- The shared parameter is shared across tasks and updated in the outer loop to find the optimal model parameter. It is denoted by θ.
- Unlike MAML, in Meta-SGD, along with finding optimal parameter value, , we also find the optimal learning rate,
 , and update the direction.
, and update the direction.
- The learning rate is implicitly implemented in the adaptation term. So, in Meta-SGD, we don't initialize a learning rate with a small scalar value. Instead, we initialize them with random values with the same shape as and learn them along with
 .
.
- The update equation of the learning rate can be expressed as .

- Sample n tasks and run SGD for fewer iterations on each of the sampled tasks, and then update our model parameter in a direction that is common to all the tasks.
- The reptile update equation can be expressed as .

- When the gradients of all tasks are in the same direction, then it is called gradient agreement, and when the gradient of some tasks differ greatly from others, then it is called gradient disagreement.
- The update equation in gradient agreement can be expressed as .

- Weights are proportional to the inner product of the gradients of a task and the average of gradients of all of the tasks in the sampled batch of tasks.
The weights are calculated as follows:

- The normalization factor is proportional to the inner product of and
 .
.
- If the gradient of a task is in the same direction as the average gradient of all tasks in a sampled batch of tasks, then we can increase its weights so that it'll contribute more when updating our model parameter. Similarly, if the gradient of a task is in the direction that's greatly different from the average gradient of all tasks in a sampled batch of tasks, then we can decrease its weights so that it'll contribute less when updating our model parameter.
- Different types of inequality measures are Gini coefficients, the Theil index, and the variance of algorithms.
- The Theil index is the most commonly used inequality measure. It's named after a Dutch econometrician, Henri Theil, and it's a special case of the family of inequality measures called generalized entropy measures. It can be defined as the difference between the maximum entropy and observed entropy.
- If we enable our robot to learn by just looking at our actions, then we can easily make the robot learn complex goals efficiently and we don't have to engineer complex goal and reward functions. This type of learning—that is, learning from human actions—is called imitation learning, where the robot tries to mimic human action.
- A concept generator is used to extract features. We can use deep neural nets that are parameterized by some parameter, , to generate the concepts. For examples, our concept generator can be a CNN if our input is an image.

We sample a batch of tasks from the task distributions, learn their concepts via the concept generator, perform meta learning on those concepts, and then we compute the meta learning loss:
