


In this chapter, we will talk about another application of HMMs known as Markov Decision Process (MDP). In the case of MDPs, we introduce a reward to our model, and any sequence of states taken by the process results in a specific reward. We will also introduce the concept of discounts, which will allow us to control how short-sighted or far-sighted we want our agent to be. The goal of the agent would be to maximize the total reward that it can get.
In this chapter, we will be covering the following topics:
- Reinforcement learning
- The Markov reward process
- Markov decision processes
- Code example
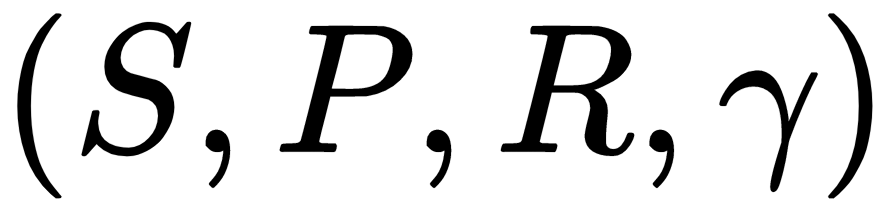 where S is a finite state space, P is the state transition probability function, R is a reward function, and
where S is a finite state space, P is the state transition probability function, R is a reward function, and 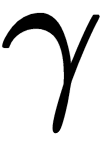 is the discount rate:
is the discount rate: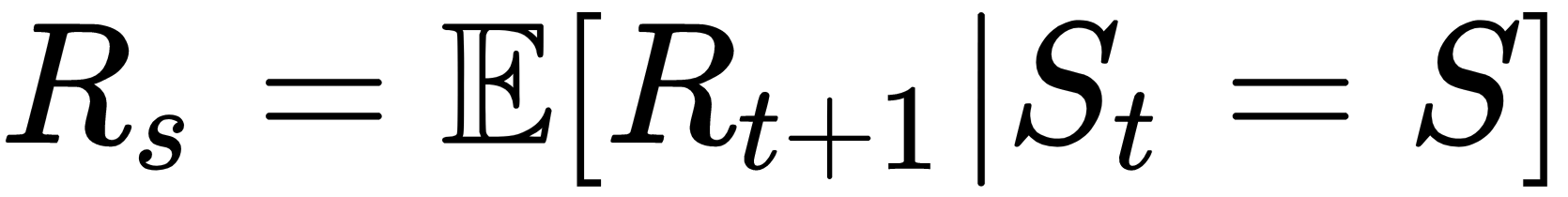
 denotes the expectation. And the term Rs here denotes the expected reward at the state s.
denotes the expectation. And the term Rs here denotes the expected reward at the state s.