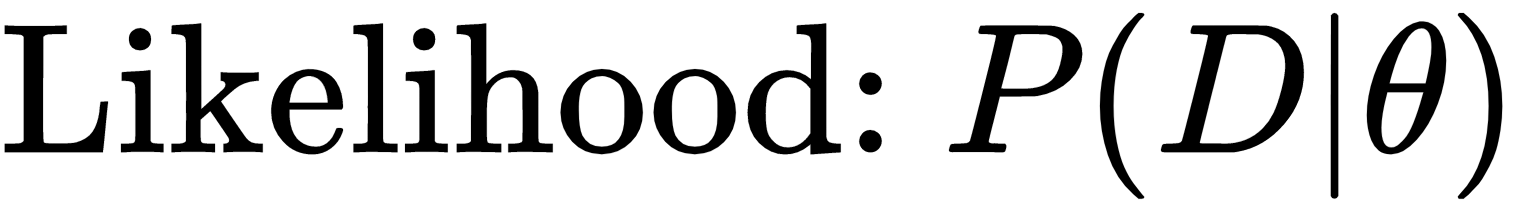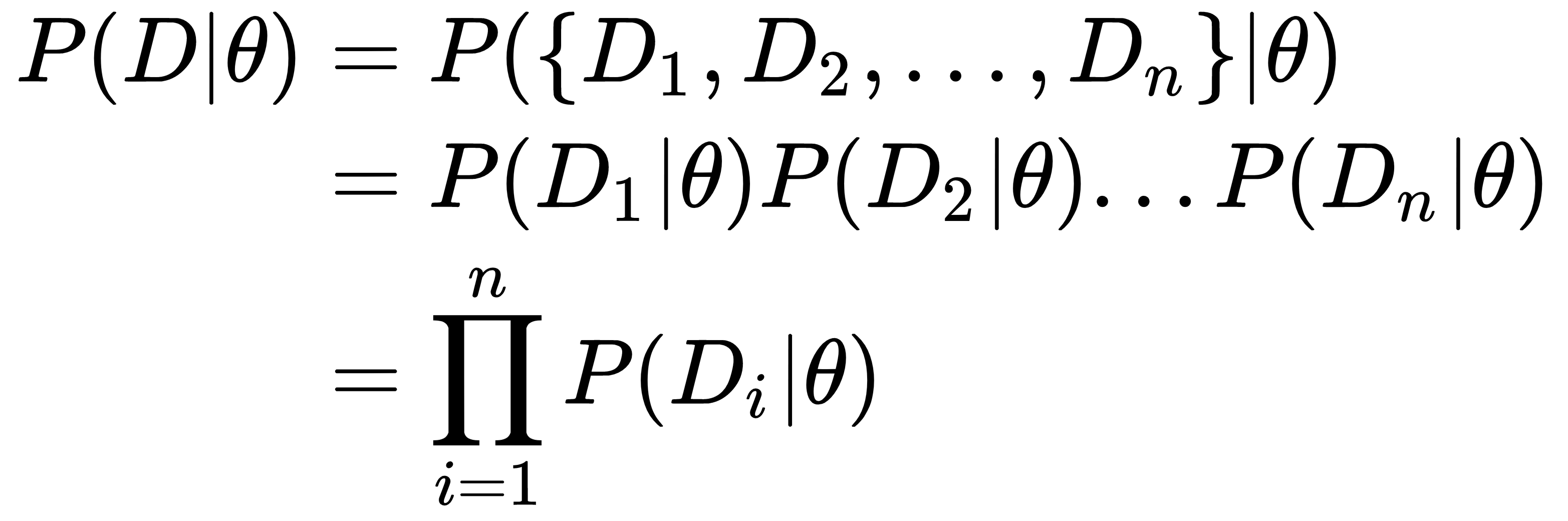In the previous chapter, we discussed the state inference in the case of a Hidden Markov Model (HMM). We tried to predict the next state for an HMM using the information of previous state transitions. But in each cases, we had assumed that we already knew the transition and emission probabilities of the model. But in real-life problems, we usually need to learn these parameters from our observations.
In this chapter, we will try to estimate the parameters of our HMM model through data gathered from observations. We will be covering the following topics:
- Maximum likelihood learning, with examples
- Maximum likelihood learning in HMMs
- Expectation maximization algorithms
- The Baum-Welch algorithm