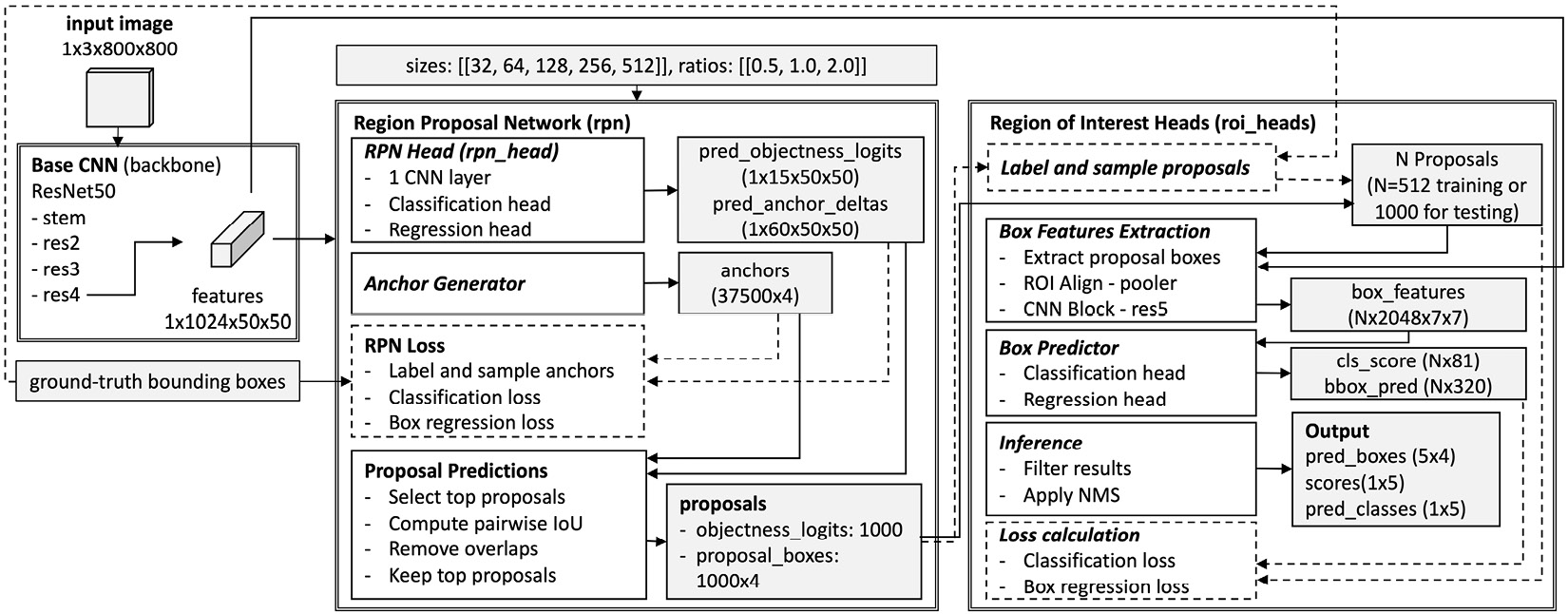
Training Instance Segmentation Models
This chapter provides you with common tools for collecting and labeling images for object instance segmentation tasks. Additionally, it covers the steps to extract data from different sources and reconstruct a dataset in the format supported by Detectron2. Before training an object segmentation model, this chapter also utilizes the code and visualizations approach to explain the architecture of an object segmentation application developed using Detectron2.
By the end of this chapter, you will understand different techniques to collect and label data for training models with object instance segmentation tasks. You will have hands-on experience constructing a custom dataset by extracting data from a nonstandard format and reconstructing it in the format supported by Detectron2 for object detection. Additionally, you will have profound knowledge about the architecture and hands-on experience of training an object instance segmentation application...