The Architecture of the Object Detection Model in Detectron2
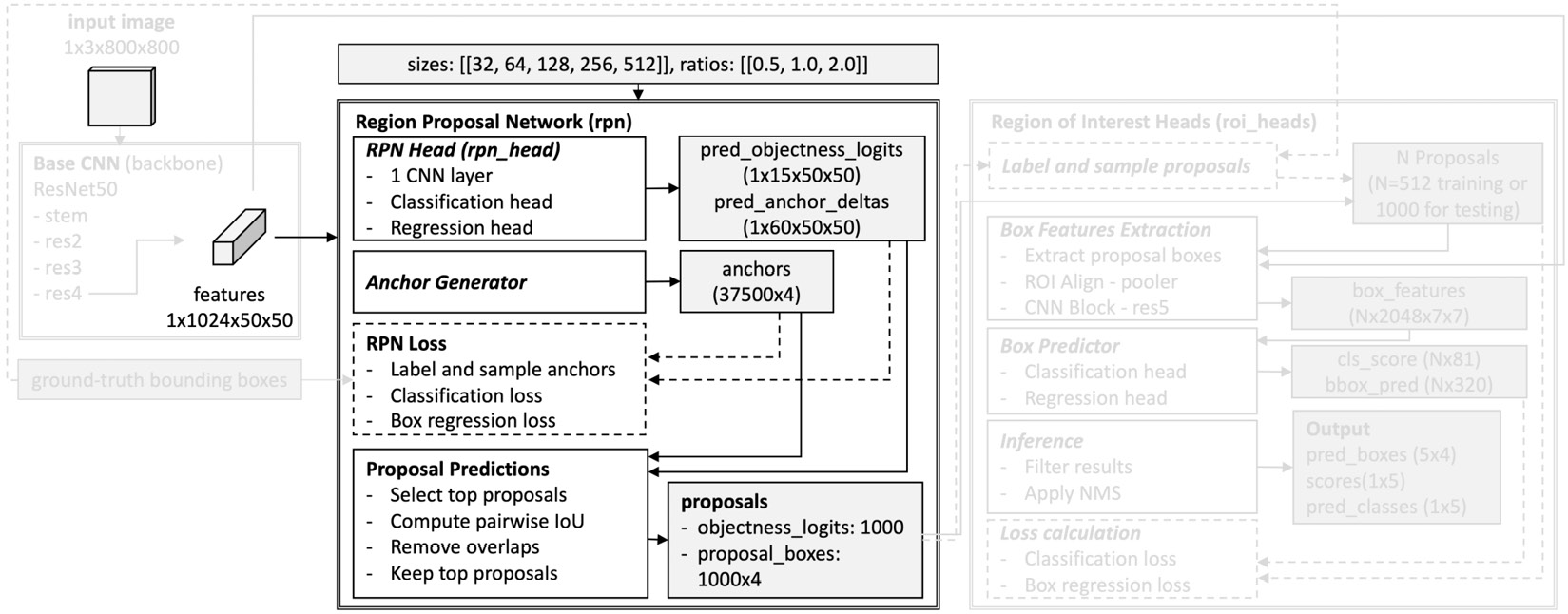
This chapter dives deep into the architecture of Detectron2 for the object detection task. The object detection model in Detectron2 is the implementation of Faster R-CNN. Specifically, this architecture includes the backbone network, the region proposal network, and the region of interest heads. This chapter is essential for understanding common terminology when designing deep neural networks for vision systems. Deep understanding helps to fine-tune and customize models for better accuracy while training with the custom datasets.
By the end of this chapter, you will understand Detectron2’s typical architecture in detail. You also know where to customize your Detectron2 model (what configuration parameters to set, how to set them, and where to add/remove layers) to improve performance. Specifically, this chapter covers the following topics:
- Introduction to the application architecture
- The backbone network...