In the previous chapter, we looked at the basic concepts and definitions of mapping. We talked about fields of metadata and data types. Then, we discussed the relationship between mapping and relevant search results. Finally, we tried to have a good grasp of understanding what the schema-less is in Elasticsearch.
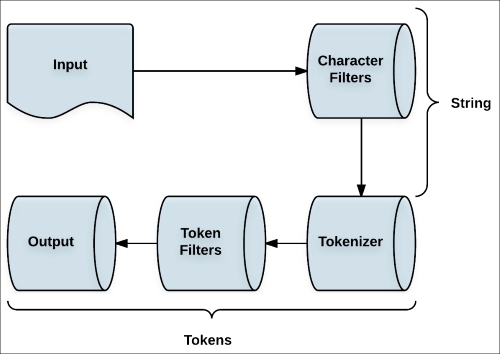
In this chapter, we will review the process of analysis and analyzers. We will examine the tokenizers and we will look closely at the character and token filters. In addition, we will review how to add analyzers to an Elasticsearch configuration. By the end of this chapter, we would have covered the following topics:
What is analysis process?
What is built-in analyzers?
What are doing tokenizers, character, and token filters?
What is text normalization?
How to create custom analyzers?