


Computer vision enables the properties of human vision on a computer. A computer could be in the form of a smartphone, drones, CCTV, MRI scanner, and so on, with various sensors for perception. The sensor produces images in a digital form that has to be interpreted by the computer. The basic building block of such interpretation or intelligence is explained in the next section. The different problems that arise in computer vision can be effectively solved using deep learning techniques.
Image classification is the task of labelling the whole image with an object or concept with confidence. The applications include gender classification given an image of a person's face, identifying the type of pet, tagging photos, and so on. The following is an output of such a classification task:

The Chapter 2, Image Classification, covers in detail the methods that can be used for classification tasks and in Chapter 3, Image Retrieval, we use the classification models for visualization of deep learning models and retrieve similar images.
Detection or localization is a task that finds an object in an image and localizes the object with a bounding box. This task has many applications, such as finding pedestrians and signboards for self-driving vehicles. The following image is an illustration of detection:
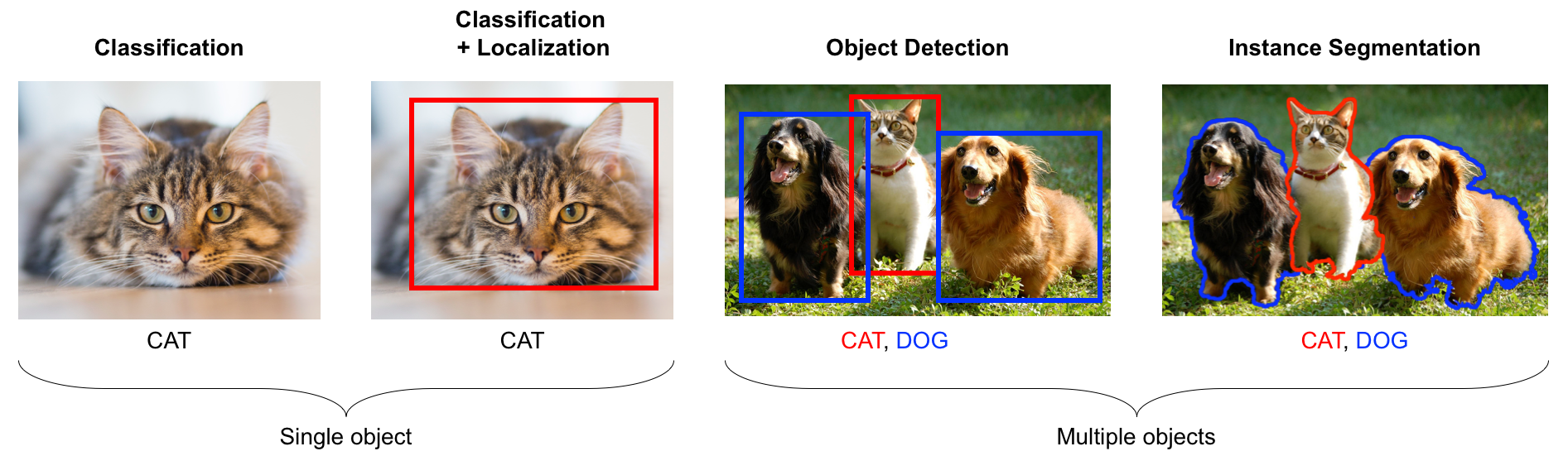
Segmentation is the task of doing pixel-wise classification. This gives a fine separation of objects. It is useful for processing medical images and satellite imagery. More examples and explanations can be found in Chapter 4, Object Detection and Chapter 5, Image Segmentation.
Similarity learning is the process of learning how two images are similar. A score can be computed between two images based on the semantic meaning as shown in the following image:
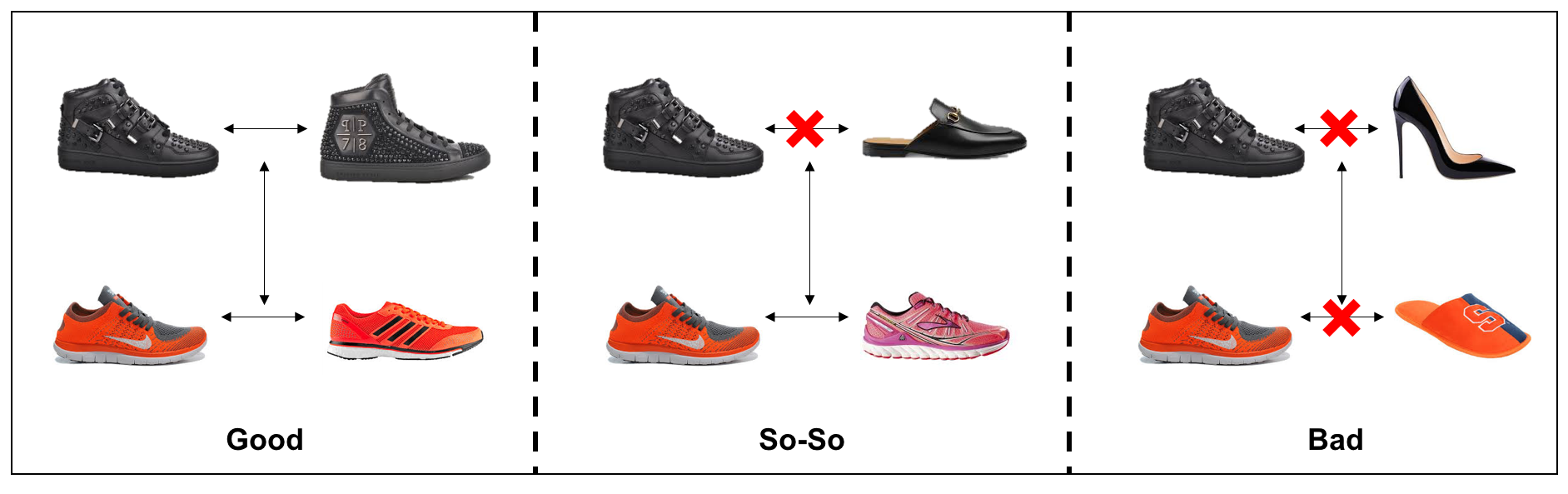
There are several applications of this, from finding similar products to performing the facial identification. Chapter 6, Similarity learning, deals with similarity learning techniques.
Image captioning is the task of describing the image with text as shown [below] here:

Reproduced with permission from Vinyals et al.
The Chapter 8, Image Captioning, goes into detail about image captioning. This is a unique case where techniques of natural language processing (NLP) and computer vision have to be combined.
Generative models are very interesting as they generate images. The following is an example of style transfer application where an image is generated with the content of that image and style of other images:

Reproduced with permission from Gatys et al.
Images can be generated for other purposes such as new training examples, super-resolution images, and so on. The Chapter 7, Generative Models, goes into detail of generative models.
Video analysis processes a video as a whole, as opposed to images as in previous cases. It has several applications, such as sports tracking, intrusion detection, and surveillance cameras. Chapter 9, Video Classification, deals with video-specific applications. The new dimension of temporal data gives rise to lots of interesting applications. In the next section, we will see how to set up the development environment.