


Understanding the main types of ML models
Here we are going to take a look at some of the vast number of techniques and approaches that can be used to solve your problems. Similar to how a hacker may know a handful of techniques in their field (contrary to what Hollywood has you believe), a data scientist might know only one branch or area of the following really well. So don't be discouraged. The key is being able to know what tool to use based on the problem you have.
To put this in context, let's take a Star Wars example. Say you are put in charge of defense on the moon of Endor. You have data on the prior attacks of those pesky Ewoks. The Emperor is getting a little restless, so you decide to put ML to use to try and figure out what's going on and put a stop to it.
ML is very broad, so let's start with the four main categories: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. This distinction comes down to simply how much help the model gets when it's being trained and the desired outcome of the model. The dataset that the model is training on is, appropriately, called the training set. Let's take a look at each of these ML categories in a little more detail.
Supervised learning
Supervised learning is used when you have labeled training data that you feed in. A famous and early example is spam detection. Another would be predicting the price of a car. These are both examples where you know the right answer. The key is that the data is labeled with the main feature you care about and can use that to train your model.
Back to the Endor moon, you have the following data. It shows reports with the weather, time of day, whether shipments are coming in, the number of guards, and other data that may be useful, along with a simple Boolean label of attack: True/False:

Figure 1.2 – Attack data from the moon of Endor
This is a great use case for supervised learning (in this case, should you be worried?). We'll look at this scenario in more detail in Chapter 7, Choosing the Best AI Algorithm.
Algorithms that fall under the supervised learning category are as follows:
- Logistic Regression
- Linear Regression
- Support Vector Machines
- K-Nearest Neighbor (a density-based approach)
- Neural Networks
- Random Forest
- Gradient Boosting
Next, we will cover unsupervised learning.
Unsupervised learning
Unsupervised learning is used when you do not have labeled training data that you feed in. A common scenario is when you have a group of entities and need to cluster them into groups. Some examples where this is used are advertising campaigns based on specific sub-sets of customers, or movies that might share common characteristics.
In the following diagram, you can see different customers from a hypothetical company, and there seem to be three separate groups they naturally fall into:
.
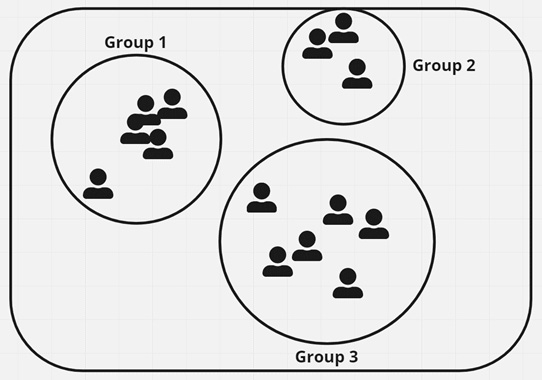
Figure 1.3 – Example of classification problem with three customer groups
This diagram might represent some customers of a new movie recommendation engine you are trying to build, and each group should get a separate genre sent to them for their viewing pleasure.
There is another related approach that takes the same idea of grouping, but instead of trying to see what people or entities fit into a group, you are trying to find the entities that don't fall into one of the main groups. These outliers don't fit into the pattern of the others, and searching for them is known as anomaly detection.
Anomaly detection is also a form of unsupervised learning. You can't have a labeled list of things that are normal and not normal, because how would you know? There isn't a sure way to go through and label all the different ways that something could look inconsistent, as that would be very time-consuming and borderline impossible. This type of problem is also known as outlier detection due to the goal being the detection of those entities that are different from the others.
This can be vital when looking at identity fraud to understand whether an action or response falls out of place of a normal baseline. If you have ever gotten a text or email from your credit card company asking whether it was you that made a purchase, that is anomaly detection at work! There is no way for them to code up every possible scenario that could happen outside the normal, and this again shows the power of ML.
Looking back at our earlier scenario on the moon of Endor, you know that there is some suspicious key card access that has happened. You look at all the data but can't make much of it. You know there isn't a way to figure out which logins in the past were valid, so you can't label the data and thus you determine that this falls into the unsupervised bucket of algorithms.
The following diagram shows what a dataset might look like for the key card events that could be a good candidate for an unsupervised problem, specifically anomaly detection. As you can see, there are no labels on any of the data points.
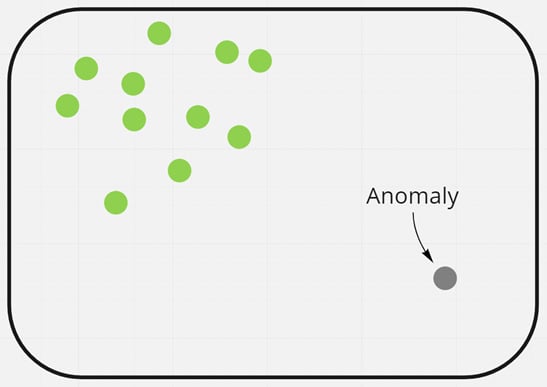
Figure 1.4 – Example of an anomaly problem with one anomaly
One of the data points (the top right) clearly has some characteristics that make it stand out from the rest of the group. The keystrokes take much longer, and the heat sensor reading at the time is much higher. This is a simplistic representation, but you can see how something seems out of place to the eye. That's the essence of what an anomaly is.
With the preceding example, do you think that the event on the bottom right should be investigated, or does it seem normal? It might be worthwhile looking into who accessed the system at that time.
Algorithms that fall under the unsupervised learning category are as follows:
- K-means (a clustering-based approach)
- Isolation forest
- Principal Component Analysis (PCA)
- Neural networks
We've just covered supervised and unsupervised, but there is another type that is somewhat of a mix and subset of the two. Let's take a quick look at what semi-supervised models look like.
Semi-supervised learning
Semi-supervised learning is the process by which you attempt to create a model from data that is both labeled and unlabeled to try and have the best of both the supervised and unsupervised techniques. It attempts to learn from both types of data and is very useful when you don't have the luxury of everything being labeled. Many times, you use the unsupervised approach to find higher-level patterns, and the supervised step to fine-tune exactly what those patterns represent.
In the following example, you'll see where you might have taken part in this process yourself without realizing it.
Have you ever been on Facebook, and it asked you to tag your friends in pictures? That was a semi-supervised approach at work. An unsupervised model groups people's faces together that it thinks are the same person, and then the user will be the one to label those groups as Michael, Donald, Don, and so on. In this way, you have part of the problem as an unsupervised learning problem with the clustering of people into groups, and part as a supervised problem with labeling these groups.
Due to this being a combination of supervised and unsupervised, you can, in theory, pull from any of the algorithm families on the respective groups.
Let's now move on to the last type of AI approach on our list.
Reinforcement learning
The fourth major type of ML, after supervised, unsupervised, and semi-supervised is reinforcement learning. Reinforcement learning (RL) is the process by which a system, called an agent, gradually learns to accomplish some tasks via a reward function by interacting with an environment.
A reward function is a way to determine how desired an outcome is, and the reinforcement learning model attempts to optimize what it's doing to achieve the highest reward value. Take an example of a rat in a maze. In this example, the rat is the agent, the environment is the maze, and the reward function is how strong the smell of cheese is (and ultimately eating it).
Every time it turns the right way, the smell of cheese gets a bit stronger. It then tries to figure out how to navigate in such a way that the smell continues to increase, until it is given the biggest reward at the end, which is a nice slice of mozzarella. Reinforcement is a popular choice in robotics, self-driving, and anything else where you have a clear end goal, but don't have a traditional training dataset as a starting point.
Reward functions can work in the opposite way as well. Take a newborn child, for example. Parents are programmed to minimize the amount of crying that their little girl does, and so they learn what to do or not do. Did you just set her down and she started crying? Pick her up. Crying started in the middle of the night? Try feeding her, then changing her diaper. To our mind, those sound like very simple things, but it's the RL that we all have hard-wired into us that dictates what we do and optimizes us to be good parents. In this case, the parents are the agents observing the environment and taking action, and how much the baby cries is the reward function. Minimize crying, optimize smiling. Being parents all of a sudden sounds pretty straightforward.
Before they were acquired by Google, DeepMind showed how RL can be used to learn to play many Atari games with no prior knowledge of how they work, and with the only input being the pixels on the screen: https://arxiv.org/abs/1312.5602.
This article does a great job of defining what RL is and the one key difference between it and other approaches to AI: https://www.synopsys.com/ai/what-is-reinforcement-learning.html.
In RL, training data is obtained via the direct interaction of the agent with the environment. Training data is the learning agent's experience, not a separate collection of data that has to be fed to the algorithm. This significantly reduces the burden on the supervisor in charge of the training process.
Sometimes, training data is fed into an RL system such as AlphaGo, but that training data is simply used to run simulations using what it knows to be the optimal outcome based on the reward function. Much of the research into self-driving adopts the same approach.
Evaluating the problem type
With all these different types of approaches, it is good to have a simple recap of how to know which path to take when you start to look at a problem. In the following diagram, we'll find a simple flowchart to determine which approach might be correct:
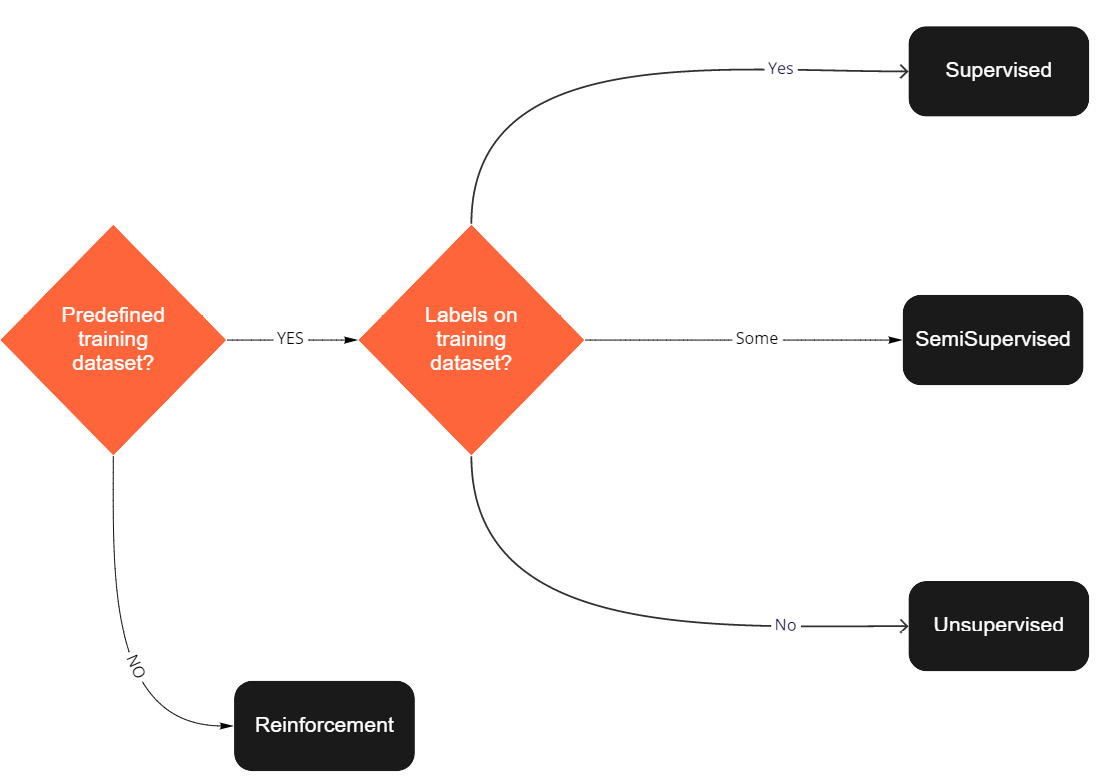
Figure 1.5 – Decision tree for ML problem types
As you can see, there are two key questions that you need to ask yourself that will lead to the most appropriate approach:
- Do I have a training dataset?
- Does this training dataset have labels?
Note that RL still needs training data (as all AI algorithms do), but it's just in a very different shape from the others. RL will get its training data as the agent interacts with the environment. It's not a static set you have in the beginning that you need to generate and clean. Some RL applications, such as AlphaGo, do feed data in for the model to train, but this data is in the form of data needed to create good simulations and gain experience of playing. It's not hard data that it pulls directly from, rather the agent keeps learning as it goes.
One key difference between RL and the others is that the agent can directly impact the data and state of the environment. An algorithm playing an Atari game, a self-driving car, and a bowling machine will all be operating on a dynamic state that the algorithm impacts. A supervised learning algorithm, in contrast, will never change the data that was used in training.
In time, you will know these well enough that you won't need to ask these questions and can just jump to the correct approach, but it's good to use this simple chart as a quick guide to get started.
With this information, you now know the main types of ML problems that you will encounter and solve in the wild. Supervised learning is when you have data with labels, unsupervised learning is when you are trying to make sense of data without labels, and semi-supervised learning is when you use techniques that combine both. You also learned that RL is when you know the outcome you want to achieve and need an agent to figure out how best to accomplish this.
With all of these model types, there is one thing that they all have in common, which is that they might not perform as well over time as they did when you initially trained them. Let's explore what this looks like in more detail in the next section.