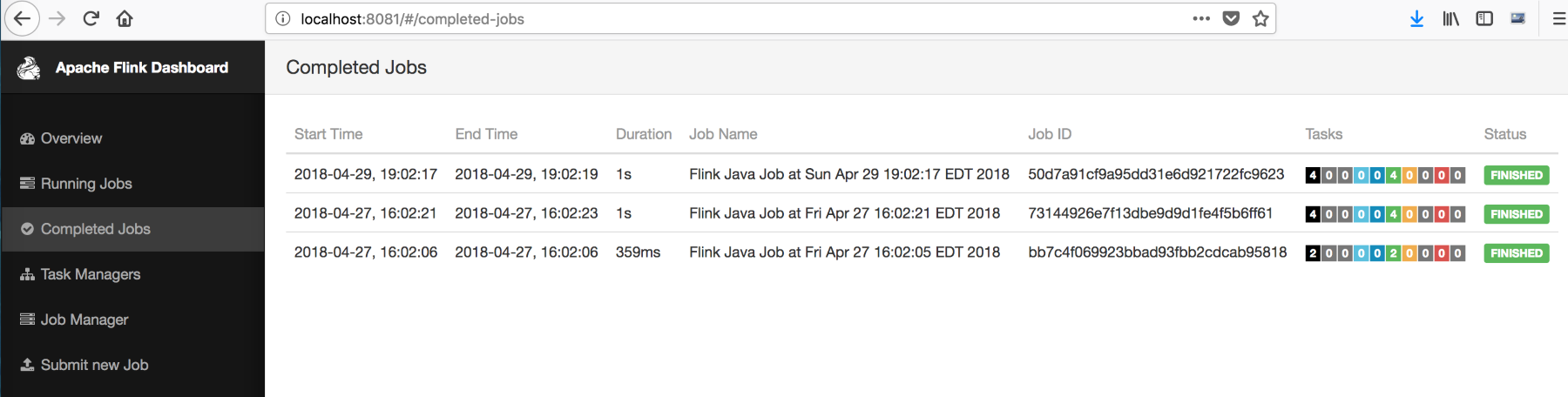
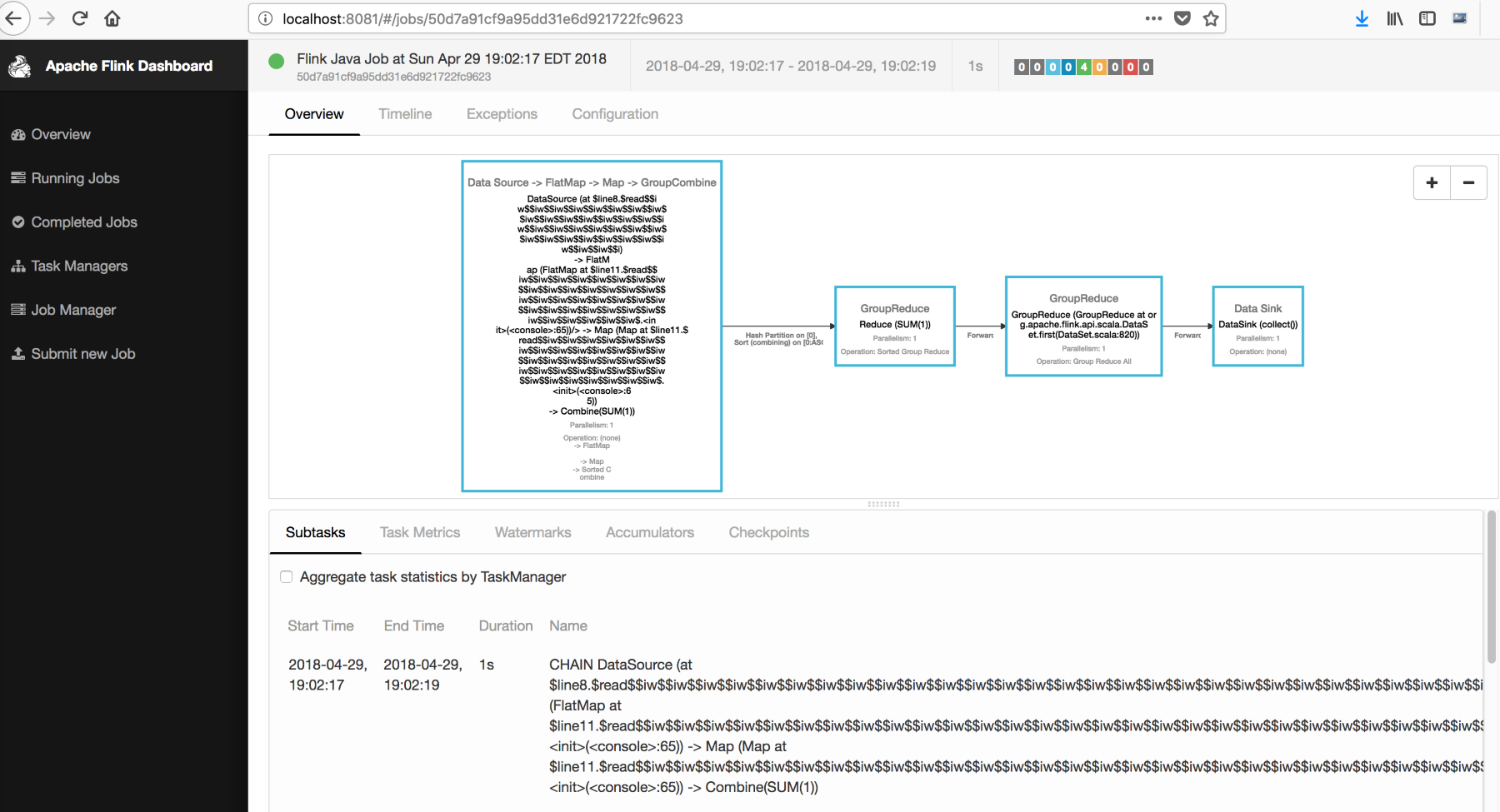
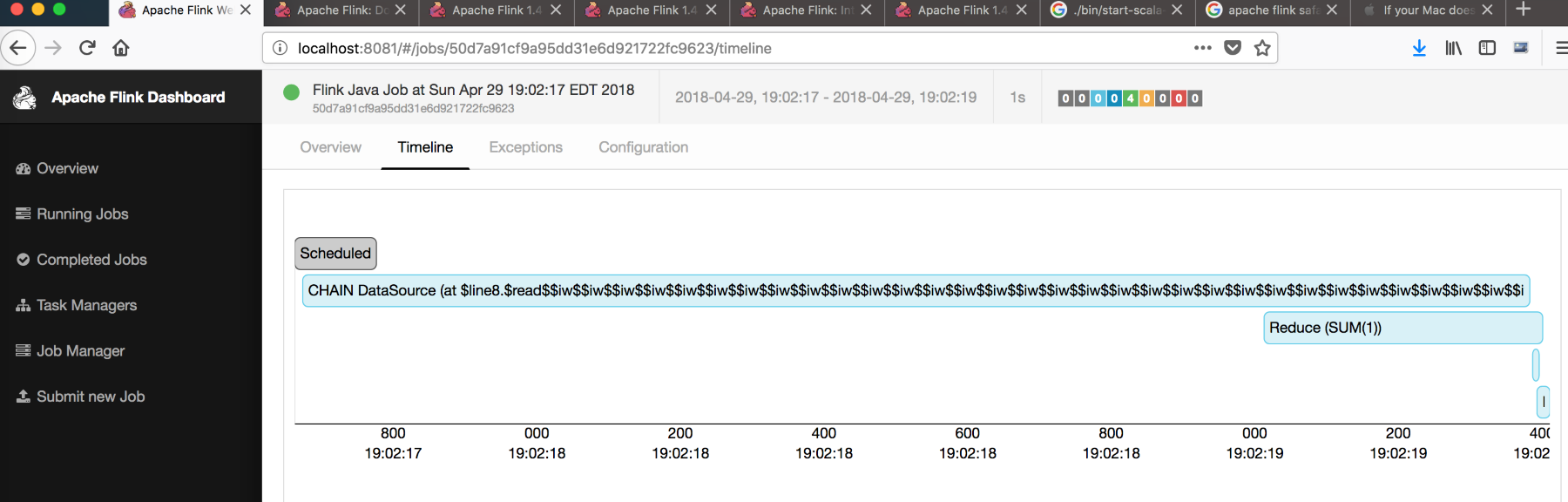
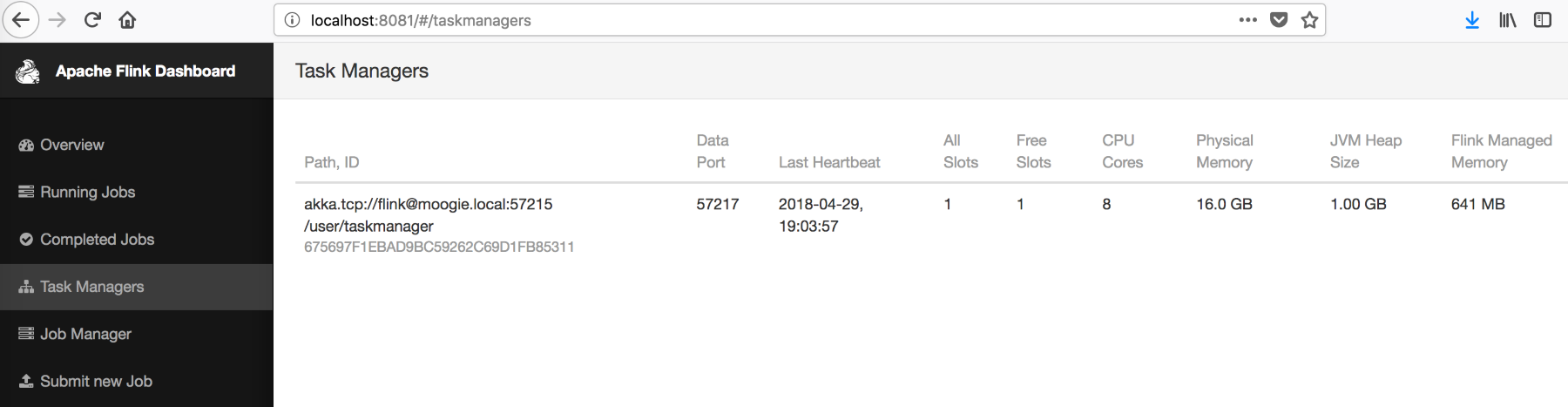
Sridhar?Alla?is the co-founder and CTO of Blue Whale Consulting and is expert at helping companies (big and small) define their vision for systems and capabilities that will allow them to establish a strategic execution plan to deal with the ever-growing data collected to support analytics and product teams. He has very experienced at dealing with all aspects of data collection, security, governance, and processing as part of end-to-end big data analytics and machine learning initiatives (including predictive modeling, deep learning, and ML automation).
Sridhar?is a published book author and an avid presenter at numerous conferences, including Strata, Hadoop World, and Spark Summit.? He also has several patents filed with the US PTO on large-scale computing and distributed systems.?
He has over 18 years' experience writing code in Scala, Java, C, C++, Python, R, and Go, and has extensive hands-on knowledge of Spark, Flink, TensorFlow, Keras, Hadoop, Cassandra, HBase, MongoDB, Riak, Redis, Zeppelin, Mesos, Docker, Kafka, ElasticSearch, Solr, H2O, machine learning, text analytics, distributed computing, and high-performance computing.
Sridhar lives with his wife and daughter in New Jersey and in his spare time loves blogging and coaching organizations on next-generation advancements in technology and their alignment with business goals.
Read more about Sridhar Alla