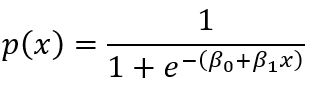Note
Learning Objectives
By the end of this chapter, you will be able to:
Implement logistic regression and explain how it can be used to classify data into specific groups or classes
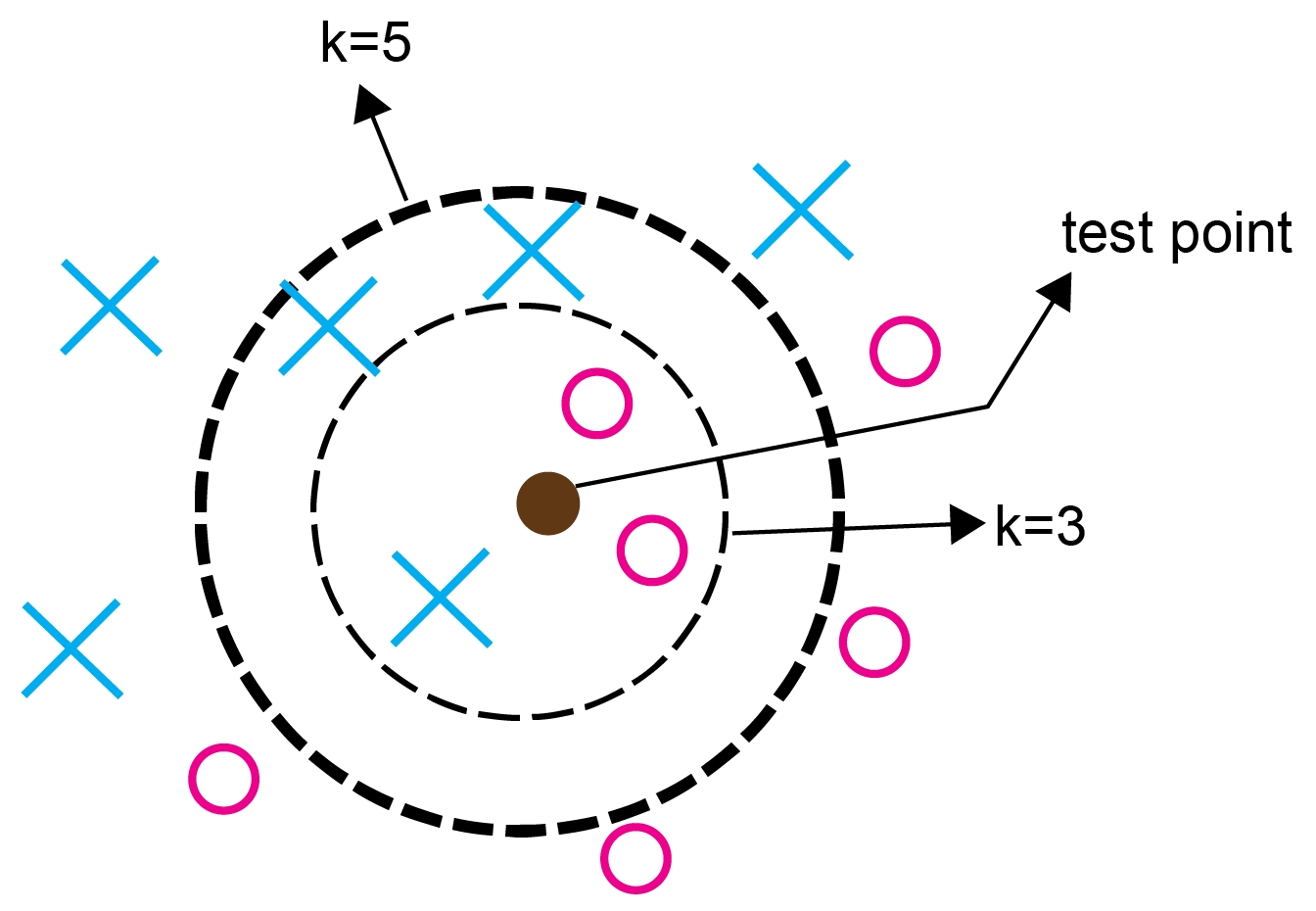
Use the K-nearest neighbors clustering algorithm for classification
Use decision trees for data classification, including the ID3 algorithm
Describe the concept of entropy within data
Explain how decision trees such as ID3 aim to reduce entropy
Use decision trees for data classification