





















































In real Big Data projects, the Coordinators are scheduled tasks that are part of the data pipeline. For example, get data from some system and process it (this forms one Coordinator), and then another sub process can send the processed data to a database (this forms another Coordinator). Finally, both of them are abstracted to form Bundle. To think in terms of how to solve your job using Oozie, start by drawing the job Workflow on a whiteboard/paper. Then discuss with your team how you can create unit abstractions to run individually and in isolation.
Check out the following example.
The database has a record of daily rainfall in Melbourne. We import that data to Hadoop using a regular Coordinator job (Coordinator 1). Using another scheduled job, we send the results back to the database as shown in the following figure:
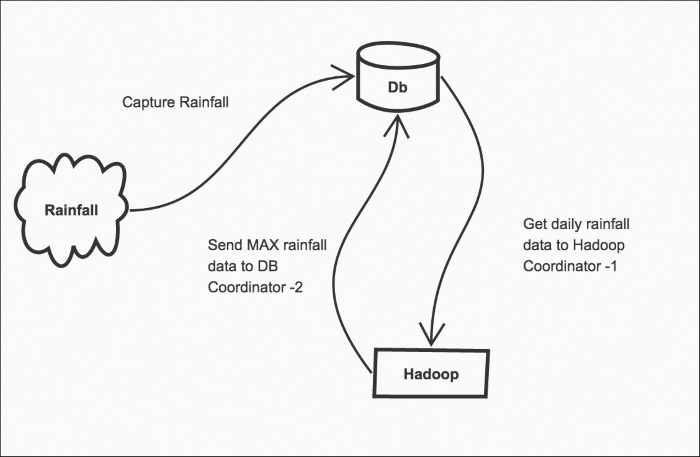
Data pipelines







