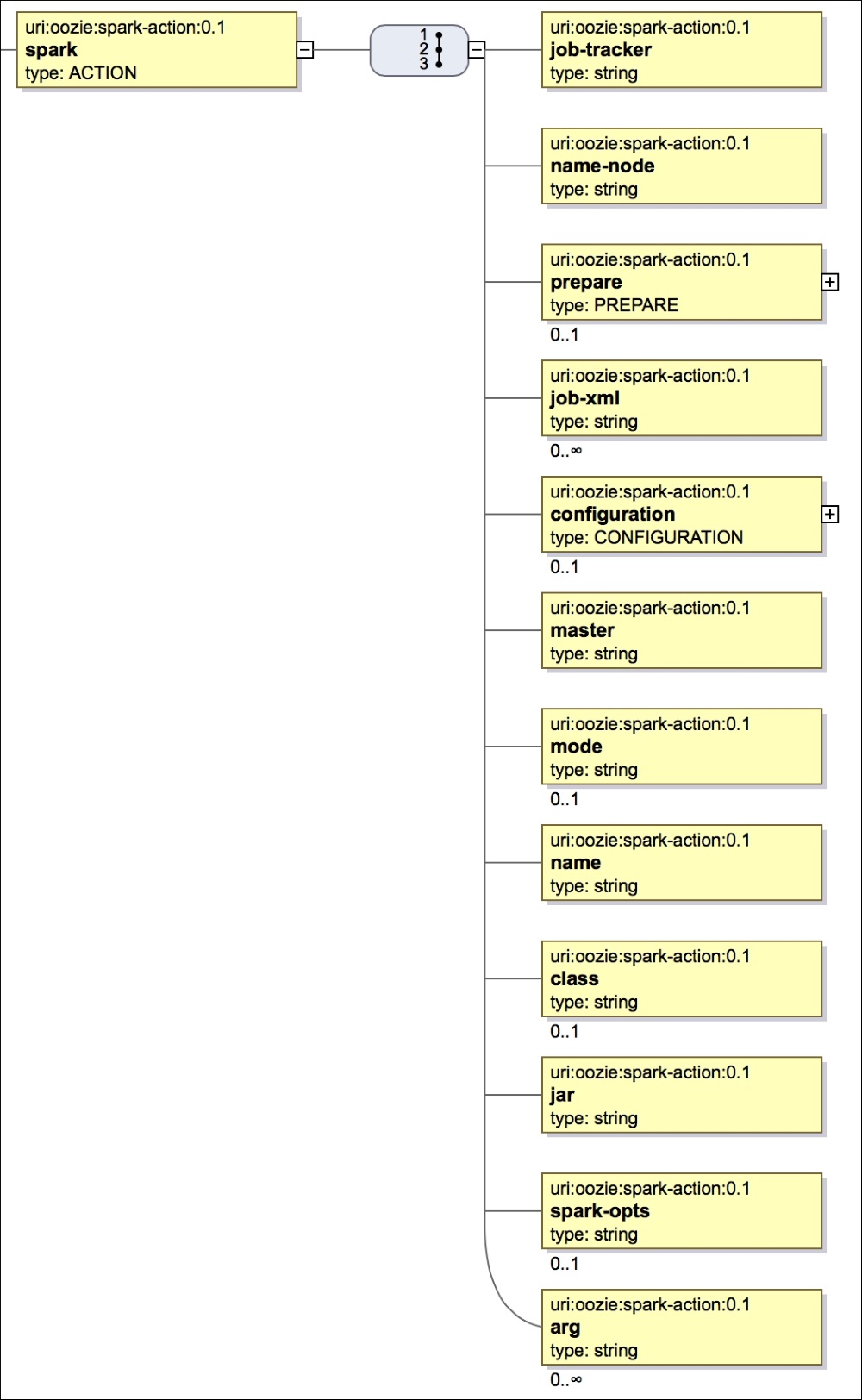
In this chapter, we will see how to run Spark jobs from Oozie. Spark has changed the whole ecosystem of Hadoop and the Big Data world. It can be used as ETL tool or machine learning tool, and it can be used where traditionally we use Pig, Hive, or Sqoop.
In this chapter, we will:
Create Oozie Workflow for Spark actions
From the concept point of view, we will:
Understand the concept of Bundles
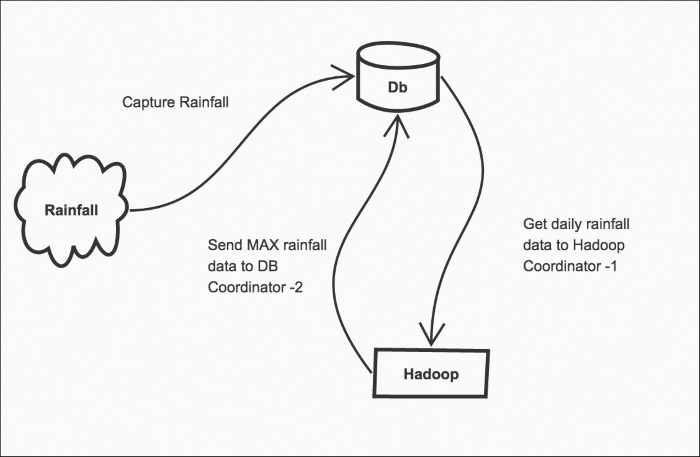
We will start off with a simple Workflow in which we will rewrite the same Pig logic of finding maximum rainfall in a given month in Spark and then we will schedule that using Oozie Workflow and Coordinators. The idea is to show the beauty of Spark—how seamlessly it replaces various tools such as Pig or Hive, and how it has become the default execution engine of the Big Data platform. If you are a very keen follower of Hadoop news, recently Cloudera announced that they are declaring phase out of MapReduce and are going to keep all their eggs in the Spark bucket. The vast number...