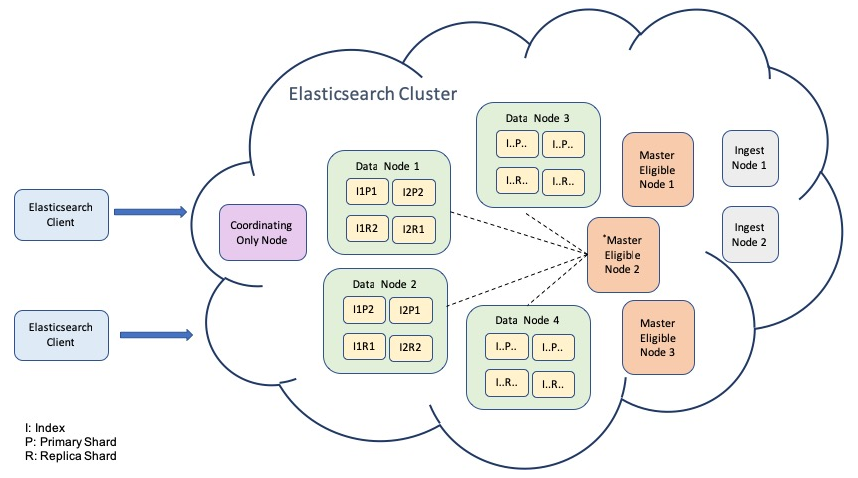
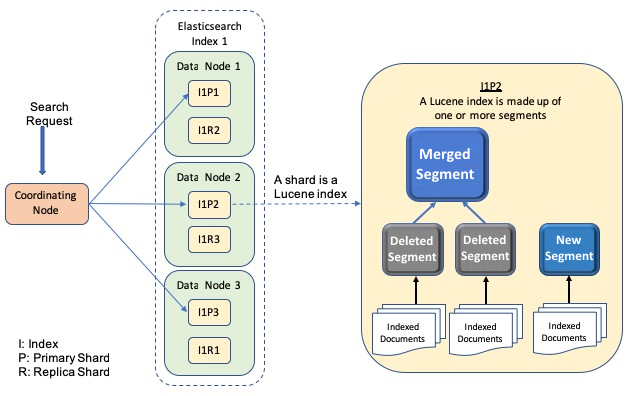
The first step of the novice is to set up the Elasticsearch server, while an experienced user may just need to upgrade the server to the new version. If you are going to upgrade your server software, read through the Breaking changes section and the Migration between versions section to discover the changes that require your attention.
Elasticsearch is developed in Java. As of writing this book, it is recommended that you use a specific Oracle JDK, version 1.8.0_131. By default, Elasticsearch will use the Java version defined by the JAVA_HOME environment variable. Before installing Elasticsearch, please check the installed Java version.
Elasticsearch is supported on many popular operating systems such as RHEL, Ubuntu, Windows, and Solaris. For information on supported operating systems and product compatibility, see the Elastic Support Matrix at https://www.elastic.co/support/matrix. The installation instructions for all the supported platforms can be found in the Installing Elasticsearch documentation (https://www.elastic.co/guide/en/elasticsearch/reference/7.0/install-elasticsearch.html). Although there are many ways to properly install Elasticsearch on different operating systems, it'll be simple and easy to run Elasticsearch from the command line for novices. Please follow the instructions on the official download site (https://www.elastic.co/downloads/past-releases/elasticsearch-7-0-0). In this book, we'll use the Ubuntu 16.04 operating system to host Elasticsearch Service. For example, use the following command line to check the Java version on Ubuntu 16.04:
java -version
java version "1.8.0_181"
java(TM) SE Runtime Environment(build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
The following is a step-by-step guide for installing the preview version from the official download site:
- Select the correct package for your operating system (WINDOWS, MACOS, LINUX, DEB, RPM, or MSI (BETA)) and download the 7.0.0 release. For Linux, the filename is elasticsearch-7.0.0-linux-x86_64.tar.gz.
- Extract the GNU zipped file into the target directory, which will generate a folder called elasticsearch-7.0.0 using the following command:
tar -zxvf elasticsearch-7.0.0-linux-86_64.tar.gz
- Go to the folder and run Elasticsearch with the -p parameter to create a pid file at the specified path:
cd elasticsearch-7.0.0
./bin/elasticsearch -p pid
Elasticsearch runs in the foreground when it runs with the command line above. If you want to shut it down, you can stop it by pressing Ctrl + C, or you can use the process ID from the pid file in the working directory to terminate the process:
kill -15 `cat pid`
Check the log file to make sure the process is closed. You will see the text Native controller process has stopped, stopped, closing, closed near the end of file:
tail logs/elasticsearch.log
To run Elasticsearch as a daemon in background mode, specify -d on the command line:
./bin/elasticsearch -d -p pid
In the next section, we will show you how to run an Elasticsearch instance.