


Evolution of NLP toward Transformers
We have seen profound changes in NLP over the last 20 years. During this period, we experienced different paradigms and finally entered a new era dominated mostly by magical Transformer architecture. This architecture did not come out of nowhere. Starting with the help of various neural-based NLP approaches, it gradually evolved to an attention-based encoder-decoder type architecture and still keeps evolving. The architecture and its variants have been successful thanks to the following developments in the last decade:
- Contextual word embeddings
- Better subword tokenization algorithms for handling unseen words or rare words
- Injecting additional memory tokens into sentences, such as
Paragraph IDinDoc2vecor a Classification (CLS) token in Bidirectional Encoder Representations from Transformers (BERT) - Attention mechanisms, which overcome the problem of forcing input sentences to encode all information into one context vector
- Multi-head self-attention
- Positional encoding to case word order
- Parallelizable architectures that make for faster training and fine-tuning
- Model compression (distillation, quantization, and so on)
- TL (cross-lingual, multitask learning)
For many years, we used traditional NLP approaches such as n-gram language models, TF-IDF-based information retrieval models, and one-hot encoded document-term matrices. All these approaches have contributed a lot to the solution of many NLP problems such as sequence classification, language generation, language understanding, and so forth. On the other hand, these traditional NLP methods have their own weaknesses—for instance, falling short in solving the problems of sparsity, unseen words representation, tracking long-term dependencies, and others. In order to cope with these weaknesses, we developed DL-based approaches such as the following:
- RNNs
- CNNs
- FFNNs
- Several variants of RNNs, CNNs, and FFNNs
In 2013, as a two-layer FFNN word-encoder model, Word2vec, sorted out the dimensionality problem by producing short and dense representations of the words, called word embeddings. This early model managed to produce fast and efficient static word embeddings. It transformed unsupervised textual data into supervised data (self-supervised learning) by either predicting the target word using context or predicting neighbor words based on a sliding window. GloVe, another widely used and popular model, argued that count-based models can be better than neural models. It leverages both global and local statistics of a corpus to learn embeddings based on word-word co-occurrence statistics. It performed well on some syntactic and semantic tasks, as shown in the following screenshot. The screenshot tells us that the embeddings offsets between the terms help to apply vector-oriented reasoning. We can learn the generalization of gender relations, which is a semantic relation from the offset between man and woman (man-> woman). Then, we can arithmetically estimate the vector of actress by adding the vector of the term actor and the offset calculated before. Likewise, we can learn syntactic relations such as word plural forms. For instance, if the vectors of Actor, Actors, and Actress are given, we can estimate the vector of Actresses:
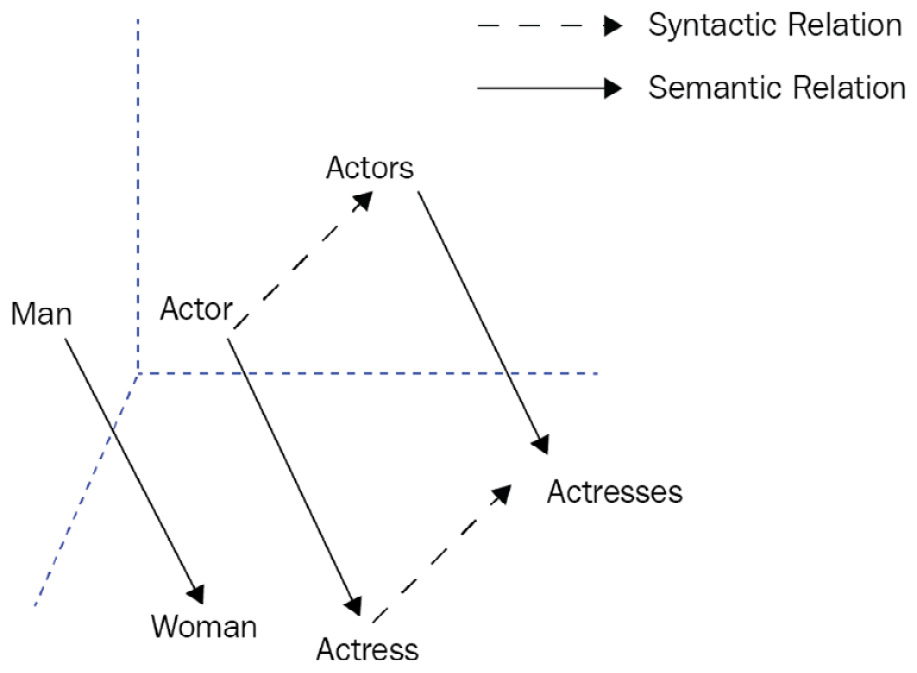
Figure 1.1 – Word embeddings offset for relation extraction
The recurrent and convolutional architectures such as RNN, Long Short-Term Memory (LSTM), and CNN started to be used as encoders and decoders in sequence-to-sequence (seq2seq) problems. The main challenge with these early models was polysemous words. The senses of the words are ignored since a single fixed representation is assigned to each word, which is especially a severe problem for polysemous words and sentence semantics.
The further pioneer neural network models such as Universal Language Model Fine-tuning (ULMFit) and Embeddings from Language Models (ELMo) managed to encode the sentence-level information and finally alleviate polysemy problems, unlike with static word embeddings. These two important approaches were based on LSTM networks. They also introduced the concept of pre-training and fine-tuning. They help us to apply TL, employing the pre-trained models trained on a general task with huge textual datasets. Then, we can easily perform fine-tuning by resuming training of the pre-trained network on a target task with supervision. The representations differ from traditional word embeddings such that each word representation is a function of the entire input sentence. The modern Transformer architecture took advantage of this idea.
In the meantime, the idea of an attention mechanism made a strong impression in the NLP field and achieved significant success, especially in seq2seq problems. Earlier methods would pass the last state (known as a context vector or thought vector) obtained from the entire input sequence to the output sequence without linking or elimination. The attention mechanism was able to build a more sophisticated model by linking the tokens determined from the input sequence to the particular tokens in the output sequence. For instance, suppose you have a keyword phrase Government of Canada in the input sentence for an English to Turkish translation task. In the output sentence, the Kanada Hükümeti token makes strong connections with the input phrase and establishes a weaker connection with the remaining words in the input, as illustrated in the following screenshot:

Figure 1.2 – Sketchy visualization of an attention mechanism
So, this mechanism makes models more successful in seq2seq problems such as translation, question answering, and text summarization.
In 2017, the Transformer-based encoder-decoder model was proposed and found to be successful. The design is based on an FFNN by discarding RNN recurrency and using only attention mechanisms (Vaswani et al., All you need is attention, 2017). The Transformer-based models have so far overcome many difficulties that other approaches faced and have become a new paradigm. Throughout this book, you will be exploring and understanding how the Transformer-based models work.