


Reading in multiple sheets with Python (openpyxl and custom functions)
In many Excel files, it’s common to have multiple sheets containing different sets of data. Being able to read in multiple sheets and consolidate the data into a single data structure can be highly valuable for analysis and processing. In this section, we will explore how to achieve this using the openpyxl library and a custom function.
The importance of reading multiple sheets
When working with complex Excel files, it’s not uncommon to encounter scenarios where related data is spread across different sheets. For example, you may have one sheet for sales data, another for customer information, and yet another for product inventory. By reading in multiple sheets and consolidating the data, you can gain a holistic view and perform a comprehensive analysis.
Let’s start by examining the basic steps involved in reading in multiple sheets:
- Load the workbook: Before accessing the sheets, we need to load the Excel workbook using the
load_workbookfunction provided byopenpyxl. - Get the sheet names: We can obtain the names of all the sheets in the workbook using the
sheetnamesattribute. This allows us to identify the sheets we want to read. - Read data from each sheet: By iterating over the sheet names, we can access each sheet individually and read the data.
Openpyxlprovides methods such asiter_rowsoriter_colsto traverse the cells of each sheet and retrieve the desired data. - Store the data: To consolidate the data from multiple sheets, we can use a suitable data structure, such as a
pandasDataFrameor a Python list. As we read the data from each sheet, we concatenate or merge it into the consolidated data structure:- If the data in all sheets follows the same format (as is the case in the example used in this chapter), we can simply concatenate the datasets
- However, if the datasets have different structures because they describe different aspects of a dataset (for example, one sheet contains product information, the next contains customer data, and the third contains the sales of the products to the customers), then we can merge these datasets based on unique identifiers to create a comprehensive dataset
Using openpyxl to access sheets
openpyxl is a powerful library that allows us to interact with Excel files using Python. It provides a wide range of functionalities, including accessing and manipulating multiple sheets. Before we dive into the details, let’s take a moment to understand why openpyxl is a popular choice for this task.
One of the primary advantages of openpyxl is its ability to handle various Excel file formats, such as .xlsx and .xlsm. This flexibility allows us to work with different versions of Excel files without compatibility issues. Additionally, openpyxl provides a straightforward and intuitive interface to access sheet data, making it easier for us to retrieve the desired information.
Reading data from each sheet
To begin reading in multiple sheets, we need to load the Excel workbook using the load_workbook function provided by openpyxl. This function takes the file path as input and returns a workbook object that represents the entire Excel file.
Once we have loaded the workbook, we can retrieve the names of all the sheets using the sheetnames attribute. This gives us a list of sheet names present in the Excel file. We can then iterate over these sheet names to read the data from each sheet individually.
Retrieving sheet data with openpyxl
openpyxl provides various methods to access the data within a sheet.
Two commonly used methods are iter_rows and iter_cols. These methods allow us to iterate over the rows or columns of a sheet and retrieve the cell values.
Let’s have a look at how iter_rows can be used:
# Assuming you are working with the first sheet sheet = wb['versicolor'] # Iterate over rows and print raw values for row in sheet.iter_rows(min_row=1, max_row=5, values_only=True): print(row)
Similarly, iter_cols can be used like this:
# Iterate over columns and print raw values for column in sheet.iter_cols(min_col=1, max_col=5, values_only=True): print(column)
When using iter_rows or iter_cols, we can specify whether we want to retrieve the cell values as raw values or as formatted values. Raw values give us the actual data stored in the cells, while formatted values include any formatting applied to the cells, such as date formatting or number formatting.
By iterating over the rows or columns of a sheet, we can retrieve the desired data and store it in a suitable data structure. One popular choice is to use pandas DataFrame, which provide a tabular representation of the data and offer convenient methods for data manipulation and analysis.
An alternative solution is using the values attribute of the sheet object. This provides a generator for all values in the sheet (much like iter_rows and iter_cols do for rows and columns, respectively). While generators cannot be used directly to access the data, they can be used in for cycles to iterate over each value. The pandas library’s DataFrame function also allows direct conversion from a suitable generator object to a DataFrame.
Combining data from multiple sheets
As we read the data from each sheet, we can store it in a list or dictionary, depending on our needs. Once we have retrieved the data from all the sheets, we can combine it into a single consolidated data structure. This step is crucial for further analysis and processing.
To combine the data, we can use pandas DataFrame. By creating individual DataFrame for each sheet’s data and then concatenating or merging them into a single DataFrame, we can obtain a comprehensive dataset that includes all the information from multiple sheets.
Custom function for reading multiple sheets
To simplify the process of reading in multiple sheets and consolidating the data, we can create custom functions tailored to our specific requirements. These functions encapsulate the necessary steps and allow us to reuse the code efficiently.
In our example, we define a function called read_multiple_sheets that takes the file path as input. Inside the function, we load the workbook using load_workbook and iterate over the sheet names retrieved with the sheets attribute.
For each sheet, we access it using the workbook object and retrieve the data using the custom read_single_sheet function. We then store the retrieved data in a list. Finally, we combine the data from all the sheets into a single pandas DataFrame using the appropriate concatenation method from pandas.
By using these custom functions, we can easily read in multiple sheets from an Excel file and obtain a consolidated dataset that’s ready for analysis. The function provides a reusable and efficient solution, saving us time and effort in dealing with complex Excel files.
Customizing the code
The provided example is a starting point that you can customize based on your specific requirements. Here are a few considerations for customizing the code:
- Filtering columns: If you only need specific columns from each sheet, you can modify the code to extract only the desired columns during the data retrieval step. You can do this by using the
iter_colsmethod instead of thevaluesattribute and using a filtered list in aforcycle or by filtering the resultingpandasDataFrameobject(s). - Handling missing data: If the sheets contain missing data, you can incorporate appropriate handling techniques, such as filling in missing values or excluding incomplete rows.
- Applying transformations: Depending on the nature of your data, you might need to apply transformations or calculations to the consolidated dataset. The custom function can be expanded to accommodate these transformations.
Remember, the goal is to tailor the code to suit your unique needs and ensure it aligns with your data processing requirements.
By leveraging the power of openpyxl and creating custom functions, you can efficiently read in multiple sheets from Excel files, consolidate the data, and prepare it for further analysis. This capability enables you to unlock valuable insights from complex Excel files and leverage the full potential of your data.
Now, let’s dive into an example that demonstrates this process:
from openpyxl import load_workbook import pandas as pd def read_single_sheet(workbook, sheet_name): # Load the sheet from the workbook sheet = workbook[sheet_name] # Read out the raaw data including headers sheet_data_raw = sheet.values # Separate the headers into a variable columns = next(sheet_data_raw)[0:] # Create a DataFrame based on the second and subsequent lines of data with the header as column names and return it return pd.DataFrame(sheet_data_raw, columns=columns) def read_multiple_sheets(file_path): # Load the workbook workbook = load_workbook(file_path) # Get a list of all sheet names in the workbook sheet_names = workbook.sheetnames # Cycle through the sheet names, load the data for each and concatenate them into a single DataFrame return pd.concat([read_single_sheet(workbook=workbook, sheet_name=sheet_name) for sheet_name in sheet_names], ignore_index=True) # Define the file path and sheet names file_path = 'iris_data.xlsx' # adjust the path as needed # Read the data from multiple sheets consolidated_data = read_multiple_sheets(file_path) # Display the consolidated data print(consolidated_data.head())
Let’s have a look at the results:
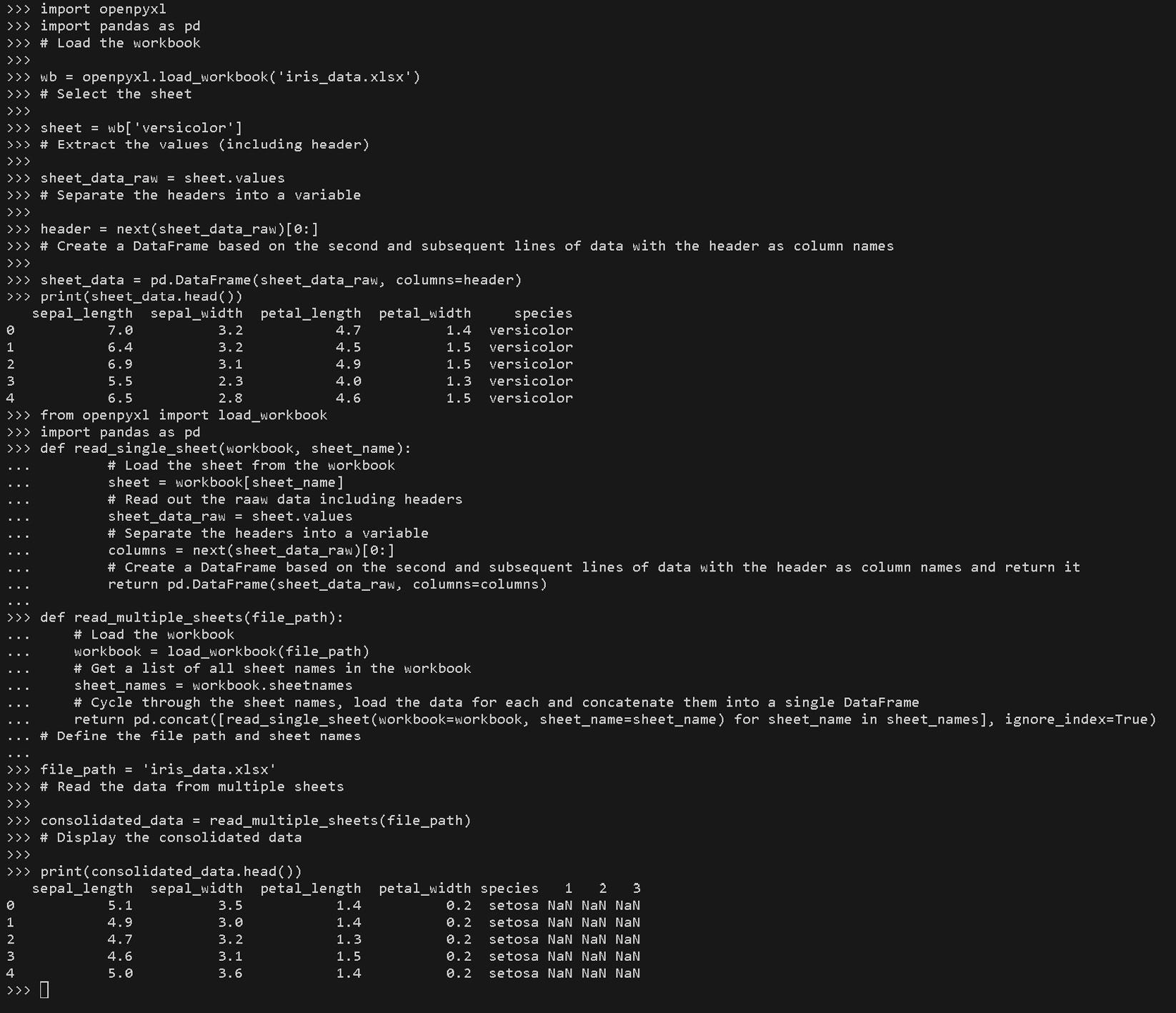
Figure 1.8 – Using the openxlsx package to read in the Excel file
In the preceding code, we define two functions:
read_single_sheet: This reads the data from a single sheet into apandasDataFrameread_multiple_sheets: This reads and concatenates the data from all sheets in the workbook
Within the read_multiple_sheets function, we load the workbook using load_workbook and iterate over the sheet names. For each sheet, we retrieve the data using the read_single_sheet helper function, which reads the data from a sheet and creates a pandas DataFrame for each sheet’s data, with the header row used as column names. Finally, we use pd.concat to combine all the DataFrame into a single consolidated DataFrame.
By utilizing these custom functions, we can easily read in multiple sheets from an Excel file and obtain a consolidated dataset. This allows us to perform various data manipulations, analyses, or visualizations on the combined data.
Understanding how to handle multiple sheets efficiently enhances our ability to work with complex Excel files and extract valuable insights from diverse datasets.