


Unlocking insights from data with OpenAI and LangChain
Artificial intelligence is transforming how people analyze and interpret data. Exciting generative AI systems allow anyone to have natural conversations with their data, even if they have no coding or data science expertise. This democratization of data promises to uncover insights and patterns that may have previously remained hidden.
One pioneering system in this space is LangChain’s Pandas DataFrame agent, which leverages the power of large language models (LLMs) such as Azure OpenAI’s GPT-4. LLMs are AI systems trained on massive text datasets, allowing them to generate human-like text. LangChain provides a framework to connect LLMs with external data sources.
By simply describing in plain English what you want to know about your data stored in a Pandas DataFrame, this agent can automatically respond in natural language.
The user experience feels like magic. You upload a CSV dataset and ask a question by typing or speaking. For example, “What were the top 3 best-selling products last year?” The agent interprets your intent and writes and runs Pandas and Python code to load the data, analyze it, and formulate a response...all within seconds. The barrier between human language and data analysis dissolves.
Under the hood, the LLM generates Python code based on your question, which gets passed to the LangChain agent for execution. The agent handles running the code against your DataFrame, capturing any output or errors, and iterating if necessary to refine the analysis until an accurate human-readable answer is reached.
By collaborating, the agent and LLM remove the need to worry about syntax, APIs, parameters, or debugging data analysis code. The system understands what you want to know and makes it happen automatically through the magic of generative AI.
This natural language interface to data analysis opens game-changing potential. Subject-matter experts without programming skills can independently extract insights from data in their field. Data-driven decisions can happen faster. Exploratory analysis and ideation are simpler. The future where analytics is available to all AI assistants has arrived.
Let’s see how the agent works behind the scenes to send a response.
When a user sends a query to the LangChain create_pandas_dataframe_agent agent and LLM, the following steps are performed behind the scenes:
- The user’s query is received by the LangChain agent.
- The agent interprets the user’s query and analyzes its intention.
- The agent then generates the necessary commands to perform the first step of the analysis. For example, it could generate an SQL query that is sent to the tool that the agent knows will execute SQL queries.
- The agent analyzes the response it receives from the tool and determines whether it is what the user wants. If it is, the agent returns the answer; if not, the agent analyzes what the next step should be and iterates again.
- The agent keeps generating commands for the tools it can control until it obtains the response the user is looking for. It is even capable of interpreting execution errors that occur and generating the corrected command. The agent iterates until it satisfies the user’s question or reaches the limit we have set.
We can represent this with the following diagram:
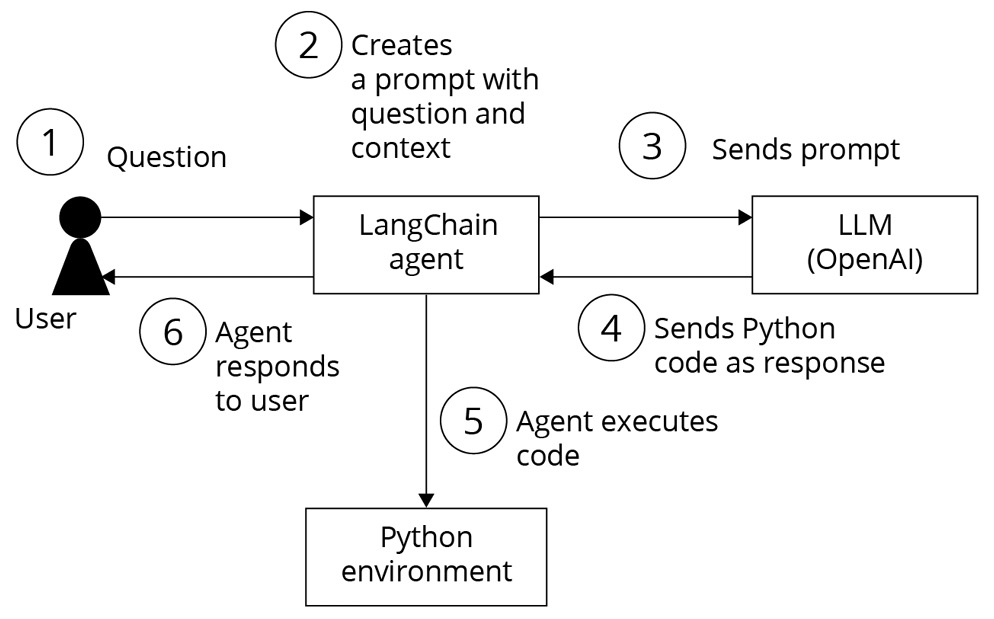
Figure 1.35 – LangChain Pandas agent flow for Data analysis
Let’s see how to perform data analysis and find insights about the income dataset using the LangChain create_pandas_dataframe_agent agent and LLM.
The key steps are importing the necessary LangChain modules, loading data into a DataFrame, instantiating an LLM, and creating the DataFrame agent by passing the required objects. The agent can now analyze the data through natural language queries.
First, let’s install the required libraries. To install the LangChain library, open your Python notebook and type the following:
%pip install langchain %pip install langchain_experimental
This installs the langchain and langchain_experimental packages so you can import the necessary modules.
Let’s import AzureChatOpenAI, the Pandas DataFrame agent, and other required libraries:
from langchain.chat_models import AzureChatOpenAI from langchain_experimental.agents import create_pandas_dataframe_agent import os import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt import openai
Let’s configure the OpenAI endpoint and keys. Your OpenAI endpoint and key values are available in the Azure OpenAI portal:
openai.api_type = "azure" openai.api_base = "your_endpoint" openai.api_version = "2023-09-15-preview" openai.api_key = "your_key" # We are assuming that you have all model deployments on the same Azure OpenAI service resource above. If not, you can change these settings below to point to different resources. gpt4_endpoint = openai.api_base # Your endpoint will look something like this: https://YOUR_AOAI_RESOURCE_NAME.openai.azure.com/ gpt4_api_key = openai.api_key # Your key will look something like this: 00000000000000000000000000000000 gpt4_deployment_name="your model deployment name"
Let’s load CSV data into Pandas DataFrame.
The adult.csv dataset is the dataset that we want to analyze and we have placed this CSV file in the same folder where we are running this Python code:
df = pd.read_csv("adult.csv") Let’s instantiate the GPT-4 LLM.
Assuming, you have deployed the GPT-4 model in Azure OpenAI Studio as per the Technical requirements section, here, we are passing the gpt4 endpoint, key, and deployment name to create the instance of GPT-4 as follows:
gpt4 = AzureChatOpenAI( openai_api_base=gpt4_endpoint, openai_api_version="2023-03-15-preview", deployment_name=gpt4_deployment_name, openai_api_key=gpt4_api_key, openai_api_type = openai.api_type, )
Setting the temperature to 0.0 has the model return the most accurate outputs.
Let’s create a Pandas DataFrame agent. To create the Pandas DataFrame agent, we need to pass the gpt4 model instance and the DataFrame:
agent = create_pandas_dataframe_agent(gpt4, df, verbose=True)
Pass the gpt4 LLM instance and the DataFrame, and set verbose to True to see the output. Finally, let’s ask a question and run the agent.
As illustrated in Figure 1.36, when we ask the following questions to the LangChain agent in the Python notebook, the question is passed to the LLM. The LLM generates Python code for this query and sends it back to the agent. The agent then executes this code in the Python environment with the CSV file, obtains a response, and the LLM converts that response to natural language before sending it back to the agent and the user:
agent("how many rows and how many columns are there?") Output:

Figure 1.36 – Agent response for row and column count
We try the next question:
agent("sample first 5 records and display?") Here’s the output:

Figure 1.37 – agent response for first five records
This way, the LangChain Pandas DataFrame agent facilitates interaction with the DataFrame by interpreting natural language queries, generating corresponding Python code, and presenting the results in a human-readable format.
You can try these questions and see the responses from the agent:
query = "calculate the average age of the people for each incomegroup ?"query ="provide summary statistics forthis dataset"query = "provide count of unique values foreach column"query = "draw the histogram ofthe age"
Next, let’s try the following query to plot the bar chart:
query = "draw the bar chart for the column education" results = agent(query)
The Langchain agent responded with a bar chart that shows the counts for different education levels, as follows.
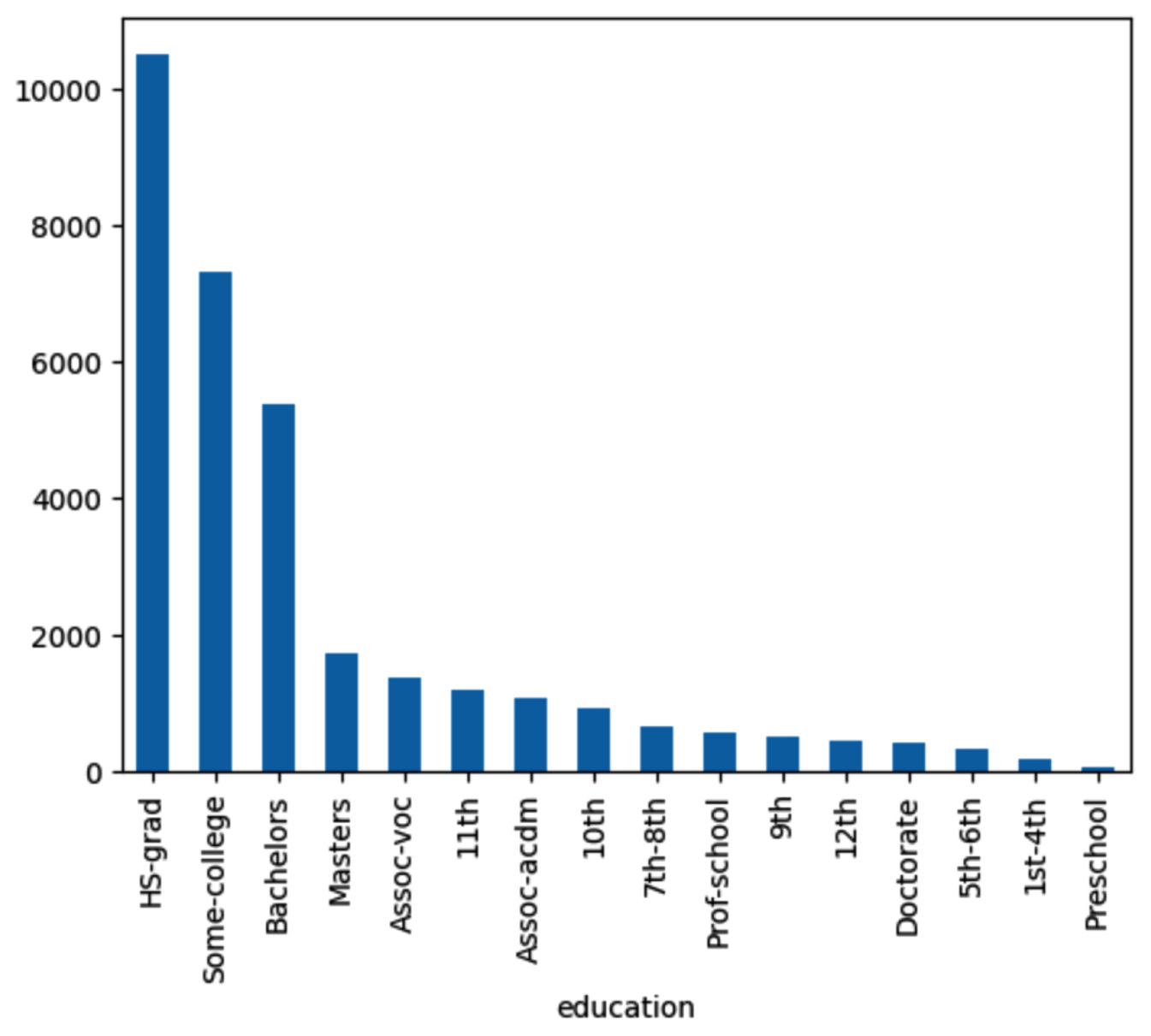
Figure 1.38 – Agent response for bar chart
The plot of the following query shows a comparison of income for different education levels – master’s and HS-GRAD. And we can see the income is less than $5,000 for education.num 8 to 10 when compared to higher education:
query = "Compare the income of those have Masters with those have HS-grad using KDE plot" results = agent(query)
Here’s the output:
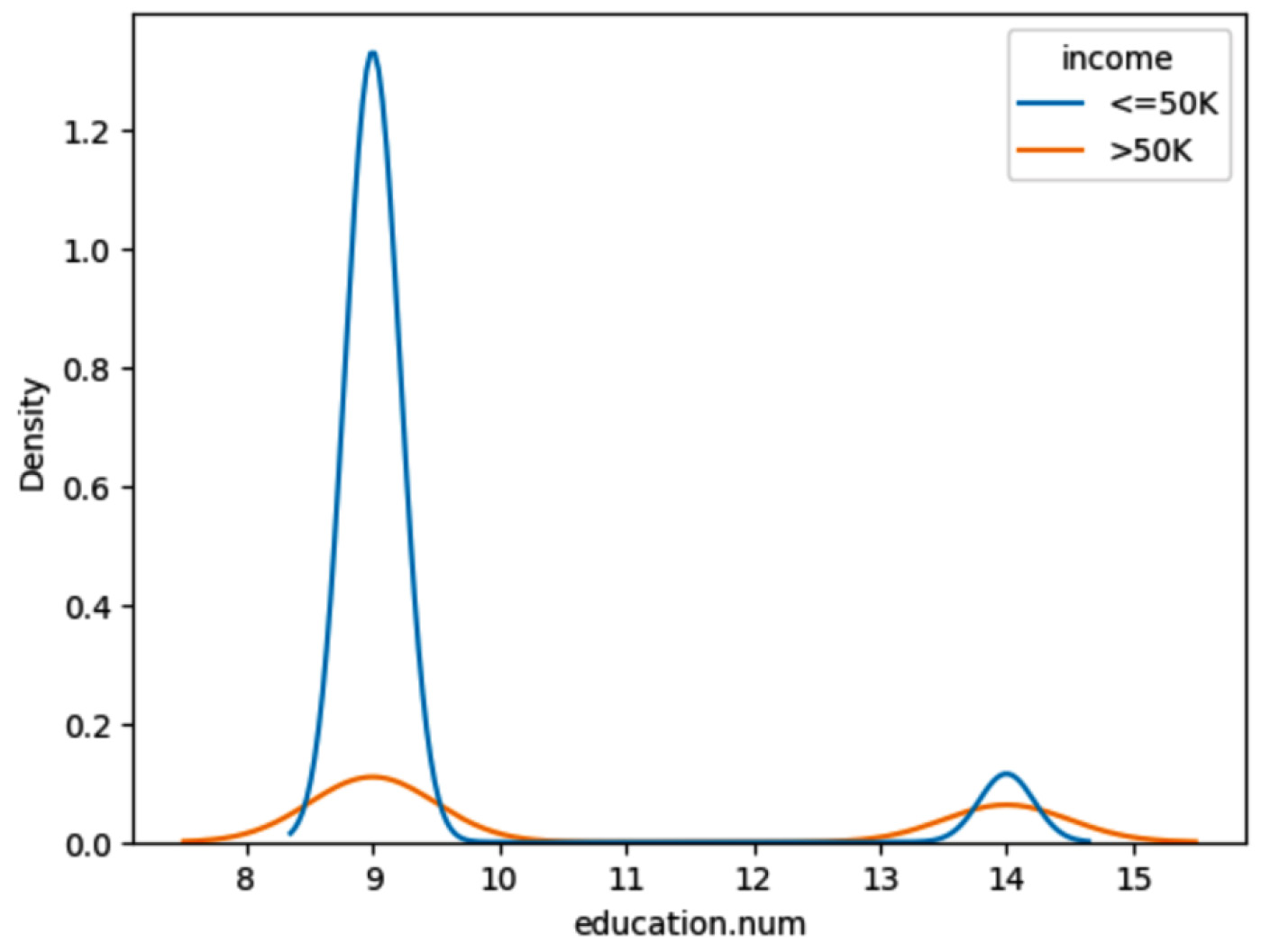
Figure 1.39 – Agent response for comparison of income
Next, let’s try the following query to find any outliers in the data:
query = "Are there any outliers in terms of age. Find out using Box plot." results = agent(query)
This plot shows outliers in age greater than 80 years.
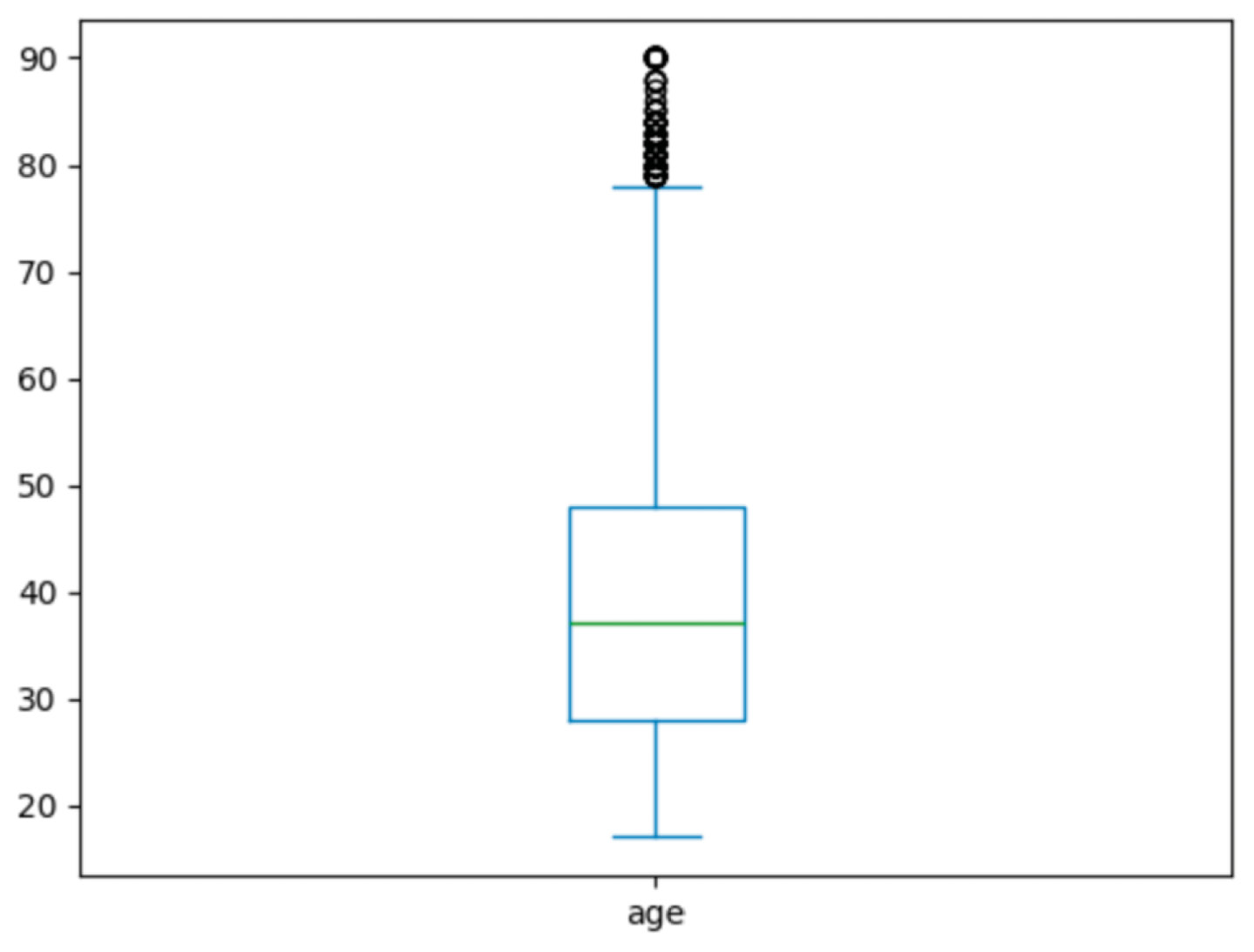
Figure 1.40 – Agent response for outliers
We have seen how to perform data analysis and find insights about the income dataset using natural language with the power of LangChain and OpenAI LLMs.