Congratulations! You have finished this book's introductory section, in which you have explored a great number of topics, and if you were able to follow it, you are prepared to start the journey of understanding the inner workings of many machine learning models.
In this chapter, we will explore some effective and simple approaches for automatically finding interesting data conglomerates, and so begin to research the reasons for natural groupings in data.
This chapter will covers the following topics:
- A line-by-line implementation of an example of the K-means algorithm, with explanations of the data structures and routines
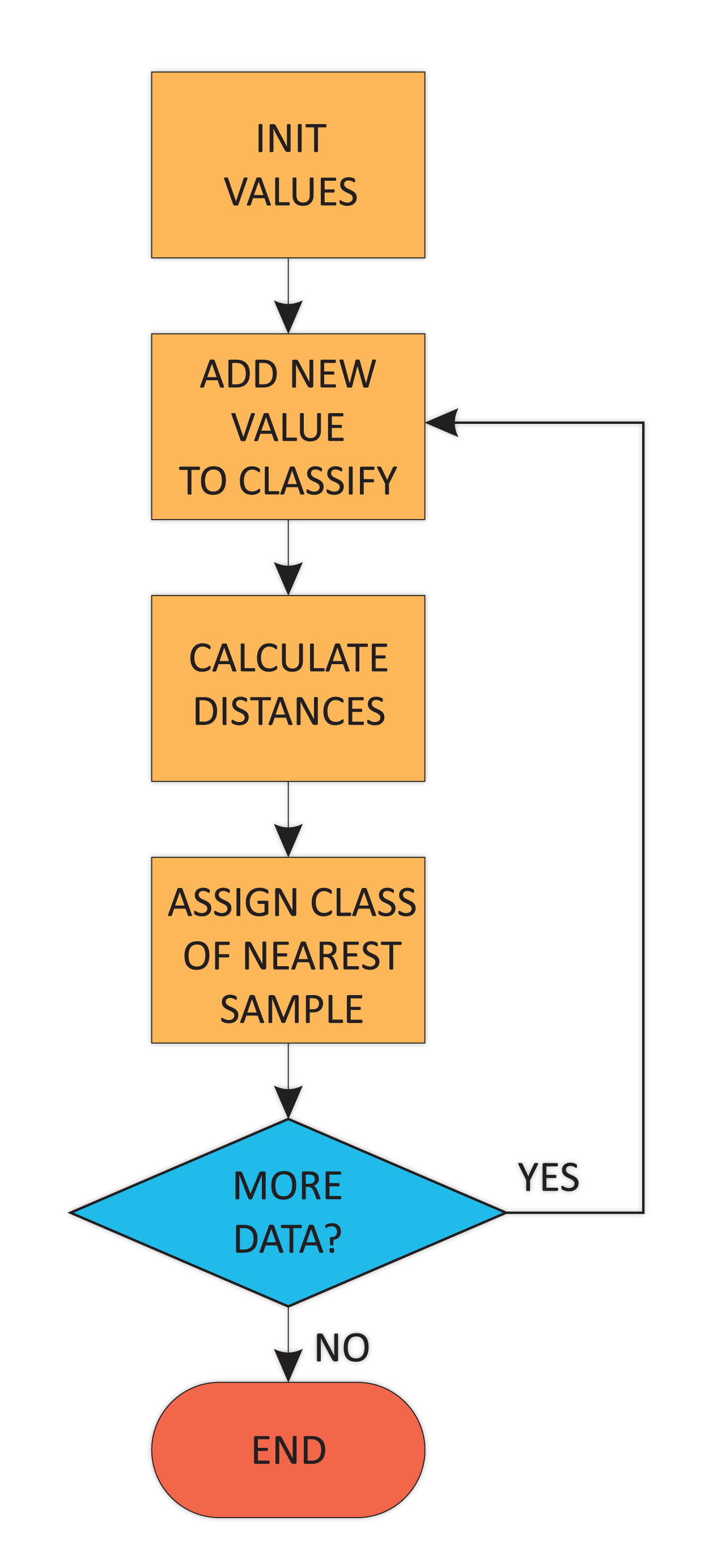
- A thorough explanation of the k-nearest neighbors (K-NN) algorithm, using a code example to explain the whole process
- Additional methods of determining the optimal number of groups representing a set of samples