Functions encapsulate a unit of computation and are most often used to allow that unit of computation to be used in many places. In their pure form, they operate on one or more input values to produce one or more output values. (Of course, C++ functions can only have a single return value, but we’ll come back to this.) The term “pure” means that the function itself is independent of the global program state; only the input data has any effect on the outputs. Non-pure functions have their uses too, but are far less easy to reason about. For this reason, we shall mostly restrict our attention to pure functions here.
Pure functions are a mathematical concept, defined as a relation between two sets under which each member of the “input” set is related to exactly one element of the “output” set (the codomain). That is, any given configuration of inputs should always produce the same output. This is obviously a very general concept, but keeping this in mind is a good reminder of how these should be used. A function should represent a single computation, which might be a numerical calculation or something more general, and return its result.
As we mentioned, C++ functions can only return a single value, but this does not mean that multiple values cannot be returned. For instance, we could make use of aggregate objects such as std::pair or std::tuple to package multiple values into a single object that can be returned, or we could adopt a more C-like approach in which the result is written to one or more addresses passed as pointer arguments. Both approaches have their uses. C++ functions are also unlike their mathematical inspiration because they might fail to complete their calculation for various reasons. In mathematics, the domain of a function can be limited by any number of constraints, whereas C++ can only limit function arguments by type; checking values must be done at runtime, leading to errors.
A function can also be thought of as a means of hiding actual implementation details from the wider program. They are a very low-cost (especially if inlined) means of abstracting particular details such as a distance function between points, an ordering or other comparison, or a predicate function for searching. Functions should be used to logically structure implementations and as a means of providing flexibility for the problem domain. For instance, in the previous section, compute_signal_intensity might have several possible implementations that would yield different search characteristics.
Creating interfaces based on functions
One of the most important uses of functions is as the main interface for your code for external users (library consumers or directly via a GUI or other interface). The advantage of a function is that it is a simple concept that transfers well across boundaries. For instance, C++ functions can be made to use C calling conventions, making them usable from other languages that know how to call C-style functions. (Many languages have the capability to link against libraries compiled in C and use the functions.) Once inside the interface function, you’re free to make use of any of the mechanisms at your disposal to actually implement your solution.
Functions are a good way to define your interface because they are simple and easy to understand, but are still quite expressive. If one needs more complex functionality, one can make use of a more complex configuration object. This can be set with sensible defaults (depending on the problem, of course), so users who just need the basic functionality don’t need to spend a long time configuring. This is a remarkably flexible approach that has relatively small overheads in terms of runtime cost and overhead for the programmer.
Consider the following example. Suppose the problem is to load data from a selection of sources, provided by the user, and then produce a set of summary statistics (mean, standard deviation, min, max, etc.). A very simple interface might include a simple struct that contains the summary statistics, a single function that takes the sources as a sequence of strings describing where to find the data (using uniform resource identifiers, for example), and a configuration that allows the user to customize the actual set of summary statistics produced. (We can’t omit these from the return struct, but we can simply not calculate them.) This could be defined as follows:
struct SummaryStatistics;
class Configuration {
bool b_include_mean = true;
bool b_include_std = true;
public:
bool include_mean() const noexcept { return b_include_mean; }
void include_mean(bool setting) noexcept {
b_include_mean = setting;
}
};
std::vector<SummaryStatistics>
compute_statistics(const Configuration& config, std::span<const std::string> sources);
Notice that the Configuration object is entirely inline, but it is still part of the interface of the program. Indeed, if this class changes (by adding new settings, for instance), then the function would have to be recompiled and would likely break backwards compatibility.
There is a good argument for making your programming interface as minimal as possible, making use of inline functions or very simple classes to adapt more complex driver routines rather than exporting everything. (This might be ideal, but it will not always be feasible.)
Sometimes, functions will not be completely sufficient for describing the interface you need. In this case, you might have to turn to using a class-based interface. This has some advantages in terms of flexibility, but it does expose some additional details about the implementation that one might want to keep private (to maintain intellectual property, for instance). There are ways around this, but none of these are as simple as a function-based interface.
Functions as building blocks
Functions are very useful for solving combinatorial or numerical problems. Typically, these kinds of problems have several moving parts. At the outer level, there is typically some kind of driving operation that performs an iteration over the problem domain. Inside this driver is a computation aspect and a decision aspect. In a sorting problem, the computation involves comparing pairs of elements, and the decision is whether to swap the positions of the two elements. The same holds true in many numerical algorithms that involve collections of data. (Obviously, computations that operate on single numbers or small collections of numbers do not usually require such complexity.) Functions are ideal for isolating these aspects and making the final solution easier to understand.
For example, suppose we want to find the value of a real number 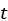 at which some unknown (continuous) function
at which some unknown (continuous) function 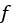 obtains the value zero. One approach would be to use repeated bisection. This problem requires three pieces of information. The first is the (continuous) function itself, which takes a single argument and returns a single number; the second is a point in the domain at which the function takes a positive value; and the third is a value at which the function takes a negative value. We can implement the algorithm as follows:
obtains the value zero. One approach would be to use repeated bisection. This problem requires three pieces of information. The first is the (continuous) function itself, which takes a single argument and returns a single number; the second is a point in the domain at which the function takes a positive value; and the third is a value at which the function takes a negative value. We can implement the algorithm as follows:
#include <cmath>
template <typename Function, typename Real>
Real find_root_bisect(Function&& function, Real pos, Real neg, Real tol)
{
auto fpos = function(pos);
while (compare_reals_equal(pos, neg)) {
auto m = midpoint(pos, neg);
auto fm = function(m);
if (std::abs(fm) < tol) { return m; }
if (std::signbit(fm) == std::signbit(fpos)) {
pos = m;
fpos = fm;
} else {
neg = m;
}
}
return fpos;
}
There are two “building block” functions in this implementation. The first (compare_reals_equal) is a function to determine whether two real numbers are distinguishable from one another – remember that C++ doubles only have a precision of approximately 15 decimal places (at best). The second function (midpoint) is used to compute the midpoint of the two given values. This isn’t strictly necessary here because computing the midpoint is so simple, but other similar algorithms use more complicated logic to determine which point should be checked next. Both of these building blocks could be replaced by more nuanced implementations that could change the characteristics of the iterative method. Keeping these as functions allows us to replace them more easily later (abstracting the algorithm), perhaps using additional template arguments and function-like objects (see the next section). At the very least, using functions here allows us to remain flexible as to the Real type. For instance, we might use a type that does not overload operator+ but works in the algorithm.
Let’s take a moment to understand the requirements of this algorithm. The first constraint is the mathematical requirements of the function. We require that the function takes a single real number, returns a single real number, is continuous – if one were to plot this function, the line would have no jumps – and that it has at least one positive value and at least one negative value. We cannot check that the function is continuous in the code.
The function will still run if this is not the case, but might not produce a meaningful answer (garbage in, garbage out); this is quite typical of numerical algorithms. The other conditions can be checked. For instance, we can check that the function is positive at one value and negative at the other rather simply, but we omit these checks in the preceding code to save space.
Function-like objects
In C++, we can define classes that have an operator() member function, which allows instances of the classes to be called like functions. These are surprisingly useful because they interact better with the template mechanism. (Function pointers cannot be meaningfully default-constructed, but function-like objects can.) The standard library contains several function-like objects in the functional header, including std::less and std::hash. These objects are used as default template parameters for containers such as std::map and std::unordered_map, and also in algorithms.
Function-like objects also include lambda functions, which are really syntactic sugar that the compiler turns into a class definition during compilation. Captured variables are just data members of this class that are injected into the call function body. Lambdas are a very useful means of declaring function-like objects. Our previous examples illustrate this perfectly.
More generally, callable classes can be used to represent functions that carry internal state (non-pure functions). A good example of where this is useful is if your function has some implicit random state. The class can maintain the random generator (e.g., std::mt19937) that is used to inject random state whenever the function is called. Here is an example.
#include <random>
class FunctionWithNoise {
std::mt19937 m_rng;
std::normal_distribution<double> m_dist;
public:
double operator()(double arg) noexcept {
auto noise = m_dist(m_rng);
return 2.*arg + 1 + noise;
}
};
Such a function would be useful in simulating data, where we need to generate large amounts of data that follows a known trend, but includes some randomly generated noise. For instance, this class could be useful for testing the performance of an inference pipeline.
Functions are very useful, but they are limited by the fact that they cannot usually hold state. Function objects can carry state, but this is a very poor reflection of the flexibility and power of fully object-oriented programming. In the next section, we will see how to make use of all the features of classes and inheritance to build truly flexible systems.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand




















