























































Understanding k-means clustering
Clustering is a very basic problem that appears in many different contexts. It is an example of an unsupervised learning problem, meaning that the task is to learn the clusters from the data without the need for additional information. (A linear regression is a classic example of a supervised learning problem, since it requires both the underlying data and the corresponding set of outcomes.) There are many algorithms for clustering data, but by far the simplest is 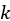 -means clustering. Here, the task is to divide the data into clusters in such a way that minimizes some kind of objective function, which is usually the distance to the mean of the cluster. (The objective function can be chosen to invoke specific constraints on the clusters that one wishes to find.) An illustration of a set of two-dimensional data clustered using k-means is shown in Figure 11.1; the cluster centers are denoted by large X’s, and the marker denotes which cluster each...
-means clustering. Here, the task is to divide the data into clusters in such a way that minimizes some kind of objective function, which is usually the distance to the mean of the cluster. (The objective function can be chosen to invoke specific constraints on the clusters that one wishes to find.) An illustration of a set of two-dimensional data clustered using k-means is shown in Figure 11.1; the cluster centers are denoted by large X’s, and the marker denotes which cluster each...












