























































Creating an Amazon Redshift Serverless data warehouse using the AWS Console
The AWS Management Console allows you to interactively create an Amazon Redshift serverless data warehouse via a browser-based user interface. Once the data warehouse has been created, you can use the Console to monitor its health and diagnose query performance issues from a unified dashboard. In this recipe, you will learn how to use the unified dashboard to deploy a Redshift serverless.
Getting ready
To complete this recipe, you will need:
- An existing or new AWS Account. If new AWS accounts need to be created, go to https://portal.aws.amazon.com/billing/signup, enter the information, and follow the steps on the site.
- An IAM user with access to Amazon Redshift.
How to do it…
The following steps will enable you to create a cluster with minimal parameters:
- Navigate to the AWS Management Console and select Amazon Redshift, https://console.aws.amazon.com/redshiftv2/.
- Choose the AWS Region (
eu-west-1) or the corresponding region at the top right of the screen and then click Next. - On the Amazon Redshift console, in the left navigation pane, choose Serverless Dashboard, and then click Create workgroup, as shown in Figure 1.1:
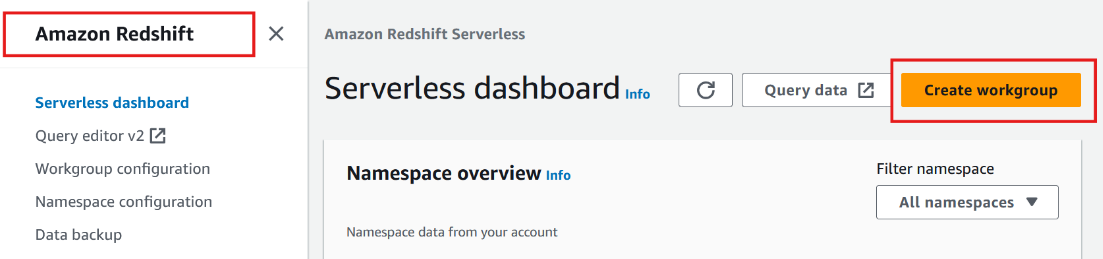
Figure 1.1 – Creating an Amazon Redshift Serverless workgroup
- In the Workgroup section, type any meaningful Workgroup Name like
my-redshift-wg. - In the Performance and cost controls section, you can choose the compute capacity for the workgroup. You have two options to choose from:
- Price-performance target (recommended): This option allows Amazon Redshift Serverless to learn your workload patterns by analyzing factors such as query complexity and data volumes. It automatically adjusts compute capacity throughout the day based on your needs. You can set your price-performance target using a slider:
- Left: Optimizes for cost
- Middle: Balances cost and performance
- Right: Optimizes for performance

Figure 1.2 – Price performance target option
- Base capacity: With this option, you will choose a static base compute capacity for the workgroup. Use this option only if you believe that you understand the workload characteristics well and want control of the compute capacity. Using the drop-down for Base capacity, you can choose a number for Redshift processing units (RPUs) between
8and1024, as shown in the following screenshot. RPU is a measure of compute capacity.
- Price-performance target (recommended): This option allows Amazon Redshift Serverless to learn your workload patterns by analyzing factors such as query complexity and data volumes. It automatically adjusts compute capacity throughout the day based on your needs. You can set your price-performance target using a slider:
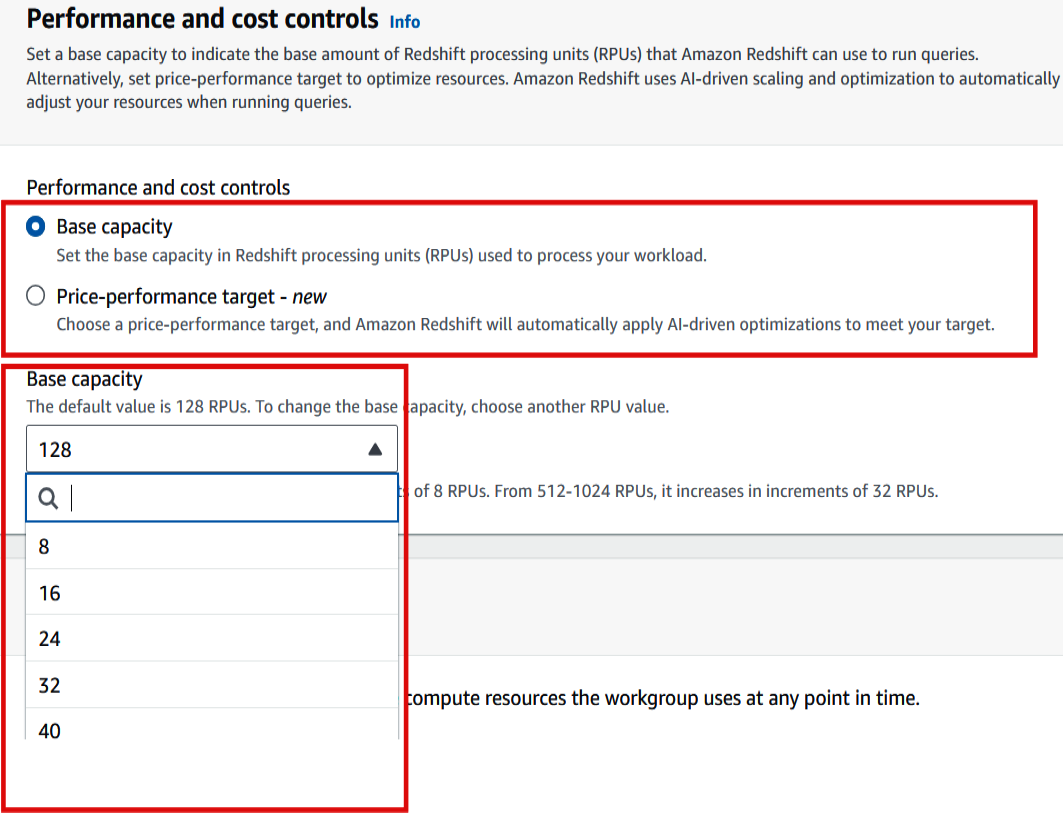
Figure 1.3 – Base capacity option
- In the Network and security section, set IP address type to IPv4.
- In the Network and security section, select the appropriate Virtual private cloud (VPC), VPC security groups, and Subnet.
- If your workload needs network traffic between your serverless database and data repositories routed through a VPC instead of the internet, then enable Turn on enhanced VPC routing by checking the box. For this book, we will leave it unchecked and then click Next.
- In the Namespace section, select Create a new Namespace and type any meaningful name for Namespace like
my-redshift-ns. - In the Database name and password section, leave the defaults as is, which will create a default database called
devand give the IAM credentials you are using as default admin user credentials. - In the Permissions section, leave all the settings as default.
- In the Encryption and security section, leave all the settings at the defaults and then click Next.
- In the Review and create section, validate that all the settings are correct and then click Create.
How it works…
The Amazon Redshift serverless data warehouse consists of a namespace, which is a collection of database objects and users, and a workgroup, which is a collection of compute resources. Namespaces and workgroups are scaled and billed independently. Amazon Redshift Serverless automatically provisions and scales the compute capacity based on the usage, when required. You only pay for a workgroup when the queries are run, there is no compute charge for idleness. Similarly, you only pay for the volume of data stored in the namespace.












