


















 Download code from GitHub
Download code from GitHub
Chapter 1: Kubernetes Fundamentals
Welcome to The Kubernetes Bible. This is the first chapter of this book, and I'm happy to accompany you on your journey with Kubernetes. If you are working in the software development industry, you have probably heard about Kubernetes. This is normal because the popularity of Kubernetes has grown a lot in recent years.
Built by Google, Kubernetes is the leading container orchestrator solution in terms of popularity and adoption: it's the tool you need if you are looking for a solution to manage containerized applications in production at scale, whether it's on-premises or on a public cloud. Be focused on the word. Deploying and managing containers at scale is extremely difficult because, by default, container engines such as Docker do not provide any way on their own to maintain the availability and scalability of containers at scale.
Kubernetes first emerged as a Google project, and they put a lot of effort into building a solution to deploy a huge number of containers on their massively distributed infrastructure. By adopting Kubernetes as part of your stack, you'll get an open source platform that was built by one of the biggest companies on the internet, with the most critical needs in terms of stability.
Although Kubernetes can be used with a lot of different container runtimes, this book is going to focus on the Kubernetes + Docker combination.
Perhaps you are already using Docker on a daily basis, but the world of container orchestration might be completely unknown to you. It is even possible that you do not even see the benefits of using such technology because everything looks fine to you with just raw Docker. That's why, in this first chapter, we're not going to look at Kubernetes in detail. Instead, we will focus on explaining what Kubernetes is and how it can help you to manage your Docker containers in production. It will be easier for you to learn a new technology if you already understand why it was built.
In this chapter, we're going to cover the following main topics:
- Understanding monoliths and microservices
- Understanding containers and Docker
- What is Kubernetes?
- How can Kubernetes help you to manage Docker containers?
- What problem does Kubernetes solve?
- Understanding the story of Kubernetes
Understanding monoliths and microservices
Let's put Kubernetes and Docker to one side for the moment, and instead, let's talk a little bit about how internet and software development evolved together over the past 20 years. This will help you to gain a better understanding of where Kubernetes sits and what problem it solves.
Understanding the growth of the internet since the late 1990s
Since the late 1990s, the popularity of the internet has grown rapidly. Back in the 1990s, and even in the early 2000s, the internet was only used by a few hundred thousand people in the world. Today, almost 2 billion people are using the internet, whether for email, web browsing, video games, or more.
There are now a lot of people on the internet, and we're using it to answer tons of different needs, and these needs are adressed by dozens of applications deployed on dozens of devices.
Additionally, the number of connected devices has increased, as each person can now have several devices of a different nature connected to the internet: laptops, computers, smartphones, TVs, tablets, and more.
Today, we can use the internet to shop, to work, to entertain, to read, or to do whatever. It has entered almost every part of our society and has led to a profound paradigm shift for the last 20 years. All of this has given the utmost importance to software development.
Understanding the need for more frequent software releases
To cope with this ever-increasing number of users who are always demanding more in terms of features, the software development industry had to evolve in order to make new software releases faster and more frequent.
Indeed, back in the 1990s, you could build an application, deploy it to production, and simply update it once or twice a year. Today, companies must be able to update their software in production, sometimes several times a day, whether to deploy a new feature, to integrate with a social media platform, to support the resolution of the latest fashionable smartphone, or even to release a patch to a security breach identified the day before. Everything is far more complex today, and you must go faster than before.
We constantly need to update our software, and in the end, the survival of many companies directly depends on how often they are able to offer releases to their users. But how do we accelerate software developments life cycles so that we can deliver new versions of our software to our users more frequently?
IT departments of companies had to evolve, both in an organizational sense and a technical sense. Organizationally, they changed the way they managed projects and teams in order to shift to agile methodologies, and technically, technologies such as cloud computing platforms, containers, virtualization were adopted widely and helped a lot to align technical agility with organizational agility. All of this to ensure more frequent software releases! So, let's focus on this evolution next.
Understanding the organizational shift to agile methodologies
From a purely organizational point of view, agile methodologies such as Scrum, Kanban, and DevOps became the standard way to organize IT teams.
Typical IT departments that do not apply agile methodologies are often made of three different teams, each of them having a single responsibility toward the development and release process life cycle.
Before the adoption of agile methodologies, there was very strong opposition between them:
- The business team: These teams are in charge of explaining the need for a new feature to other teams, especially the developers. Their job is hard because they need to translate business needs into concrete technical features that can be understood by the developers.
- The development team: These teams are in charge of writing the code. First, they take the specs from the business team, and then they implement the software and features. If they do not understand the need, the development of new features can go back and forth between them and the business team, which can lead to a massive loss of time. Even worse, back in the old days, these guys had no clear vision of the type of environment their code would ultimately run on because it was kept at the sole discretion of the operation team.
- The operation team: These teams are in charge of deploying the software to the production servers and operating it. Often, they are not happy when they hear that a new version of a piece of software, which includes new features, has to be deployed because the management judges them on their ability to provide stability to the app. In general, they are here to deploy something that was developed by another team without having a clear vision of what it contains and how it is configured since they did not participate in its development.
These are what we call silos. The roles are clearly defined, people do not work together that much, and when something goes wrong, everyone loses time in an attempt to find the right information from the proper person.
This kind of siloed organization has led to major issues:
- A significantly longer development time
- Greater risk in the deployment of a release that might not work at all in production
And that's essentially what agile methodologies and DevOps broke. The change agile methodologies wrought was to make people work together by creating multidisciplinary teams.
An agile team consists of a product owner describing concrete features by writing them as user stories that are readable by the developers who are working in the same team as them. Developers should have visibility over the production environment and the ability to deploy on top of it, preferably using a continuous integration and continuous deployment (CI/CD) approach. Testers should also be part of agile teams in order to write tests.
Simply put, by adopting agile methodologies and DevOps, these silos were broken and multidisciplinary teams capable of formalizing a need, implementing it, testing it, releasing it, and maintaining it in the production environment were created.
Important Note
Rest assured, even though we are currently discussing agile methodologies and the whole internet in a lot of detail, this book is really about Kubernetes! We just need to explain some of the problems that we have faced before introducing Kubernetes for real!
Agile development teams are complete operational units that are capable of handling all development steps on their own. An agile team should understand the business value brought by a new feature. They should have a minimal view of the software architecture, understand how to build it, how to test it, and the production environment it will run on.
That's the purpose of the expression You Build It, You Run It that you'll see everywhere when reading about this subject: an agile team should be able to cover all aspects of an app's development, release, and maintenance life cycles.
You just have to bear in mind that before this, teams were siloed and each had its own scope and working process. So, we've covered the organizational transition brought by the adoption of the agile methodologies, now let's discuss the technical evolution that we've gone through over the past several years.
Understanding the shift from on-premises to the cloud
Having agile teams is very nice. But agility must also be applied to how the software is built and hosted.
With the aim to always achieve faster and more recurrent releases, agile software development teams had to revise two important aspects of software development and release:
- Hosting
- Software architecture
Today, apps are not just for a few hundred users but potentially for millions of users concurrently. Having more users on the internet also means having more computing power capable of handling them. And indeed, hosting an application became a very big challenge.
Back in the old days, there were two ways to get machines to host your apps. We call this on-premises hosting:
- Renting servers from established hosting providers
- Building your own data center, only for companies willing to invest a large amount of money in data centers
When your user base grows, the need to get more powerful machines to handle the load. The solution is to purchase a more powerful server and install your app on it from the start or to order and rack new hardware if you manage your data center. This is not very flexible. Today, a lot of companies are still using an on-premises solution, and often, it's not super flexible.
The game-changer was the adoption of the public cloud, which is the opposite of on-premises. The whole idea behind cloud computing is that big companies such as Amazon, Google, and Microsoft, which own a lot of data centers, decided to build virtualization on top of their massive infrastructure to ensure the creation and management of virtual machines was accessible by APIs. In other words, you can get virtual machines with just a few clicks or just a few commands.
Understanding why the cloud is well suited for scalability
Today, virtually anyone can get hundreds or thousands of servers, in just a few clicks, in the form of virtual machines or instances created on physical infrastructure maintained by cloud providers such as Amazon Web Services, Google Cloud Platform, and Microsoft Azure. A lot of companies decided to migrate their workload from on-premises to a cloud provider, and their adoption has been massive over these last years.
Thanks to that, now, computing power is one of the simplest things you can get.
Cloud computing providers are now typical hosting solutions that agile teams possess in their arsenal. The main reason for this is that the cloud is extremely well suited to modern development.
Virtual machine configurations, CPUs, OSes, network rules, and more are publicly displayed and fully configurable, so there are no secrets for your team in terms of what the production environment is made of. Because of the programmable nature of cloud providers, it is very easy to replicate a production environment in a development or testing environment, providing more flexibility to teams and helping them face their challenges when developing software.
That's a useful advantage for an agile development team built around the DevOps philosophy that needs to manage development, release, and application maintenance in production.
Cloud providers have brought many benefits, as follows:
- Offering elasticity and scalability
- Helping to break up silos and enforcing agile methodologies
- Fitting well with agile methodologies and DevOps
- Offering low costs and flexible billing models
- Ensuring there is no need to manage physical servers
- Allowing virtual machines to be destroyed and recreated at will
- More flexible compared to renting a bare-metal machine monthly
Due to these benefits, the cloud is a wonderful asset in the arsenal of an agile development team. Essentially, you can build and replicate a production environment over and over without the hassle of managing the physical machine by yourself. The cloud enables you to scale your app based on the number of users using it or the computing resources they are consuming. You'll make your app highly available and fault-tolerant. The result is a better user experience for your end users.
Important Note
Please note that Kubernetes can run both on the cloud and on-premises. Kubernetes is very versatile, and you can even run it on a Raspberry Pi. However, you'll discover that it's better to run it on a cloud due to the benefits they provide. Kubernetes and the public cloud are a good match, but you are not required or forced to run it on the cloud.
Now that we have explained what the cloud brought, let's move on to software architecture, as over the years, a few things have also changed there.
Essentially, software architecture consists of design paradigms that you can choose when developing software. In the 2020s, we can name two architectures:
- Monolithic architecture
- Microservices architecture
Exploring the monolithic architecture
In the past, applications were mostly composed as monoliths. A typical monolith application consists of a simple process, a single binary, or a single package.
This unique component is responsible for the entire implementation of the business logic, to which the software must respond. Monoliths are a good choice if you want to develop fairly simple applications that might not necessarily be updated frequently in production. Why? Well, because monoliths have one major drawback. If your monolith becomes unstable or crashes for some reason, your entire application will become unavailable:

Figure 1.1 – A monolith application consists of one big component that contains all your software
The monolithic architecture can allow you to gain a lot of time during your development and that's perhaps the only benefit you'll find by choosing this architecture. However, it also has many disadvantages. Here are a few of them:
- A failed deployment to production can break your whole application.
- Scaling activities become difficult to achieve; if you fail to scale, all your applications might become unavailable.
- A failure of any kind on a monolith can lead to the complete outage of your app.
In the 2010s, these drawbacks started to cause real problems. With the increase in the frequency of deployments, it became necessary to think of a new architecture that would be capable of supporting frequent deployments and closer update cycles, while reducing the risk or general unavailability of the application. This is why the microservices architecture was designed.
Exploring the microservices architecture
The microservices architecture consists of developing your software application as a suite of independent micro-applications. Each of these applications, which is called a microservice, has its own versioning, life cycle, environment, and dependencies. Additionally, it can have its own deployment life cycle. Each of your microservices must only be responsible for a limited number of business rules, and all of your microservices, when used together, make up the application. Think of a microservice as real full-featured software on its own, with its own life cycle and versioning process.
Since microservices are only supposed to hold a subset of all the features that the entire application has, they have to be accessible to expose their functions. You have to get data from a microservice, but you might also want to push data into it. You can make your microservice accessible through widely supported protocols such as HTTP or AMQP, and they need to be able to communicate with each other if needed.
That's why microservices are generally built as web services that are accessible through HTTP REST APIs. This is something that greatly differs from the monolithic architecture:
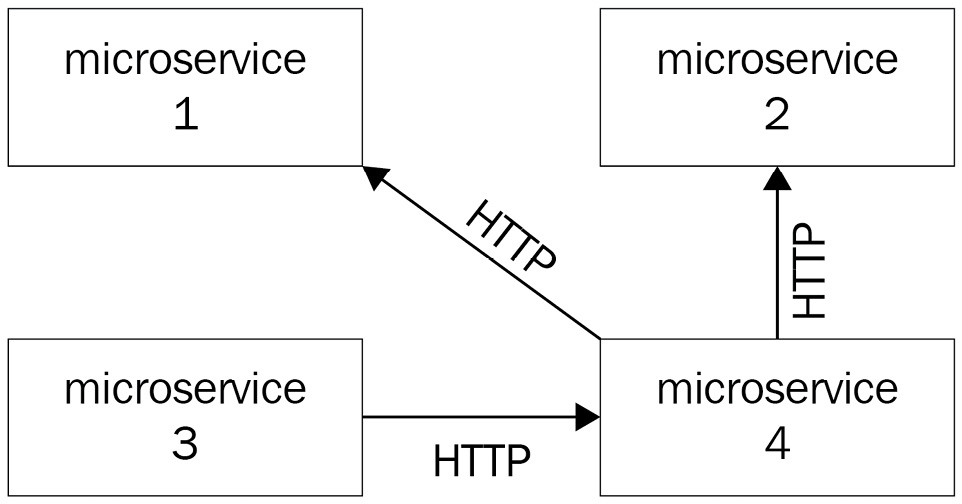
Figure 1.2 – A microservice architecture where different microservices communicate with the HTTP protocol
Another key aspect of the microservice architecture is that microservices need to be decoupled: if a microservice becomes unavailable or unstable, it must not affect the other microservices nor the entire application's stability. You must be able to provision, scale, start, update, or stop each microservice independently without affecting anything else. If your microservices need to work with a database engine, bear in mind that even the database must be decoupled. Each microservice should have its own SQL database and so on. So, if the database of microservice A crashes, it won't affect microservice B:

Figure 1.3 – A microservice architecture where different microservices communicate with the HTTP protocol and also with a dedicated SQL server; this way, the microservices are isolated and have no common dependencies
The key rule is to decouple as much as possible so that your microservices are fully independent. Because they are meant to be independent, microservices can also have completely different technical environments and be implemented in different languages. You can have one microservice implemented in Go, another one in Java, and another one in PHP, and all together they form one application. In the context of a microservice architecture, this is not a problem. Because HTTP is a standard, they will be able to communicate with each other even if their underlying technologies are different.
Microservices must be decoupled from other microservices, but they must also be decoupled from the operating system running them. Microservices should not operate at the host system level but at the upper level. You should be able to provision them, at will, on different machines without needing to rely on a strong dependency with the host system; that's why microservice architectures and containers are a good combination.
If you need to release a new feature in production, you simply deploy the microservices that are impacted by the new feature version. The others can remain the same.
As you can imagine, the microservice architecture has tremendous advantages in the context of modern application development:
- It is easier to enforce recurring production deliveries with minimal impact on the stability of the whole application.
- You can only upgrade to a specific microservice each time, not the whole application.
- Scaling activities are smoother since you might only need to scale specific services.
However, on the other hand, the microservice architecture has a few disadvantages, too:
- The architecture requires more planning and is considered to be hard to develop.
- There are problems in managing each microservice's dependencies.
Indeed, microservice applications are considered hard to develop, and it is easy to just do it incorrectly. This approach might be hard to understand, especially for junior developers. On the other hand, dependency management also becomes complex since all microservices can potentially have different dependencies.
Choosing between monolithic and microservices architectures
Presented in this way, you might think that microservices are the better of the two architectures. However, this is not always the case.
Although the monolithic architecture is older than microservice architecture, monolithic applications are not dead yet, and they can still be a good choice in certain situations. Microservices are not necessarily the ideal answer to all projects. If your application is simple, if there are only a few developers on your team working on your project, or if you can tolerate outages when you deploy a new version in production, then you can still opt for an application architecture that is a monolith.
On the other hand, if your application is more complex, if there are many developers with different skills on your team, or if you have a high level of requirements in terms of operational quality in production, scalability, and availability, then you should opt for a microservice architecture.
The problem is that microservices are slightly more complex to develop and manage in production since managing microservices essentially consists of managing multiple applications that each have their own dependencies and life cycles. Thankfully, the rise of Docker has enabled a lot of developers to adopt the microservice architecture.
Understanding containers and Docker
Following this comparison between monolithic and microservice architectures, you should have understood that the architecture that best combines with agility and DevOps is the microservice architecture. It is this architecture that we will discuss throughout the book because this is the architecture that Kubernetes manages well.
Now, we will move on to discuss how Docker, which is a container engine for Linux, is a good option in which to manage microservices. If you already know a lot about Docker, you can skip this section. Otherwise, I suggest that you read through it carefully.
Understanding why Docker is good for microservices
Recall the two important aspects of the microservice architecture:
- Each microservice can have its own technical environment and dependency.
- At the same time, it must be decoupled from the operating system it's running on.
Let's put the latter point aside for the moment and discuss the first one: two microservices of the same app can be developed in two different languages or be written in the same language but as two different versions. Now, let's say that you want to deploy these two microservices inside the same Linux machine. That would be a nightmare.
The reason for this is that you'll have to install all the multiple versions of the different runtimes, as well as the dependencies, and there might also be different versions or overlaps between the two microservices. Additionally, all of this will be on the same host operating system. Now, let's imagine you want to remove one of these two microservices from the machine to deploy it on another server and clean the former machine of all the dependencies used by that microservice. Of course, if you are a talented Linux engineer, you'll succeed in doing this. However, for most people, the risk of conflict between the dependencies is huge, and in the end, you might just make your app unavailable while running such a nightmarish infrastructure.
There is a solution to this: you could build a machine image for each microservice and then put each microservice on a dedicated virtual machine. In other words, you refrain from deploying multiple microservices on the same machine. However, in this example, you will need as many machines as you have microservices. Of course, with the help of AWS or GCP, it's going to be easy to bootstrap tons of servers, each of them tasked to run one and only one microservice, but it would be a huge waste of money to not mutualize the computing power offered by the host.
That's why the second requirement exists: microservices should be decoupled from the microservice they are running on. To achieve this, we use Docker containers.
Understanding the benefit of Docker container isolation
Docker allows you to manage containers that are, in fact, isolated Linux namespaces. Docker's job is to expose a user-friendly API to manage containers, which are like small virtual machines that run on top of the Linux kernel, not at the hypervisor level. By installing Docker on top of your Linux system, you, therefore, add an additional layer of virtualization on top of your host machine. Your microservices are going to be launched on top of this layer, not directly on the host system, whose sole role will be to run Docker.
Since containers are isolated, you can run as many containers as you want and have them run applications written in different languages without any conflict. Microservice relocation becomes as easy as stopping a running container and launching another one from the same image on another machine.
The usage of Docker with microservices offers three main benefits:
- It reduces the footprint on the host system.
- It mutualizes the host system without the conflict between different microservices.
- It removes coupling between the microservice and the host system.
Once a microservice has been containerized, you can eliminate its coupling with the host operating system. The microservice will only depend on the container in which it will operate. Since a container is much lighter than a real full-featured Linux operating system, it will be easy to share and deploy on many different machines. Therefore, the container and your microservice will work on any machine that is running Docker.
The following diagram shows a microservice architecture where each microservice is actually wrapped by a Docker container:
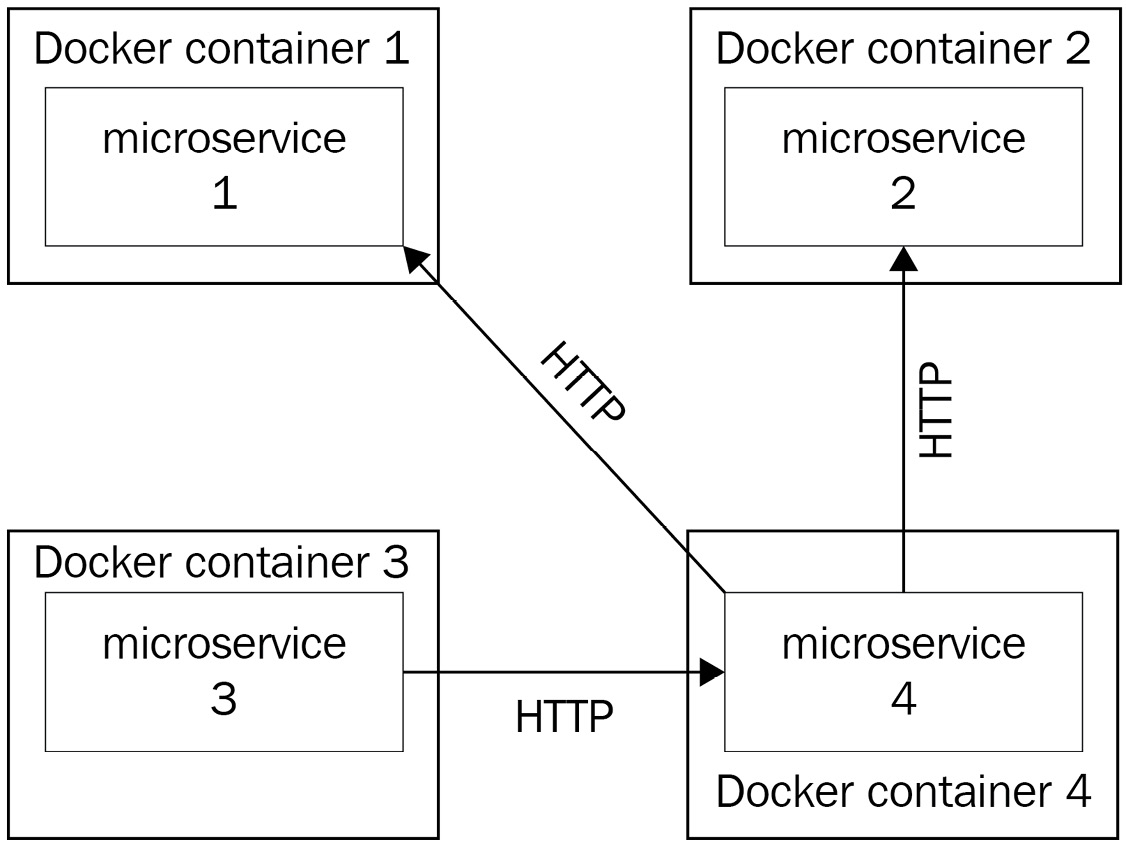
Figure 1.4 – A microservice application where all microservices are wrapped by a Docker container; the life cycle of the app becomes tied to the container, and it is easy to deploy it on any machine that is running Docker
Docker fits well with the DevOps methodology, too. By developing locally in a Docker container, which would be later be built and deployed in production, you ensure you develop in the same environment as the one that will eventually run the application.
Docker is not only capable of managing the life cycle of a container, it is actually an entire ecosystem around containers. It can manage networks, the intercommunication between different containers, and all of these features respond particularly well to the properties of the microservice architecture that we mentioned earlier.
By using the cloud and Docker together, you can build a very strong infrastructure to host your microservice. The cloud will give you as many machines as you want. You simply need to install Docker on each of them, and you'll be able to deploy multiple containerized microservices on each of these machines.
Docker is a very nice tool on its own. However, you'll discover that it's hard to run it in production alone, just as it is. The reason is that Docker was built in order to be an ecosystem around Linux containers, not a production platform. When it comes to production, everything is particular, because it is the concrete environment where everything happens for real. This environment deserves special treatment, and deploying Docker on it is risky. This is because Docker cannot alone address the particular needs that are related to production.
There are a number of questions, such as how to relaunch a container that failed automatically and how to autoscale my container based on its CPU utilization, that Docker alone cannot answer. This is the reason why some people were afraid to run Docker-based workloads in production a few years ago.
To answer these questions, we will need a container orchestrator, such as the one discussed in this book: Kubernetes.
How can Kubernetes help you to manage your Docker containers?
Now, we will focus a little bit more on Kubernetes, which is the purpose of this book. Here, we're going to discover that Kubernetes was meant to use container runtimes in production, by answering operational needs mandatory for production.
Understanding that Kubernetes is meant to use Docker in production
If you open the official Kubernetes website (at https://kubernetes.io), the title you will see is Production-Grade Container Orchestration:

Figure 1.5 – The Kubernetes home page showing the header and introducing Kubernetes as a production container orchestration platform
These four words perfectly sum up what Kubernetes is: it is a container orchestration platform for production. Kubernetes does not aim to replace Docker nor any of the features of Docker; rather, it aims to help us to manage clusters of machines running Docker. When working with Kubernetes, you use both Kubernetes and the full-featured standard installations of Docker.
The title refers to production. Indeed, the concept of production is absolutely central to Kubernetes: it was thought and designed to answer modern production needs. Managing production workloads is different today compared to what it was in the 2000s. Back in the 2000s, your production workload would consist of just a few bare metal servers, if not a single one on-premises. These servers mostly ran monoliths directly installed on the host Linux system. However, today, thanks to public cloud platforms such as Amazon Web Services (AWS) or Google Cloud Platform (GCP), anyone can now get hundreds or even thousands of machines in the form of instances or virtual machines with just a few clicks. Even better, we no longer deploy our applications on the host system but as containerized microservices on top of the Docker engine instead, thereby reducing the footprint of the host system.
A problem will arise when you have to manage Docker installations on each of these virtual machines on the cloud. Let's imagine that you have 10 (or 100 or 1,000) machines launched on your preferred cloud and you want to achieve a very simple task: deploy a containerized Docker app on each of these machines.
You could do this by running the docker run command on each of your machines. It would work, but of course, there is a better way to do it. And that's by using a container orchestrator such as Kubernetes. To give you an extremely simplified vision of Kubernetes, it is actually a REST API that keeps a registry of your machines executing a Docker daemon.
Again, this is an extremely simplified definition of Kubernetes. In fact, it's not made of a single centralized REST API, because as you might have gathered, Kubernetes itself was built as a suite of microservices.
Exploring the problems that Kubernetes solves
You can imagine that launching containers on your local machine or a development environment is not going to require the same level of planning as launching these same containers on remote machines, which could face millions of users. Problems specific to production will arise, and Kubernetes is a top solution with which to address these problems when using containers in production:
- Ensuring high availability
- Handling release management and container deployments
- Autoscaling containers
Ensuring high availability
High availability is the central principle of production. This means that your application should always remain accessible and should never be down. Of course, it's utopian. Even the biggest companies such as Google or Amazon are experiencing outages. However, you should always bear in mind that this is your goal. Microservice architecture is a way to mitigate the risk of a total outage in the event of a failure. Using microservices, the failure of a single microservice will not affect the overall stability of the application. Kubernetes includes a whole battery of functionality to make your Docker containers highly available by replicating them on several host machines and monitoring their health on a regular and frequent basis.
When you deploy Docker containers, the accessibility of your application will directly depend on the health of your containers. Let's imagine that for some reason, a container containing one of your microservice becomes inaccessible; how can you automatically guarantee that the container is terminated and recreated using only Docker without Kubernetes? This is impossible because, by default, Docker cannot do it alone. With Kubernetes, it becomes possible. Kubernetes will help you design applications that can automatically repair themselves by performing automating tasks such as health checking and container replacement.
If one machine in your cluster were to fail, all of the containers running on it would disappear. Kubernetes would immediately notice that and reschedule all of the containers on another machine. In this way, your applications will become highly available and fault-tolerant as well.
Release management and container deployment
Deployment management is another of these production-specific problems that Kubernetes answers. The process of deployment consists of updating your application in production in order to replace an old version of a given microservice with a new version.
Deployments in production are always complex because you have to update the containers that are responding to requests from end users. If you miss them, the consequences can be great for your application because it could become unstable or inaccessible, which is why you should always be able to quickly revert to the previous version of your application by running a rollback. The challenge of deployment is that it needs to be performed in the least visible way to the end user, with as little friction as possible.
When using Docker, each release is preceded by a build process. Indeed, before releasing a new container, you have to build a new Docker image containing the new version. A Docker image is a kind of template used by Docker to launch containers. A container can be considered a running instance of a Docker image.
Important Note
The Docker build process has absolutely nothing to do with Kubernetes: it's pure Docker. Kubernetes will come into play later when you'll have to deploy new containers based on a newly built image.
Triggering a build is straightforward. Perform the following steps:
- You just need to run the
docker buildcommand:$ docker build .
- Docker reads build instructions from the
Dockerfilefile inside the.directory and starts the build process. - The build completes.
- The resulting image is stored on the local machine where the build ran.
- Then, you push the new image to a Docker repository with a specific tag to identify the software version included in the new image.
Once the push has been completed, another process starts, that is, the deployment. To deploy a containerized Docker app, you simply need to pull the image from the machine where you want to run it and then run a docker run command.
This is what you'll need to do to release a new version of your containerized software, and this is exactly where things can become hard if you don't use an orchestrator such as Kubernetes.
The next step to achieve the release is to delete the existing container and replace it with new containers created from this new image.
Without Kubernetes, you'll have to run a docker run command on the machine where you want to deploy a new version of the container and destroy the container containing the old version of the application. Then, you will have to repeat this operation on each server that runs a copy of the container. It should work, but it is extremely tedious since it is not automated. And guess what? Kubernetes can automate this for you.
Kubernetes has features that allow it to manage deployments and rollbacks of Docker containers, and this will make your life a lot easier when responding to this problem. With a single command, you can ask Kubernetes to update your containers on all of your machines. Here is the command, which we'll learn later, that allows you to do that:
$ kubectl set image deploy/myapp myapp_container=myapp:1.0.0 # Meaning of the command # kubectl set image <deployment_name> <container_name>=<docker_image>:<docker_tag>
On a real Kubernetes cluster, this command will update the container called myapp_container, which is running as part of the application called myapp, on every single machine where myapp_container runs to the 1.0.0 tag.
Whether it has to update one container running on one machine or millions over multiple data centers, this command works the same. Even better, it ensures high availability.
Remember that the goal is always to meet the requirement of high availability; a deployment should not cause your application to crash or cause a service disruption. Kubernetes is natively capable of managing deployment strategies such as rolling updates aimed at avoiding service interruptions.
Additionally, Kubernetes keeps in memory all the revisions of a specific deployment and allows you to revert to a previous version with just one command. It's an incredibly powerful tool that allows you to update a cluster of Docker containers with just one command.
Autoscaling containers
Scaling is another production-specific problem that has been widely democratized through the use of public clouds such as Amazon Web Services (AWS) and Google Cloud Platform (GCP). Scaling is the ability to adapt your computing power to the load you are facing – again to meet the requirement of high availability. Never forget that the goal is to avoid outages and downtime.
When your production machines are facing a traffic spike and one of your containers is no longer able to cope with the load, you need to find a way in which to identify the failing container. Decide whether you wish to scale it vertically or horizontally; otherwise, if you don't act and the load doesn't decrease, your container or even the host machine will eventually fail, and your application might become inaccessible:
- Vertical scaling: This allows your container to use more computing power offered by the host machine.
- Horizontal scaling: You can duplicate your container to another machine, and you can load balance the traffic between the two containers.
Again, Docker is not able to respond to this problem alone; however, when you manage your Docker with Kubernetes, it becomes possible. Kubernetes is capable of managing both vertical and horizontal scaling automatically. It does this by letting your containers consume more computing power from the host or by creating additional containers that can be deployed on another node on the cluster. And if your Kubernetes cluster is not capable of handling more containers because all your nodes are full, Kubernetes will even be able to launch new virtual machines by interfacing with your cloud provider in a fully automated and transparent manner by using a component called a Cluster Autoscaler.
Important Note
The Cluster Autoscaler only works if the Kubernetes cluster is deployed on a cloud provider.
These goals cannot be achieved without using a container orchestrator. The reason for this is simple. You can't afford to do these tasks; you need to think about DevOps' culture and agility and seek to automate these tasks so that your applications can repair themselves, be fault-tolerant, and be highly available.
Contrary to scaling out your containers or cluster, you must also be able to decrease the number of containers if the load starts to decrease in order to adapt your resources to the load, whether it is rising or falling. Again, Kubernetes can do this, too.
When and where is Kubernetes not the solution?
Kubernetes has undeniable benefits; however, it is not always advisable to use it as a solution. Here, we have listed several cases where another solution might be more appropriate:
- Container-less architecture: If you do not use a container at all, Kubernetes won't be of any use to you.
- Monolithic architecture: While you can use Kubernetes to deploy containerized monoliths, Kubernetes shows all of its potential when it has to manage a high number of containers. A monolithic application, when containerized, often consists of a very small number of containers. Kubernetes won't have much to manage, and you'll find a better solution for your use case.
- A very small number of microservices or applications: Kubernetes stands out when it has to manage a large number of containers. If your app consists of two to three microservices, a simpler orchestrator might be a better fit.
- No cluster: Are you only running one machine and only one Docker installation? Kubernetes is good at managing a cluster of computers that executes a Docker daemon. If you do not plan to manage a real cluster, then Kubernetes is not for you.
Understanding the history of Kubernetes
To finish this chapter, let's discuss the history of the Kubernetes project. It will be really useful for you to understand the context in which the Kubernetes project started and the people who are keeping this project alive.
Understanding how and where Kubernetes started
Kubernetes started as an internal project at Google. Since its founding in 1998, Google gained huge experience in managing high-demanding workloads at scale, especially container-based workloads. Today, in addition to Google, Amazon and Microsoft are also releasing a lot of open source and commercial software to allow smaller companies to benefit from their experience of managing cloud-native applications. Kubernetes is one example of this open source software that has been released by Google.
At Google, everything has been developed as Linux containers since the mid-2000s. The company understood the benefit of using containers long before Docker made them simple to use for the general public. Essentially, everything at Google runs as a container. And they are undoubtedly the first to have felt the need to develop an orchestrator that would allow them to manage their container-based resources along with the machines that launch them. This project is called Borg, and you can consider it to be the ancestor of Kubernetes. Another container orchestrator project, called Omega, was then started by Google in order to improve the architecture of Borg to make it easier to extend and become more robust. Many of the improvements brought by Omega were later merged into Borg.
Important Note
Borg is actually not the ancestor of Kubernetes because the project is not dead and is still in use at Google. It would be more appropriate to say that a lot of ideas from Borg were actually reused to make Kubernetes. Bear in mind that Kubernetes is not Borg nor Omega. Borg was built in C++ and Kubernetes in Go. In fact, they are two entirely different projects, but one is heavily inspired by the other. This is important to understand: Borg and Omega are two internal Google projects. They were not built for the public.
As the interest in containers became greater during the early 2010s, Google decided to develop and release a third container orchestrator. This time, it was meant to be an open source one that was built for the public. Therefore, Kubernetes was born and would eventually be released in 2014.
Kubernetes was developed with the experience gained by Google to manage containers in production. Most importantly, it inherited Borg and Omega's ideas, concepts, and architectures. Here is a brief list of ideas and concepts taken from Borg and Omega, which have now been implemented in Kubernetes:
- The concept of pods to manage your containers: Kubernetes uses a logical object, called a pod, to create, update, and delete your containers.
- Each pod has its own IP address in the cluster.
- There are distributed components that all watch the central Kubernetes API in order to retrieve the cluster state.
- There is internal load balancing between pods and services.
- Labels and selectors are two metadata used together to build interaction between Kubernetes
That's why Kubernetes is so powerful when it comes to managing containers in production at scale: in fact, the concepts you'll learn in Kubernetes are older than Kubernetes itself. They have existed for more than a decade, running Google's entire infrastructure as part of Borg and Omega. So, although Kubernetes is a young project, it was built on solid foundations.
Who manages Kubernetes today?
Kubernetes is no longer maintained by Google. They gave Kubernetes to an organization called Cloud Native Computing Foundation (CNCF), which is a big consortium whose goal is to promote the usage of container technologies. This happened in 2018.
Google is a founding member of CNCF along with companies such as Cisco, Red Hat, and Intel. The Kubernetes source code itself is hosted on GitHub and is an extremely active project on the platform. The code is under License Apache version 2.0, which is a permissive open source license. You won't have to pay in order to use Kubernetes, as the software is available for free, and if you are good at coding with Go, you can even contribute to the code.
Where is Kubernetes today?
Kubernetes has a lot of competitors, and some of them are open source, too. Others are bound to a specific cloud provider. We can name a few, as follows:
- Apache Mesos
- Hashicorp Nomad
- Docker Swarm
- Amazon ECS
These container orchestrators all have their pros and cons, but it's fair to say that Kubernetes is, by far, the most popular of them all.
Kubernetes has won the fight of popularity and adoption and is really about to become the de facto standard way of deploying container-based workloads in production. As its immense growth made it one of the hottest topics in IT industry, it has become crucial for cloud providers to come up with a Kubernetes offering as part of their services. Therefore, Kubernetes is supported almost everywhere now.
The following Kubernetes-based services can help you to get a Kubernetes cluster up and running with just a few clicks:
- Google GKE
- Amazon EKS
- Microsoft Azure AKS
- Alibaba ACK
It's not just about the cloud offerings. It's also about the Platform-as-a-Service market. Recently, Red Hat OpenShift decided to rewrite their entire platform to rebuild it on Kubernetes. Now they are offering a complete set of enterprise tools to build, deploy, and manage Docker containers entirely on top of Kubernetes. In addition to this, other projects such as Rancher were built as Kubernetes distributions to offer a complete set of tools around the Kubernetes orchestrator, whereas projects such as Knative offers to manage serverless workloads with the Kubernetes orchestrator.
Important Note
AWS is an exception because it has two container orchestrator services. The first one is Amazon ECS, which is entirely made by AWS and is a competitor to Kubernetes. The second one is Amazon EKS, which was released later than the first one and is a complete Kubernetes offering on AWS. These services are not the same, so do not be misguided by their similar names.
Learning Kubernetes today is one of the smartest decisions you can take if you are into managing cloud-native applications in production. Kubernetes is evolving rapidly, and there is no reason to think why its growth would stop.
By mastering this wonderful tool, you'll get one of the hottest skills being searched for in the IT industry today. I hope you are now convinced!
Summary
This first chapter gave us room for a big introduction. We covered a lot of subjects, such as monoliths, microservices, Docker containers, cloud computing, and Kubernetes. We also discussed how this project came to life. You should now have a global vision of how Kubernetes can be used to manage your containers in production.
In the next chapter, we will discuss the process Kubernetes follows to launch a Docker container. You will discover that you can issue commands to Kubernetes, and these commands will be interpreted by Kubernetes as instructions to run containers. We will list and explain each component of Kubernetes and its role in the whole cluster. There are a lot of components that make up a Kubernetes cluster, and we will discover all of them. We will explain how Kubernetes was technically built with a focus on the distinction between master nodes, worker nodes, and control plane components.


