


















 Download code from GitHub
Download code from GitHub
Chapter 1: Machine Learning Fundamentals
For many decades, researchers have been trying to simulate human brain activity through the field known as artificial intelligence, AI for short. In 1956, a group of people met at the Dartmouth Summer Research Project on Artificial Intelligence, an event that is widely accepted as the first group discussion about AI as we know it today. Researchers were trying to prove that many aspects of the learning process could be precisely described and, therefore, automated and replicated by a machine. Today, we know they were right!
Many other terms appeared in this field, such as machine learning (ML) and deep learning (DL). These sub-areas of AI have also been evolving for many decades (granted, nothing here is new to the science). However, with the natural advance of the information society and, more recently, the advent of big data platforms, AI applications have been reborn with much more power and applicability. Power, because now we have more computational resources to simulate and implement them; applicability, because now information is everywhere.
Even more recently, cloud services providers have put AI in the cloud. This is helping all sizes of companies to either reduce their operational costs or even letting them sample AI applications (considering that it could be too costly for a small company to maintain its own data center).
That brings us to the goal of this chapter: being able to describe what the terms AI, ML, and DL mean, as well as understanding all the nuances of an ML pipeline. Avoiding confusion on these terms and knowing what exactly an ML pipeline is will allow you to properly select your services, develop your applications, and master the AWS Machine Learning Specialty exam.
The main topics of this chapter are as follows:
- Comparing AI, ML, and DL
- Classifying supervised, unsupervised, and reinforcement learning
- The CRISP-DM modeling life cycle
- Data splitting
- Modeling expectations
- Introducing ML frameworks
- ML in the cloud
Comparing AI, ML, and DL
AI is a broad field that studies different ways to create systems and machines that will solve problems by simulating human intelligence. There are different levels of sophistication to create these programs and machines, which go from simple, rule-based engines to complex, self-learning systems. AI covers, but is not limited to, the following sub-areas:
- Robotics
- Natural language processing
- Rule-based systems
- ML
The area we are particularly interested in now is ML.
Examining ML
ML is a sub-area of AI that aims to create systems and machines that are able to learn from experience, without being explicitly programmed. As the name suggests, the system is able to observe its running environment, learn, and adapt itself without human intervention. Algorithms behind ML systems usually extract and improve knowledge from the data that is available to them, as well as conditions (such as hyperparameters), and feed back after trying different approaches to solve a particular problem:
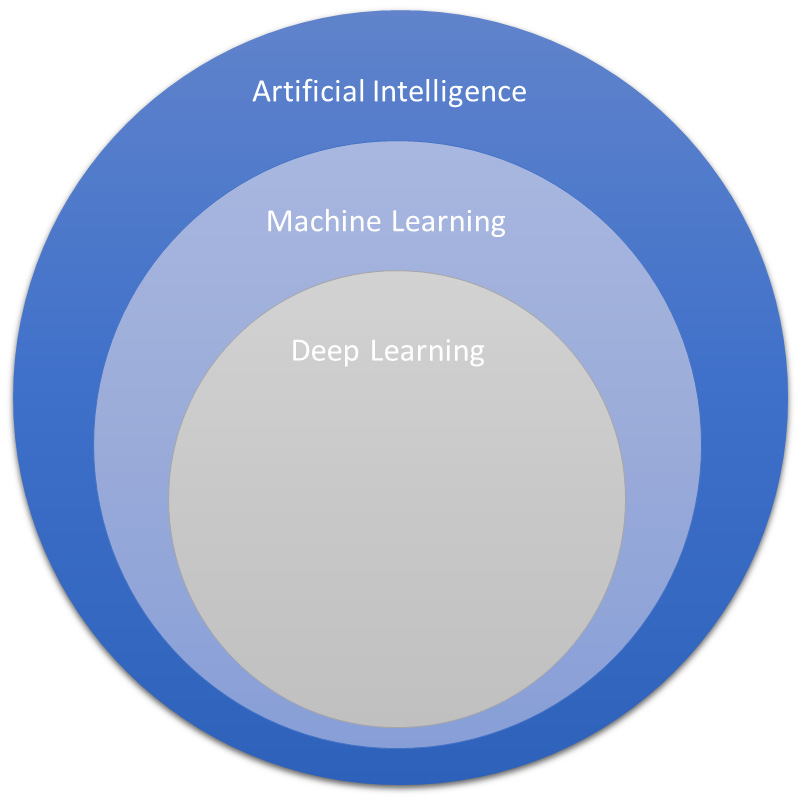
Figure 1.1 – Heirarchy of AI, ML, DL
There are different types of ML algorithms; for instance, we can list decision tree-based, probabilistic-based, and neural networks. Each of these classes might have dozens of specific algorithms. Most of them will be covered in later sections of this book.
As you might have noticed in Figure 1.1, we can be even more specific and break the ML field down into another very important topic for the Machine Learning Specialty exam: DL.
Examining DL
DL is a subset of ML that aims to propose algorithms that connect multiple layers to solve a particular problem. The knowledge is then passed through layer by layer until the optimal solution is found. The most common type of DL algorithm is deep neural networks.
At the time of writing this book, DL is a very hot topic in the field of ML. Most of the current state-of-the-art algorithms for machine translation, image captioning, and computer vision were proposed in the past few years and are a part of DL.
Now that we have an overview of types of AI, let's look at some of the ways we can classify ML.
Classifying supervised, unsupervised, and reinforcement learning
ML is a very extensive field of study; that's why it is very important to have a clear definition of its sub-divisions. From a very broad perspective, we can split ML algorithms into two main classes: supervised learning and unsupervised learning.
Introducing supervised learning
Supervised algorithms use a class or label (from the input data) as support to find and validate the optimal solution. In Figure 1.2, there is a dataset that aims to classify fraudulent transactions from a bank:
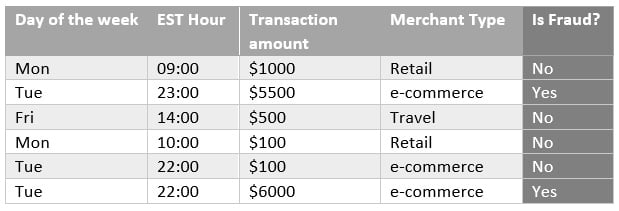
Figure 1.2 – Sample dataset for supervised learning
The first four columns are known as features, or independent variables, and they can be used by a supervised algorithm to find fraudulent patterns. For example, by combining those four features (day of the week, EST hour, transaction amount, and merchant type) and six observations (each row is technically one observation), you can infer that e-commerce transactions with a value greater than $5,000 and processed at night are potentially fraudulent cases.
Important note
In a real scenario, we should have more observations in order to have statistical support to make this type of inference.
The key point is that we were able to infer a potential fraudulent pattern just because we knew, a priori, what is fraud and what is not fraud. This information is present in the last column of Figure 1.2 and is commonly referred to as a target variable, label, response variable, or dependent variable. If the input dataset has a target variable, you should be able to apply supervised learning.
In supervised learning, the target variable might store different types of data. For instance, it could be a binary column (yes or no), a multi-class column (class A, B, or C), or even a numerical column (any real number, such as a transaction amount). According to the data type of the target variable, you will find which type of supervised learning your problem refers to. Figure 1.3 shows how to classify supervised learning into two main groups: classification and regression algorithms:

Figure 1.3 – Choosing the right type of supervised learning given the target variable
While classification algorithms predict a class (either binary or multiple classes), regression algorithms predict a real number (either continuous or discrete).
Understanding data types is important to make the right decisions on ML projects. We can split data types into two main categories: numerical and categorical data. Numerical data can then be split into continuous or discrete subclasses, while categorical data might refer to ordinal or nominal data:
- Numerical/discrete data refers to individual and countable items (for example, the number of students in a classroom or the number of items in an online shopping cart).
- Numerical/continuous data refers to an infinite number of possible measurements and they often carry decimal points (for example, temperature).
- Categorical/nominal data refers to labeled variables with no quantitative value (for example, name or gender).
- Categorical/ordinal data adds the sense of order to a labeled variable (for example, education level or employee title level).
In other words, when choosing an algorithm for your project, you should ask yourself: do I have a target variable? Does it store categorical or numerical data? Answering these questions will put you in a better position to choose a potential algorithm that will solve your problem.
However, what if you don't have a target variable? In that case, we are facing unsupervised learning. Unsupervised problems do not provide labeled data; instead, they provide all the independent variables (or features) that will allow unsupervised algorithms to find patterns in the data. The most common type of unsupervised learning is clustering, which aims to group the observations of the dataset into different clusters, purely based on their features. Observations from the same cluster are expected to be similar to each other, but very different from observations from other clusters. Clustering will be covered in more detail in future chapters of this book.
Semi-supervised learning is also present in the ML literature. This type of algorithm is able to learn from partially labeled data (some observations contain a label and others do not).
Finally, another learning approach that has been taken by another class of ML algorithms is reinforcement learning. This approach rewards the system based on the good decisions that it has made autonomously; in other words, the system learns by experience.
We have been discussing learning approaches and classes of algorithms at a very broad level. However, it is time to get specific and introduce the term model.
The CRISP-DM modeling life cycle
Modeling is a very common term used in ML when we want to specify the steps taken to solve a particular problem. For example, we could create a binary classification model to predict whether those transactions from Figure 1.2 are fraudulent or not.
A model, in this context, represents all the steps to create a solution as a whole, which includes (but is not limited to) the algorithm. The Cross-Industry Standard Process for Data Mining, more commonly referred to as CRISP-DM, is one of the methodologies that provides guidance on the common steps we should follow to create models. This methodology is widely used by the market and is covered in the AWS Machine Learning Specialty exam:
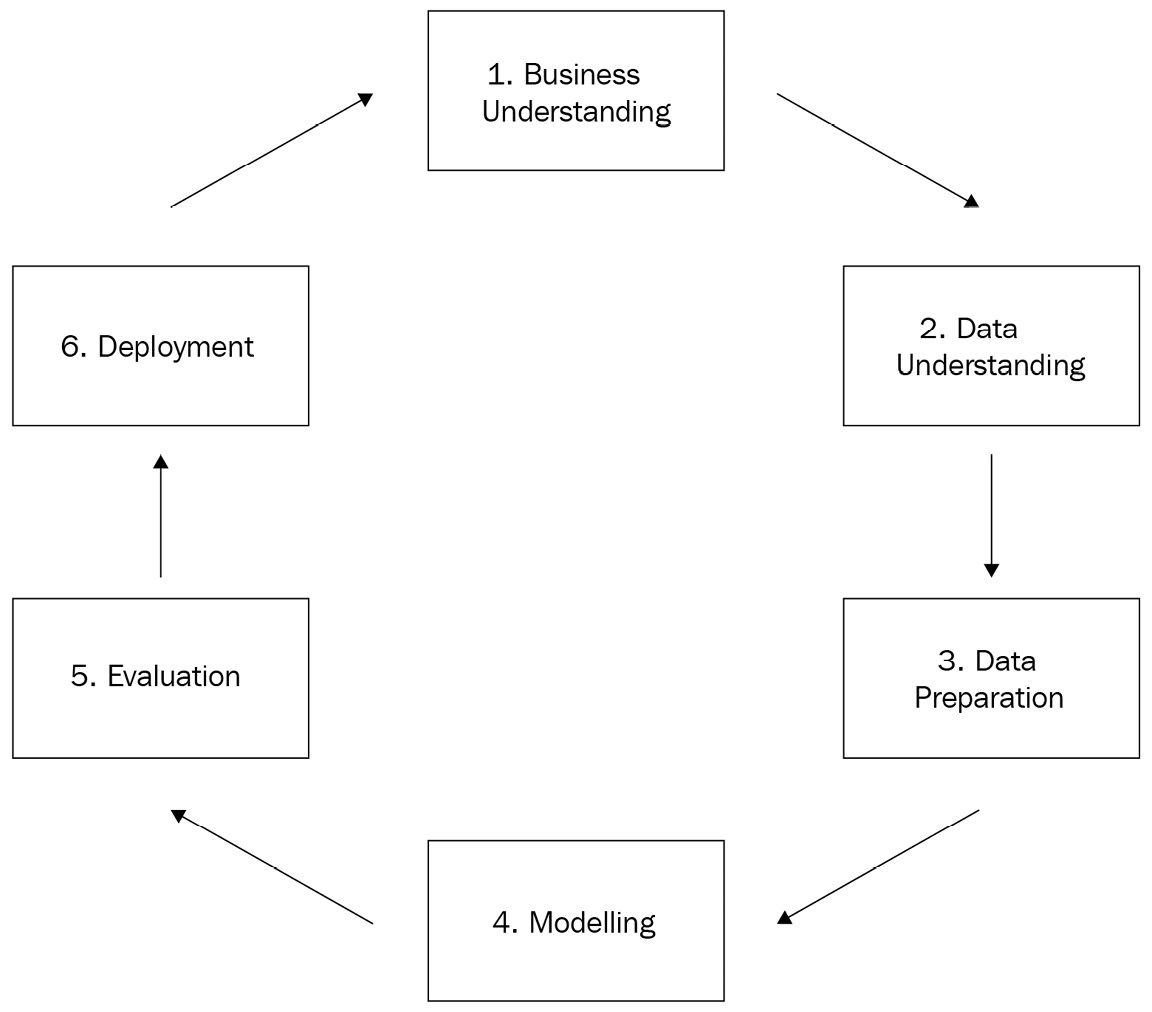
Figure 1.4 – CRISP-DM methodology
Everything starts with business understanding, which will produce the business objectives (including success criteria), situation assessment, data mining goals, and project plan (with an initial assessment of tools and techniques). During the situation assessment, we should also look into an inventory of resources, requirements, assumptions and constraints, risks, terminology, costs, and benefits. Every single assumption and success criterion matters when we are modeling.
Then we pass on to data understanding, where we will collect raw data, describe it, explore it, and check its quality. This is an initial assessment of the data that will be used to create the model. Again, data scientists must be skeptical. You must be sure you understand all the nuances of the data and its source.
The data preparation phase is actually the one that usually consumes most of the time during modeling. In this phase, we need to select and filter the data, clean it according to the task that needs to be performed, come up with new attributes, integrate the data with other data sources, and format it as expected by the algorithm that will be applied. These tasks are often called feature engineering.
Once the data is prepared, we can finally start the modeling phase. Here is where the algorithms come in. We should start by ensuring the selection of the right technique. Remember: according to the presence or absence of a target variable (and its data type), we will have different algorithms to choose from. Each modeling technique might carry some implicit assumptions of which we have to be aware. For example, if you choose a multiple linear regression algorithm to predict house prices, you should be aware that this type of model expects a linear relationship between the variables of your data.
There are hundreds of algorithms out there and each of them might have its own assumptions. After choosing the ones that you want to test in your project, you should spend some time checking their specifics. In later chapters of this book, we will cover some of them.
Important note
Some algorithms incorporate in their logic what we call feature selection. This is a step where the most important features will be selected to build your best model. Decision trees are examples of algorithms that perform feature selection automatically. We will cover feature selection in more detail later on, since there are different ways to select the best variables for your model.
During the modeling phase, you should also design a testing approach for the model, defining which evaluation metrics will be used and how the data will be split. With that in place, you can finally build the model by setting the hyperparameters of the algorithm and feeding the model with data. This process of feeding the algorithm with data to find a good estimator is known as the training process. The data used to feed the model is known as training data. There are different ways to organize the training and testing data, which we will cover in this chapter.
Important note
ML algorithms are built by parameters and hyperparameters. These are learned from the data. For example, a decision-tree-based algorithm might learn from the training data that a particular feature should compose its root level based on information gain assessments. Hyperparameters, on the other hand, are used to control the learning process. Taking the same example about decision trees, we could specify the maximum allowed depth of the tree by specifying a pre-defined hyperparameter of any decision tree algorithm (regardless of the underlining training data). Hyperparameter tuning is a very important topic in the exam and will be covered in fine-grained detail later on.
Once the model is trained, we can evaluate and review results in order to propose the next steps. If results are not acceptable (based on our business success criteria), we should come back to earlier steps to check what else can be done to improve the model results. It can either be a small tuning in the hyperparameters of the algorithm, a new data preparation step, or even a redefinition of business drivers. On the other hand, if the model quality is acceptable, we can move to the deployment phase.
In this last phase of the CRISP-DM methodology, we have to think about the deployment plan, monitoring, and maintenance of the model. We usually look at this step from two perspectives: training and inference. The training pipeline consists of those steps needed to train the model, which includes data preparation, hyperparameter definition, data splitting, and model training itself. Somehow, we must store all the model artifacts somewhere, since they will be used by the next pipeline that needs to be developed: the inference pipeline.
The inference pipeline just uses model artifacts to execute the model against brand-new observations (data that has never been seen by the model during the training phase). For example, if the model was trained to identify fraudulent transactions, this is the time where new transactions will pass through the model to be classified.
In general, models are trained once (through the training pipeline) and executed many times (through the inference pipeline). However, after some time, it is expected that there will be some model degradation, also known as model drift. This phenomenon happens because the model is usually trained in a static training set that aims to represent the business scenario at a given point in time; however, businesses evolve, and it might be necessary to retrain the model on more recent data to capture new business aspects. That's why it is important to keep tracking model performance even after model deployment.
The CRISP-DM methodology is so important to the context of the AWS Machine Learning Specialty exam that, if you look at the four domains covered by AWS, you will realize that they were generalized from the CRISP-DM stages: data engineering, exploratory data analysis, modeling, and ML implementation and operations.
We now understand all the key stages of a modeling pipeline and we know that the algorithm itself is just part of a broad process! Next, let's see how we can split our data to create and validate ML models.
Data splitting
Training and evaluating ML models are key tasks of the modeling pipeline. ML algorithms need data to find relationships among features in order to make inferences, but those inferences need to be validated before they are moved to production environments.
The dataset used to train ML models is commonly called the training set. This training data must be able to represent the real environment where the model will be used; it will be useless if that requirement is not met.
Coming back to our fraud example presented in Figure 1.2, based on the training data, we found that e-commerce transactions with a value greater than $5,000 and processed at night are potentially fraudulent cases. With that in mind, after applying the model in a production environment, the model is supposed to flag similar cases, as learned during the training process.
Therefore, if those cases only exist in the training set, the model will flag false positive cases in production environments. The opposite scenario is also valid: if there is a particular fraud case in production data, not reflected in the training data, the model will flag a lot of false negative cases. False positives and false negatives ratios are just two of many quality metrics that we can use for model validation. These metrics will be covered in much more detail later on.
By this point, you should have a clear understanding of the importance of having a good training set. Now, supposing we do have a valid training set, how could we have some level of confidence that this model will perform well in production environments? The answer is: using testing and validation sets:

Figure 1.5 – Data splitting
Figure 1.5 shows the different types of data splitting that we can have during training and inference pipelines. The training data is the one used to create the model and the testing data is the one used to extract final model quality metrics. The testing data cannot be used during the training process for any reason other than to extract model metrics.
The reason to avoid using the testing data during training is simple: we cannot let the model learn on top of the data that will be used to validate it. This technique of holding one piece of the data for testing is often called hold-out validation.
The box on the right side of Figure 1.5 represents the production data. Production data usually comes in continuously and we have to execute the inference pipeline in order to extract model results from it. No training, nor any other type of recalculation, is performed on top of production data; we just have to pass it through the inference pipeline as it is.
From a technical perspective, most of the ML libraries implement training steps with the .fit method, while inference steps are implemented by the .transform or .predict method. Again, this is just a common pattern used by most ML libraries, but be aware that you might find different name conventions across ML libraries.
Still looking at Figure 1.5, there is another box, close to the training data, named validation data. This is a subset of the training set often used to support the creation of the best model, before moving to the testing phase. We will talk about that box in much more detail, but first, let's explain why we need them.
Overfitting and underfitting
ML models might suffer from two types of fitting issues: overfitting and underfitting. Overfitting means that your model performs very well in the training data, but cannot be generalized to other datasets, such as testing and, even worse, production data. In other words, if you have an overfitted model, it only works on your training data.
When we are building ML models, we want to create solutions that are able to generalize what they have learned and infer decisions on other datasets that follow the same data distribution. A model that only works on the data that it was trained on is useless. Overfitting usually happens due to the large number of features or the lack of configuration of the hyperparameters of the algorithm.
On the other hand, underfitted models cannot fit the data during the training phase. As a result, they are so generic that they can't perform well with the training, testing, or production data. Underfitting usually happens due to the lack of good features/observations or due to the lack of time to train the model (some algorithms need more iterations to properly fit the model).
Both overfitting and underfitting need to be avoided. There are many modeling techniques to work around that. For instance, let's focus on the commonly used cross-validation technique and its relationship with the validation box showed in Figure 1.5.
Applying cross-validation and measuring overfitting
Cross-validation is a technique where we split the training set into training and validation sets. The model is then trained on the training set and tested on the validation set. The most common cross-validation strategy is known as k-fold cross validation, where k is the number of splits of the training set.
Using k-fold cross-validation and assuming the value of k equals 10, we are splitting the train set into 10 folds. The model will be trained and tested 10 times. On each iteration, it uses nine splits for training and leaves one split for testing. After 10 executions, the evaluation metrics extracted from each iteration are averaged and will represent the final model performance during the training phase, as shown in Figure 1.6:

Figure 1.6 – Cross-validation in action
Another common cross-validation technique is known as leave one out cross-validation (LOOCV). In this approach, the model is executed many times and, with each iteration, one observation is separated for testing and all the others are used for training.
There are many advantages of using cross-validation during training:
- We mitigate overfitting in the training data, since the model is always trained on a particular chunk of data and tested on another chunk that hasn't been used for training.
- We avoid overfitting in the test data, since there is no need to keep using the testing data to optimize the model.
- We expose the presence of overfitting or underfitting. If the model performance in the training/validation data is very different from the performance observed in the testing data, something is wrong.
Let's elaborate a little more on the third item on that list, since this is covered in the AWS Machine Learning Specialty exam. Let's assume we are creating a binary classification model, using cross-validation during training and using a testing set to extract final metrics (hold-out validation). If we get 80% accuracy in the cross-validation results and 50% accuracy in the testing set, it means that the model was overfitted to the train set, and cannot be generalized to the test set.
On the other hand, if we get 50% accuracy in the training set and 80% accuracy in the test set, there is a systemic issue in the data. It is very likely that the training and testing sets do not follow the same distribution.
Important note
Accuracy is a model evaluation metric commonly used on classification models. It measures how often the model made a correct decision during its inference process. We have selected this metric just for the sake of example, but be aware that there are many other evaluation metrics applicable for each type of model (which will be covered at the appropriate time).
Bootstrapping methods
Cross-validation is a good strategy to validate ML models, and you should try it in your daily activities as a data scientist. However, you should also know about other resampling techniques available out there. Bootstrapping is one of them.
While cross-validation works with no replacement, a bootstrapping approach works with replacement. With replacement means that, while you are drawing multiple random samples from a population dataset, the same observation might be duplicated across samples.
Usually, bootstrapping is not used to validate models as we do in the traditional cross-validation approach. The reason is simple: since it works with replacement, the same observation used for training could potentially be used for testing, too. This would result in inflated model performance metrics, since the estimator is likely to be correct when predicting an observation that was already seen in the training set.
Bootstrapping is often used by ML algorithms in an embedded way that requires resampling capabilities to process the data. In this context, bootstrapping is not being used to validate the model, but to create the model. Random forest, which will be covered in the algorithms chapter, is one of those algorithms that uses bootstrapping internally for model building.
Designing a good data splitting/sampling strategy is crucial to the success of the model or the algorithm. You should come up with different approaches to split your data, check how the model is performing on each split, and make sure those splits represent the real scenario where the model will be used.
The variance versus bias trade-off
Any ML model is supposed to contain errors. There are three types of errors that we can find on models: bias error, variance error, and unexplained error. The last one, as expected, cannot be explained. It is often related to the context of the problem and the relationships between the variables, and we can't control it.
The other two errors can be controlled during modeling. We usually say that there is a trade-off between bias and variance errors because one will influence the other. In this case, increasing bias will decrease variance and vice versa.
Bias error relates to assumptions taken by the model to learn the target function, the one that we want to solve. Some types of algorithms, such as linear algorithms, usually carry over that type of error because they make a lot of assumptions during model training. For example, linear models assume that the relationship present in the data is linear. Linear regression and logistic regression are types of algorithms that, in general, contain high bias. Decision trees, on the other hand, are types of algorithms that make fewer assumptions about the data and contain less bias.
Variance relates to the difference of estimations that the model performs on different training data. Models with high variance usually overfit to the training set. Decision trees are examples of algorithms with high variance (they usually rely a lot on specifics of the training set, failing to generalize), and linear/logistic regression are examples of algorithms with low variance. It does not mean that decision trees are bad estimators; it just means that we need to prune (optimize) them during training.
That said, the goal of any model is to minimize both bias and variance. However, as already mentioned, each one will impact the other in the opposite direction. For the sake of demonstration, let's use a decision tree to understand how this trade-off works.
Decision trees are nonlinear algorithms and often contain low bias and high variance. In order to decrease variance, we can prune the tree and set the max_depth hyperparameter (the maximum allowed depth of the tree) to 10. That will force a more generic model, reducing variance. However, that change will also force the model to make more assumptions (since it is now more generic) and increase bias.
Shuffling your training set
Now that you know what variance and data splitting are, let's dive a little deeper into the training dataset requirements. You are very likely to find questions around data shuffling in the exam. This process consists of randomizing your training dataset before you start using it to fit an algorithm.
Data shuffling will help the algorithm to reduce variance by creating a more generalizable model. For example, let's say your training represents a binary classification problem and it is sorted by the target variable (all cases belonging to class "0" appear first, then all the cases belonging to class "1").
When you fit an algorithm on this sorted data (especially some algorithms that rely on batch processing), it will take strong assumptions on the pattern of one of the classes, since it is very likely that it won't be able to create random batches of data with a good representation of both classes. Once the algorithm builds strong assumptions about the training data, it might be difficult for it to change them.
Important note
Some algorithms are able to execute the training process by fitting the data in chunks, also known as batches. This approach lets the model learn more frequently, since it will make partial assumptions after processing each batch of data (instead of making decisions only after processing the entire dataset).
On the other hand, there is no need to shuffle the test set, since it will be used only by the inference process to check model performance.
Modeling expectations
So far, we have talked about model building, validation, and management. Let's complete the foundations of ML by talking about a couple of other expectations while modeling.
The first one is parsimony. Parsimony describes models that offer the simplest explanation and fits the best results when compared with other models. Here's an example: while creating a linear regression model, you realize that adding 10 more features will improve your model performance by 0.001%. In this scenario, you should consider whether this performance improvement is worth the cost of parsimony (since your model will become more complex). Sometimes it is worth it, but most of the time it is not. You need to be skeptical and think according to your business case.
Parsimony directly supports interpretability. The simpler your model is, the easier it is to explain it. However, there is a battle between interpretability and predictivity: if you focus on predictive power, you are likely to lose some interpretability. Again, be a proper data scientist and select what is better for your use case.
Introducing ML frameworks
Being aware of some ML frameworks will put you in a much better position to pass the AWS Machine Learning Specialty exam. There is no need to master these frameworks, since this is not a framework-specific certification; however, knowing some common terms and solutions will help you to understand the context of the problems/questions.
scikit-learn is probably the most important ML framework that you should be aware of. This is an open source Python package that provides implementations of ML algorithms such as decision trees, support vector machines, linear regression, and many others. It also implements classes for data preprocessing, for example, one-hot encoding, a label encoder, principal component analysis, and so on. All these preprocessing methods (and many others) will be covered in later sections of this book.
The downside of scikit-learn is the fact that it needs customization to scale up through multiple machines. There is another ML library that is very popular because of the fact that it can handle multiprocessing straight away: Spark's ML library.
As the name suggests, this is an ML library that runs on top of Apache Spark, which is a unified analytical multi-processing framework used to process data on multiple machines. AWS offers a specific service that allows developers to create Spark clusters with a few clicks, known as EMR.
The Spark ML library is in constant development. As of the time of writing, it offers support to many ML classes of algorithms, such as classification and regression, clustering, and collaborative filtering. It also offers support for basic statistics computation, such as correlations and some hypothesis tests, as well as many data transformations, such as one-hot encoding, principal component analysis, min-max scaling, and others.
Another very popular ML framework is known as TensorFlow. This ML framework was created by the Google team and it is used for numerical computation and large-scale ML model development. TensorFlow implements not only traditional ML algorithms, but also DL models.
TensorFlow is considered a low-level API for model development, which means that it can be very complex to develop more sophisticated models, such as transformers, for text mining. As an attempt to facilitate model development, other ML frameworks were built on top of TensorFlow to make it easier. One of these high-level frameworks is Keras. With Keras, developers can create complex DL models with just a few lines of code. More recently, Keras was incorporated into TensorFlow and it can be now called inside the TensorFlow library.
MXNet is another open source DL library. Using MXNet, we can scale up neural network-based models using multiple GPUs running on multiples machines. It also supports different programming languages, such as Python, R, Scala, and Java.
Graphical processing unit (GPU) support is particularly important in DL libraries such as TensorFlow and MXNet. These libraries allow developers to create and deploy neural network-based models with multiple layers. The training process of neural networks relies a lot on matrix operations, which perform much better on GPUs than on CPUs. That's why these DL libraries offer GPU support. AWS also offers EC2 instances with GPU enabled.
These ML frameworks need a special channel to communicate with GPU units. NVIDIA, the most common supplier of GPUs nowadays, has created an API called the Compute Unified Device Architecture (CUDA). CUDA is used to configure GPU units on NVIDIA devices, for example, setting up caching memory and the number of threads needed to train a neural network model. There is no need to master CUDA or GPU architecture for the AWS Machine Learning Specialty exam, but you definitely need to know what they are and how DL models take advantage of them.
Last, but not least, you should also be aware of some development frameworks widely used by the data science community, but not necessarily to do ML. These frameworks interoperate with ML libraries to facilitate data manipulation and calculations. For example, pandas is a Python library that provides data processing capabilities, and NumPy is an open source Python library that provides numerical computing.
These terms and libraries are so incorporated into data scientists' daily routines that they might come up during the exam to explain some problem domain for you. Being aware of what they are will help you to quickly understand the context of the question.
ML in the cloud
ML has gone to the cloud and developers can now use it as a service. AWS has implemented ML services in different levels of abstraction. ML application services, for example, aim to offer out-of-the-box solutions for specific problem domains. AWS Lex is a very clear example of an ML application as a service, where people can implement chatbots with minimum development.
AWS Rekognition is another example, which aims to identify objects, people, text, scenes, and activities in images and videos. AWS provides many other ML application services that will be covered in the next chapter of this book.
Apart from application services, AWS also provides ML development platforms, which is the case with SageMaker. Unlike out-of-the-box services such as AWS Lex and Rekognition, SageMaker is a development platform that will let you build, train, and deploy your own models with much more flexibility.
SageMaker speeds up the development and deployment process by automatically handling the necessary infrastructure for the training and inference pipelines of your models. Behind the scenes, SageMaker orchestrates other AWS services (such as EC2 instances, load balancers, auto-scaling, and so on) to create a scalable environment for ML projects. SageMaker is probably the most important service that you should master for the AWS Machine Learning Specialty exam, and it will be covered in detail in a separate section. For now, you should focus on understanding the different approaches that AWS uses to offers ML-related services.
The third option that AWS offers for deploying ML models is the most generic and flexible one: you can deploy ML models by combining different AWS services and managing them individually. This is essentially doing what SageMaker does for you, building your applications from scratch. For example, you could use EC2 instances, load balancers, auto-scaling, and an API gateway to create an inference pipeline to a particular model. If you prefer, you can also use AWS serverless architecture to deploy your solution, for example, using AWS Lambda functions.
Summary
We are now heading to the end of this chapter, where we have covered several important topics about the foundations of ML. We started the chapter with a theoretical discussion about AI, ML, and DL and how this entire field has grown over the past few years due to the advent of big data platforms and cloud providers.
We then moved on to the differences between supervised, unsupervised, and reinforcement learning, highlighting some use cases related to each of them. This is likely to be a topic in the AWS Machine Learning Specialty exam.
We discussed that an ML model is built in many different stages and the algorithm itself is just one part of the modeling process. We also covered the expected behaviors of a good model.
We did a deep dive into data splitting, where we talked about different approaches to train and validate models, and we covered the mythic battle between variance and bias. We completed the chapter by talking about ML frameworks and services.
Coming up next, you will learn about AWS application services for ML, such as Amazon Polly, Amazon Rekognition, Amazon Transcribe, and many other AI-related AWS services. But first, let's look into some sample questions to give you an idea of what you could expect in the exam.
Questions
- You have been hired to automate an audible response unit from a call center company. Every time a new customer's call comes in, the system must be able to understand the current load of the service as well as the goal of the call and recommend the right path in the audible response unit. The company does not have labeled data to supervise the model; it must take an approach to learn by experience (trial and error) and every time the algorithm makes a good recommendation of path, it will be rewarded. Which type of machine learning approach would best fit this project?
a) Unsupervised learning
b) Reinforcement learning
c) Supervised learning
d) DL
Answer
b, Since there is no labeled data and the agent needs to learn by experience, reinforcement learning is more appropriate for this use case. Another important fact in the question is that the agent is rewarded for good decisions.
- You are working in a marketing department of a big company and you need to segment your customers based on their buying behavior. Which type of ML approach would best fit this project?
a) Unsupervised learning
b) Reinforcement learning
c) Supervised learning
d) DL
Answer
a, Clustering (which is an unsupervised learning approach) is the most common type of algorithm to work with data segmentation/clusters.
- You are working in a retail company that needs to forecast sales for the next few months. Which type of ML approach would best fit this project?
a) Unsupervised learning
b) Reinforcement learning
c) Supervised learning
d) DL
Answer
c, Forecasting is a type of supervised learning that aims to predict a numerical value; hence, it might be framed as a regression problem and supervised learning.
- A manufacturing company needs to understand how much money they are spending on each stage of their production chain. Which type of ML approach would best fit this project?
a) Unsupervised learning.
b) Reinforcement learning.
c) Supervised learning.
d) ML is not required.
Answer
d, ML is everywhere, but not everything needs ML. In this case, there is no need to use ML since the company should be able to collect their costs from each stage of the production chain and sum it up.
- Which one of the following learning approaches gives us state-of-the-art algorithms to implement chatbots?
a) Unsupervised learning
b) Reinforcement learning
c) Supervised learning
d) DL
Answer
d, DL has provided state-of-the-art algorithms in the field of natural language processing.
- You receive a training set from another team to create a binary classification model. They have told you that the dataset was already shuffled and ready for modeling. You have decided to take a quick look at how a particular algorithm, based on a neural network, would perform on it. You then split the data into train and test sets and run your algorithm. However, the results look very odd. It seems that the algorithm could not converge to an optimal solution. What would be your first line of investigation on this issue?
a) Make sure the algorithm used is able to handle binary classification models.
b) Take a look at the proportion of data of each class and make sure they are balanced.
c) Shuffle the dataset before starting working on it.
d) Make sure you are using the right hyperparameters of the chosen algorithm.
Answer
c, Data scientists must be skeptical about their work. Do not make assumptions about the data without prior validation. At this point in the book, you might not be aware of the specifics of neural networks, but you know that ML models are very sensitive to the data they are training on. You should double-check the assumptions that were passed to you before taking other decisions. By the way, shuffling your training data is the first thing you should do. This is likely to be present in the exam.
- You have created a classification model to predict whether a banking transaction is fraud or not. During the modeling phase, your model was performing very well on both the training and testing sets. When you executed the model in a production environment, people started to complain about the low accuracy of the model. Assuming that there was no overfitting/underfitting problem during the training phase, what would be your first line of investigation?
a) The training and testing sets do not follow the same distribution.
b) The training set used to create this model does not represent the real environment where the model was deployed.
c) The algorithm used in the final solution could not generalize enough to identify fraud cases in production.
d) Since all ML models contain errors, we can't infer their performance in production systems.
Answer
b, Data sampling is very challenging, and you should always make sure your training data can represent the production data as precisely as possible. In this case, there was no evidence that the training and testing sets were invalid, since the model was able to perform well and consistently on both sets of data. Since the problem happens to appear only in production systems, there might have been a systematic issue in the training that is causing the issue.
- You are training a classification model with 500 features that achieves 90% accuracy in the training set. However, when you run it in the test set, you get only 70% accuracy. Which of the following options are valid approaches to solve this problem (select all that apply)?
a) Reduce the number of features.
b) Add extra features.
c) Implement cross-validation during the training process.
d) Select another algorithm.
Answer
a, c, This is clearly an overfitting issue. In order to solve this type of problem, you could reduce the excessive number of features (which will reduce the complexity of the model and make it less dependent on the training set). Additionally, you could also implement cross-validation during the training process.
- You are training a neural network model and want to execute the training process as quickly as possible. Which of the following hardware architectures would be most helpful to you to speed up the training process of neural networks?
a) Use a machine with a CPU that implements multi-thread processing.
b) Use a machine with GPU processing.
c) Increase the amount of RAM of the machine.
d) Use a machine with SSD storage.
Answer
b, Although you might take some benefits from multi-thread processing and large amounts of RAM, using a GPU to train a neural network will give you the best performance. You will learn much more about neural networks in later chapters of this book, but you already know that they perform a lot of matrix calculations during training, which is better supported by the GPU rather than the CPU.
- Which of the following statements is not true about data resampling?
a) Cross-validation is a data resampling technique that helps to avoid overfitting during model training.
b) Bootstrapping is a data resampling technique often embedded in ML models that needs resampling capabilities to estimate the target function.
c) The parameter k in k-fold cross-validation specifies how many samples will be created.
d) Bootstrapping works without replacement.
Answer
d, All the statements about cross-validation and bootstrapping are correct except option d, since bootstrapping works with replacement (the same observations might appear on different splits).






