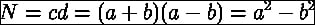Chapter 3. Get to Grips with Commonly Used Functions
In this chapter, we will cover a number of commonly used functions:
sqrt, log, arange, astype, and sum
ceil, modf, where, ravel, and take
sort and outer
diff, sign, eig
histogram and polyfit
compress and randint
We will be discussing these functions through the following recipes:
Summing Fibonacci numbers
Finding prime factors
Finding palindromic numbers
The steady state vector determination
Discovering a power law
Trading periodically on dips
Simulating trading at random
Sieving integers with the Sieve of Eratosthenes
This chapter is about the commonly used functions. These are the functions that you will be using on a daily basis. Obviously, the usage may differ for you. There are so many NumPy functions that it is virtually impossible to know all of them, but the functions in this chapter will be the bare minimum with which we must be familiar. You can download source code for this chapter from the book website http://www.packtpub.com.
Summing Fibonacci numbers
In this recipe, we will sum the even-valued terms in the Fibonacci sequence whose values do not exceed four million. The Fibonacci series is a sequence of integers starting with zero, where each number is the sum of the previous two; except, of course, the first two numbers zero and one.
This recipe uses a formula based on the golden ratio, which is an irrational number with special properties comparable to pi. It we will use the
sqrt,
log,
arange,
astype, and
sum functions.
The first thing to do is calculate the golden ratio (http://en.wikipedia.org/wiki/Golden_ratio), also called the golden section or golden mean.
Calculate the golden ratio.
We will be using the
sqrt function to calculate the square root of five:
This prints the golden mean:
Find the index below...
Prime factors (http://en.wikipedia.org/wiki/Prime_factor) are prime numbers that divide an integer exactly without a remainder. Finding prime factors seems almost impossible to crack. However, using the right algorithm—Fermat's factorization method (http://en.wikipedia.org/wiki/Fermat%27s_factorization_method) and NumPy—it becomes very easy. The idea is to factor a number N into two numbers c and d, according to the following equation:
We can apply the factorization recursively, until we get the required prime factors.
The algorithm requires us to try a number of trial values for a.
Create an array of trial values.
It makes sense to create a NumPy array and eliminate the need for loops. However, you should be careful to not create an array that is too big in terms of memory requirements. On my system, an array of a million elements seems to be just the right size:
We...
Finding palindromic numbers
A palindromic number reads the same both ways. The largest palindrome made from the product of two 2-digit numbers is 9009 = 91 x 99. Let's try to find the largest palindrome made from the product of two 3-digit numbers.
We will create an array to hold 3-digit numbers from 100 to 999 using our favorite NumPy function arange.
Create a 3-digit numbers array.
Check the first and last element of the array with the assert_equal function from the numpy.testing package:
Create the products array
Now, we will create an array to hold all the possible products of the elements of the 3-digits array with itself. We can accomplish this with the outer function. The resulting array needs to be flattened with ravel, to be able to easily iterate over it. Call the sort method on the array to make sure the array is properly sorted. After that, we can do some sanity checks...
The steady state vector determination
A
Markov chain is a system that has at least two states. For detailed information on Markov chains, please refer to http://en.wikipedia.org/wiki/Markov_chain.The state at time t depends on the state at time t-1, and only the state at t-1. The system switches at random between these states. I would like to define a Markov chain for a stock. Let's say that we have the states flat F, up U, and down D. We can determine the steady state based on end of day close prices.
Far into the distant future or in theory infinite time, the state of our Markov chain system will not change anymore. This is also called a steady state (http://en.wikipedia.org/wiki/Steady_state). The
stochastic matrix (http://en.wikipedia.org/wiki/Stochastic_matrix) A, which contains the state transition probabilities, and when applied to the steady state, will yield the same state x. The mathematical notation for this will be as follows:
Another way to look at this is as the
eigenvector...
For the purpose of this recipe, imagine that we are operating a Hedge Fund. Let it sink in; you are part of the one percent now!
Power laws occur in a lot of places, see http://en.wikipedia.org/wiki/Power_law for more information. The
Pareto principle (http://en.wikipedia.org/wiki/Pareto_principle) for instance, which is a power law, states that wealth is unevenly distributed. This principle tells us that if we group people by their wealth, the size of the groups will vary exponentially. To put it simply, there are not a lot of rich people, and there are even less billionaires; hence the one percent.
Assume that there is a power law in the closing stock prices log returns. This is a big assumption, of course, but power law assumptions seem to pop up all over the place.
We don't want to trade too often, because of involved transaction costs per trade. Let's say that we would prefer to buy and sell once a month based on a significant correction (in other words a big drop...
Trading periodically on dips
Stock prices periodically dip and go up. We will have a look at the probability distribution of the stock price log returns.
Let's start by downloading the historical data for a stock; for instance, AAPL. Next, calculate the daily log returns (http://en.wikipedia.org/wiki/Rate_of_return) of the close prices. We will skip these steps because they were already done in the previous recipe.
If necessary, install Matplotlib and SciPy. Refer to the See Also section for the corresponding recipes.
Now comes the interesting part.
Calculate breakout and pullback.
Let's say we want to trade five times per year, or roughly every 50 days. One strategy would be to buy when the price drops by a certain percentage—a pullback, and sell when the price increases by another percentage—a breakout.
By setting the percentile appropriate for our trading frequency, we can match the corresponding log returns. SciPy offers the scoreatpercentile function, which we...
Simulating trading at random
In the previous recipe, we tried out a trading idea. However, we have no benchmark that can tell us if the result we got was any good. It is
common in such cases to trade at random, under the assumption that we should be able to beat a random process. We will simulate trading by taking some random days from a trading year. This should illustrate working with random numbers using NumPy.
If necessary, install Matplotlib. Refer to the See Also section for the corresponding recipe.
First, we need an array filled with random integers.
Generate random indices.
Generate random integers with the NumPy randint function. This will be linked to random days of a trading year:
Simulate trades.
Simulate trades with the random indices from the previous step. Use the NumPy take function to extract random close prices from the array of step 1:
Sieving integers with the Sieve of Erasthothenes
The
Sieve of Eratosthenes (http://en.wikipedia.org/wiki/Sieve_of_Eratosthenes) is an algorithm that filters out prime numbers. It iteratively identifies multiples of found primes. This sieve is efficient for primes smaller than 10 million. Let's now try to find the 10001st prime number.
The first mandatory step is to create a list of natural numbers.
Create a list of consecutive integers.
NumPy has the arange function for that:
Sieve out multiples of p.
We are not sure if this is what Eratosthenes wanted us to do, but it works. In the following code, we are passing a NumPy array and getting rid of all the elements that have a zero remainder, when divided by p:
The following is the entire code for this problem: