

CAPTCHA stands for Completely Automated Public Turing test to tell Computers and Humans Apart. As the acronym suggests, it is a test to determine whether the user is human or not. A typical CAPTCHA consists of distorted text, which a computer program will find difficult to interpret but a human can (hopefully) still read. Many websites use CAPTCHA to try and prevent bots from interacting with their website. For example, my bank website forces me to pass a CAPTCHA every time I log in, which is a pain. This chapter will cover how to solve a CAPTCHA automatically, first through Optical Character Recognition (OCR) and then with a CAPTCHA solving API.

In the preceding chapter on forms, we logged in to the example website using a manually created account and skipped automating the account creation part, because the registration form requires passing a CAPTCHA. This is how the registration page at http://example.webscraping.com/user/register looks:
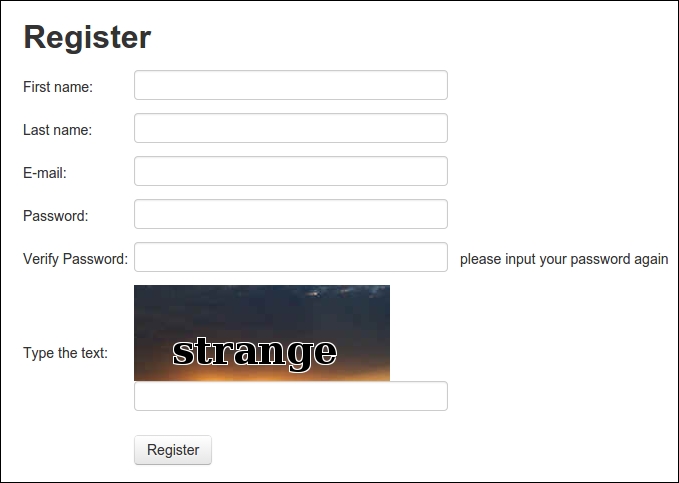
Note that each time this form is loaded, a different CAPTCHA image will be shown. To understand what the form requires, we can reuse the parse_form() function developed in the preceding chapter.
>>> import cookielib, urllib2, pprint
>>> REGISTER_URL = 'http://example.webscraping.com/user/register'
>>> cj = cookielib.CookieJar()
>>> opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
>>> html = opener.open(REGISTER_URL).read()
>>> form = parse_form(html)
>>> pprint.pprint(form)
{'_formkey': '1ed4e4c4-fbc6-4d82-a0d3-771d289f8661',
'_formname': 'register',
'_next': '/',
'email': '',
'first_name': ...
Optical Character Recognition (OCR) is a process to extract text from images. In this section, we will use the open source Tesseract OCR engine, which was originally developed at HP and now primarily at Google. Installation instructions for Tesseract are available at https://code.google.com/p/tesseract-ocr/wiki/ReadMe. Then, the pytesseract Python wrapper can be installed with pip:
pip install pytesseract
If the original CAPTCHA image is passed to pytesseract, the results are terrible:
>>> import pytesseract >>> img = get_captcha(html) >>> pytesseract.image_to_string(img) ''
An empty string was returned, which means Tesseract failed to extract any characters from the input image. Tesseract was designed to extract more typical types of text, such as book pages with a consistent background. If we want to use Tesseract effectively, we will need to first modify the CAPTCHA images to remove the background noise and isolate the text. To better...
The CAPTCHA system tested so far was relatively straightforward to solve—the black font color meant the text could easily be distinguished from the background, and additionally, the text was level and did not need to be rotated for Tesseract to interpret it accurately. Often, you will find websites using simple custom CAPTCHA systems similar to this, and in these cases, an OCR solution is practical. However, if a website uses a more complex system, such as Google's reCAPTCHA, OCR will take a lot more effort and may not be practical. Here are some more complex CAPTCHA images from around the web:

In these examples, the text is placed at different angles and with different fonts and colors, so a lot more work needs to be done to clean the image before OCR is practical. They are also somewhat difficult for people to interpret, particularly for those with vision disabilities.
This chapter showed how to solve CAPTCHAs, first by using OCR, and then with an external API. For simple CAPTCHAs, or for when you need to solve a large amount of CAPTCHAs, investing time in an OCR solution can be worthwhile. Otherwise, using a CAPTCHA solving API can prove to be a cost effective alternative.
In the next chapter, we will introduce Scrapy, which is a popular high-level framework used to build scraping applications.
The rest of the chapter is locked
You have been reading a chapter from
Web Scraping with PythonPublished in: Oct 2015Publisher: PacktISBN-13: 9781782164364
Register for a free Packt account to unlock a world of extra content!
A free Packt account unlocks extra newsletters, articles, discounted offers, and much more. Start advancing your knowledge today.
undefined
Unlock this book and the full library FREE for 7 days
Get unlimited access to 7000+ expert-authored eBooks and videos courses covering every tech area you can think of
Renews at $15.99/month. Cancel anytime