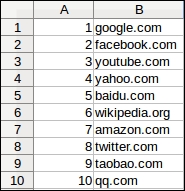
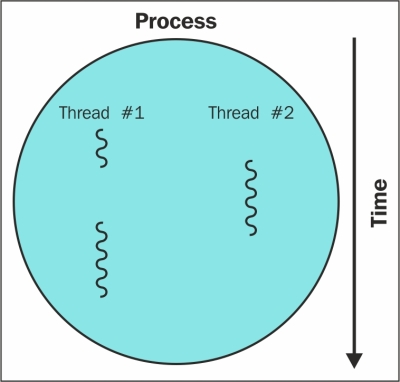
In previous chapters, our crawlers downloaded web pages sequentially, waiting for each download to complete before starting the next one. Sequential downloading is fine for the relatively small example website but quickly becomes impractical for larger crawls. To crawl a large website of 1 million web pages at an average of one web page per second would take over 11 days of continuous downloading all day and night. This time can be significantly improved by downloading multiple web pages simultaneously.
This chapter will cover downloading web pages with multiple threads and processes, and then compare the performance to sequential downloading.