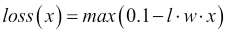In this chapter, we will introduce some advanced regression methods. Since many of them are very complex, we will skip most of the mathematical formulations, providing the readers instead with the ideas underneath the techniques and some practical advice, such as explaining when and when not to use the technique. We will illustrate:
Least Angle Regression (LARS)
Bayesian regression
SGD classification with hinge loss (note that this is not a regressor, it's a classifier)
Regression trees
Ensemble of regressors (bagging and boosting)
Gradient Boosting Regressor with Least Angle Deviation