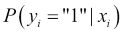In this chapter, another supervised method is introduced: classification. We will introduce the simplest classifier, the Logistic Regressor, which shares the same foundations as the Linear Regressor, but it targets classification problems.
In the following chapter, you'll find:
A formal and mathematical definition of the classification problem, for both binary and multiclass problems
How to evaluate classifier performances—that is, their metrics
The math behind Logistic Regression
A revisited formula for SGD, specifically built for Logistic Regression
The multiclass case, with Multiclass Logistic Regression