


Security is not a new concept. It's been adopted since the early UNIX time-sharing operating system design. In the recent past, security awareness has increased among individuals and organizations on this security front due to the widespread data breaches that led to a lot of revenue loss to organizations.
Security, as a general concept, can be applied to many different things. When it comes to data security, we need to understand the following fundamental questions:
- What types of data exist?
- Who owns the data?
- Who has access to the data?
- When does the data exit the system?
- Is the data physically secured?
Let's have a look at a simple big data system and try to understand these questions in more detail. The scale of the systems makes security a nightmare for everyone. So, we should have proper policies in place to keep everyone on the same page:
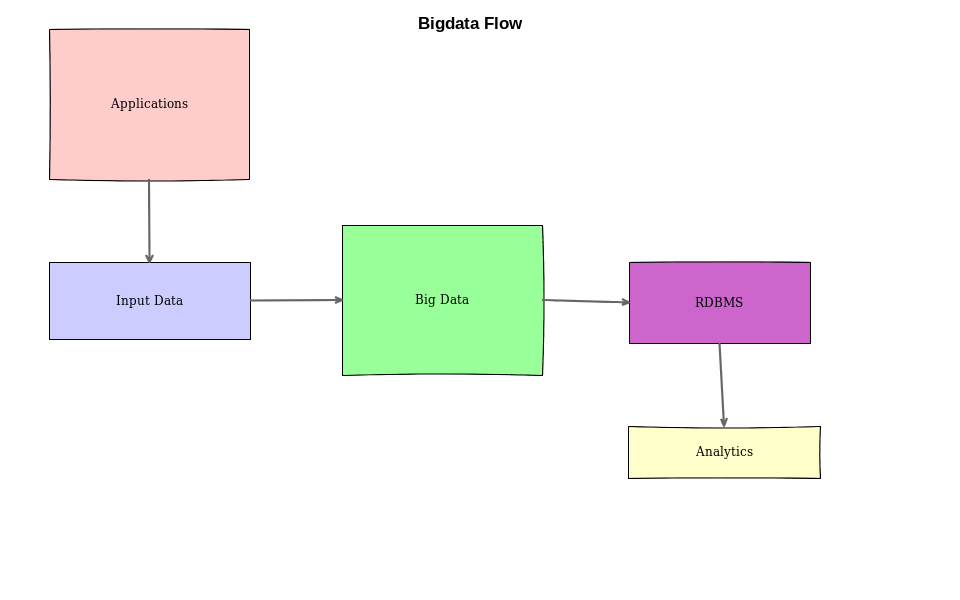
In this example, we have the following components:
- Heterogeneous applications running across the globe in multiple geographical regions.
- Large volume and variety of input data is generated by the applications.
- All the data is ingested into a big data system.
- ETL/ELT applications consume the data from a big data system and put the consumable results into RDBMS (this is optional).
- Business intelligence applications read from this storage and further generate insights into the data. These are the ones that power the leadership team's decisions.
You can imagine the scale and volume of data that flows through this system. We can also see that the number of servers, applications, and employees that participate in this whole ecosystem is very large in number. If we do not have proper policies in place, its not a very easy task to secure such a complicated system.
Also, if an attacker uses social engineering to gain access to the system, we should make sure that the data access is limited only to the lowest possible level. When poor security implementations are in place, attackers can have access to virtually all the business secrets, which could be a serious loss to the business.
Just to think of an example, a start-up is building a next-generation computing device to host all its data on the cloud and does not have proper security policies in place. When an attacker compromises the security of the servers that are on the cloud, they can easily figure out what is being built by this start-up and can steal the intelligence. Once the intelligence is stolen, we can imagine how hackers use this for their personal benefit.
With this understanding of security's importance, let's define what needs to be secured.