





















































Transforming and Cleansing Data
The transformations applied within Power BI's M queries serve to protect the integrity of the data model and to support enhanced analysis and visualization. The specific transformations to implement varies based on data quality, integration needs, and the goals of the overall solution. However, at a minimum, developers should look to protect the integrity of the model's relationships and to simplify the user experience via denormalization and standardization. Additionally, developers should check with owners of the data source to determine whether certain required transformations can be implemented in the source, or perhaps made available via SQL view objects such that Power Query (M) expressions are not necessary.
This recipe demonstrates how to protect a model from duplicate values within the source data that can prevent forming proper relationships within the data model, which may even result in query failures. While a simple scenario is used, this recipe demonstrates scenarios you may run into while attempting to merge multiple data sources and eliminating duplicates.
Getting ready
To prepare, start by importing the DimProduct and FactResellerSales tables from the AdventureWorksDW2019 database by doing the following:
- Open Power BI Desktop and choose Transform data from the ribbon of the Home tab to open the Power Query Editor.
- Create an Import mode data source query called AdWorksDW. This query should be similar to the following:
let Source = Sql.Database("localhost\MSSQLSERVERDEV", "AdventureWorksDW2019") in Source - Isolate this query in a query group called Data Sources.
- Right-click AdWorksDW and choose Reference, select the DimProduct table in the data preview area, and rename this query DimProduct. Right-click the EnglishProductName column and select Remove Other Columns.
- Repeat the previous step, but this time choose FactResellerSales. Expand the DimProduct column and only choose EnglishProductName. Rename this column to EnglishProductName.
- Drag the DimProduct and FactResellerSales queries into the Other Queries group and apply the queries to the data model.
- In the Model view of Power BI Desktop, attempt to form a relationship between the tables using the EnglishProductName columns from both tables. Note the warning that is displayed.

Figure 2.31: Many-Many relationship cardinality warning
For additional details on performing these steps, see the Managing Queries and Data Sources recipe in this chapter.
How to Transform and Cleanse Data
We wish to remove duplicates from the EnglishProductName column in our DimProduct query. To implement this recipe, use the following steps:
- Remove any leading and trailing empty spaces in the
EnglishProductNamecolumn with aText.Trimfunction. - Create a duplicate column of the
EnglishProductNamekey column with theTable.DuplicateColumnfunction and name this new columnProduct Name. - Add an expression to force uppercase on the
EnglishProductNamecolumn via theTable.TransformColumnsfunction. This new expression must be applied before the duplicate removal expressions are applied. - Add an expression to the DimProduct query with the
Table.Distinctfunction to remove duplicate rows. - Add another
Table.Distinctexpression to specifically remove duplicate values from theEnglishProductNamecolumn. - Drop the capitalized
EnglishProductNamecolumn viaTable.RemoveColumns.The final query should resemble the following:
let Source = AdWorksDW, dbo_DimProduct = Source{[Schema="dbo",Item="DimProduct"]}[Data], RemoveColumns = Table.SelectColumns(dbo_DimProduct,{"EnglishProductName"}), TrimText = Table.TransformColumns( RemoveColumns,{"EnglishProductName",Text.Trim} ), DuplicateKey = Table.DuplicateColumn( TrimText,"EnglishProductName","Product Name" ), UpperCase = Table.TransformColumns( DuplicateKey,{{"EnglishProductName", Text.Upper}} ), DistinctProductRows = Table.Distinct(UpperCase), DistinctProductNames = Table.Distinct( DistinctProductRows, {"EnglishProductName"} ), RemoveEnglishProductName = Table.RemoveColumns( DistinctProductNames,"EnglishProductName" ) in RemoveEnglishProductName
How it works
In the TrimText expression, the Trim.Text function removes white space from the beginning and end of a column. Different amounts of empty space make those rows distinct within the query engine, but not necessarily distinct within the model. Therefore, it is always a good idea to use Trim.Text first and then remove duplicate rows and values.
In the next expression, DuplicateKey, the Table.DuplicateColumn function is used to duplicate the column where we will be removing duplicate values. We give this new column the name that we desire for our final column. This is done because we will need to transform the values in the column we are removing duplicates from, in order to account for mixed cases such as "Fender Set" and "Fender set". Thus, we wish to preserve the original values and casing by using this duplicate column.
In order to eliminate mixed casing issues, the UpperCase expression changes all values in the EnglishProductName column to uppercase using the Table.TransformColumns function, and specifying Text.Upper. The M engine considers mixed casing values unique, but the data model engine does not.
The next two expressions, DistinctProductRows and DistinctProductNames, simply demonstrate two different methods of using the Table.Distinct function. The first, DistinctProductRows, eliminates rows where the entire row (all column values) are identical. The second version looks only at the values in a single column when determining whether or not the row is a duplicate.
At this point, the query is now resilient to duplicate values and rows, mixed cases, and spaces. However, the EnglishProductName column is now in the uppercase format. Since we preserved a copy of the original values and casing in our Product Name column, we can simply drop the EnglishProductName column using the Table.RemoveColumns function.
We can now form a one-to-many relationship between our DimProduct and FactResellerSales tables.
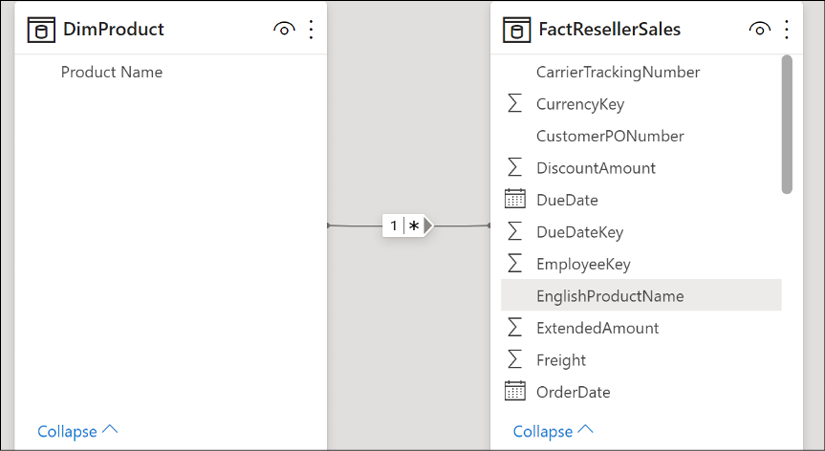
Figure 2.32: Simple one-to-many relationship model
There's more...
To support troubleshooting, create a query that accesses the same source table and retrieves the values from the EnglishProductName column with more than one row.
let
Source = AdWorksDW,
dbo_DimProduct = Source{[Schema="dbo",Item="DimProduct"]}[Data],
RemoveColumns = Table.SelectColumns(dbo_DimProduct,{"EnglishProductName"}),
TrimText =
Table.TransformColumns(
RemoveColumns,{"EnglishProductName",Text.Trim}
),
UpperCase =
Table.TransformColumns(
TrimText,{{"EnglishProductName", Text.Upper}}
),
GroupedRows =
Table.Group(
UpperCase, {"EnglishProductName"},
{{"Rows", each Table.RowCount(_), Int64.Type}}
),
Duplicates = Table.SelectRows(GroupedRows, each [Rows] > 1)
in
Duplicates
The EnglishProductName column is selected, trimmed, converted to uppercase, grouped, and then filtered to always retrieve any duplicate key values. Disable the loading of this query, as the query would only exist for troubleshooting purposes.
See also
Table.SelectColumns: http://bit.ly/38Qk7LtTable.RemoveColumns: http://bit.ly/3cJju7pTable.TransformColumns: http://bit.ly/3tsdxm2Table.DuplicateColumn: http://bit.ly/3cIF63XTable.Distinct: http://bit.ly/38V8mmNText.Trim: http://bit.ly/3eUmAZ0Text.Upper: http://bit.ly/3vFW2R6- M functions reference for text: http://bit.ly/2nUYjnw



















