





















































Exploratory data analysis (EDA) is a crucial component of a data science project (as shown in Figure Data Science Process). Even though it is a very important step before applying any statistical model or machine learning algorithm to your data, it is often skipped or underestimated by many practitioners:
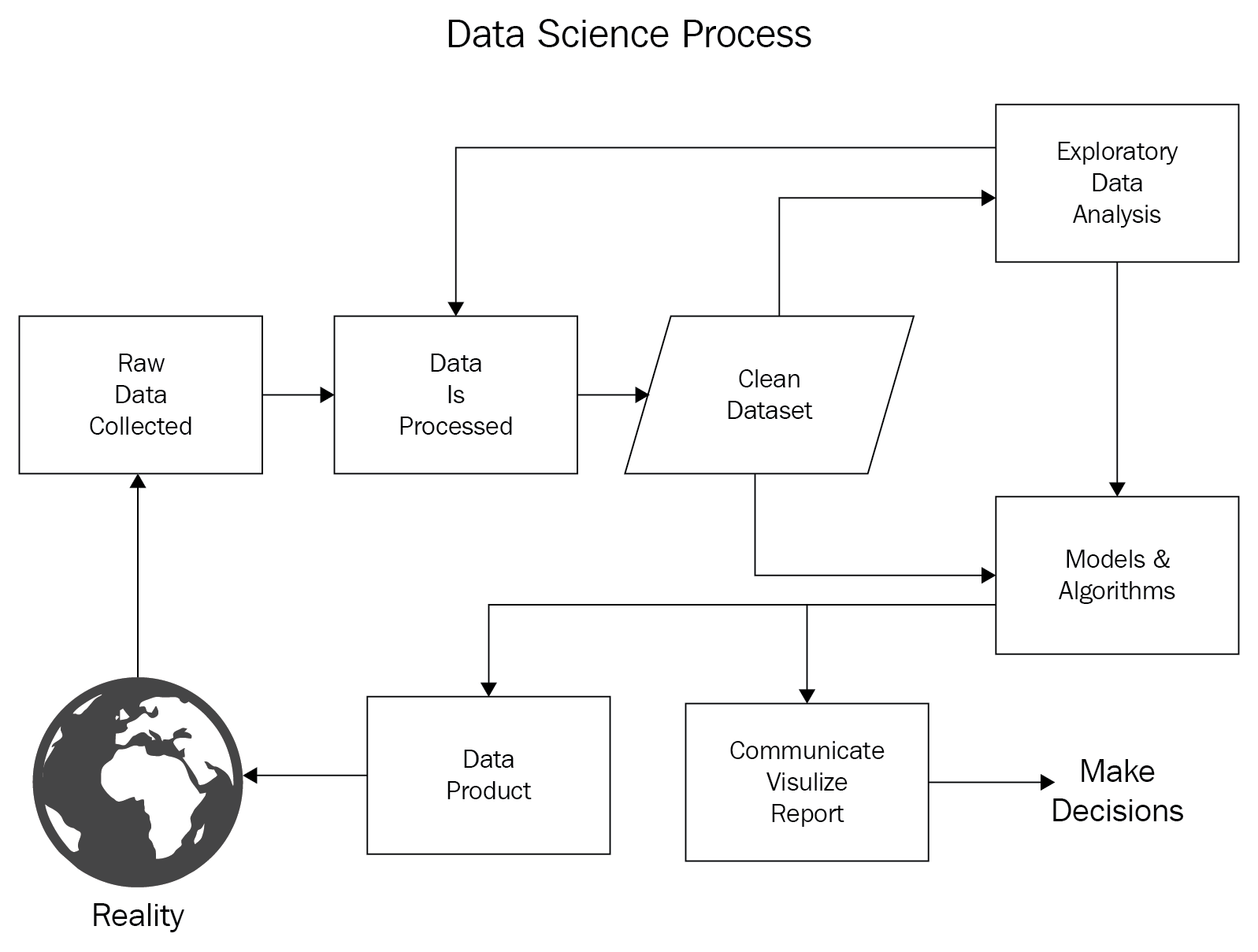
John Wilder Tukey promoted exploratory data analysis in 1977 with his book Exploratory Data Analysis. In his book, he guides statisticians to analyze their datasets statistically by using several different visuals, which will help them to formulate their hypotheses. In addition, EDA is also used to prepare your analysis for advance modeling after you identify the key data characteristics and learn which questions you should ask about your...




















