We are now at the last leg of our journey. We started off with the very basics of images, pixels and their traversals, and gradually moved on to our very first image processing algorithms: image filtering box filter as well as Gaussian smoothing). Gradually, we paved our way up to the more sophisticated image processing and computer vision algorithms such as image histograms, thresholding and edge detectors. To understand and grasp the true power of the OpenCV library, we demonstrated how seemingly complex algorithms, such as those for detecting faces in images, can be so effortlessly run by a single line of OpenCV / C++ code!
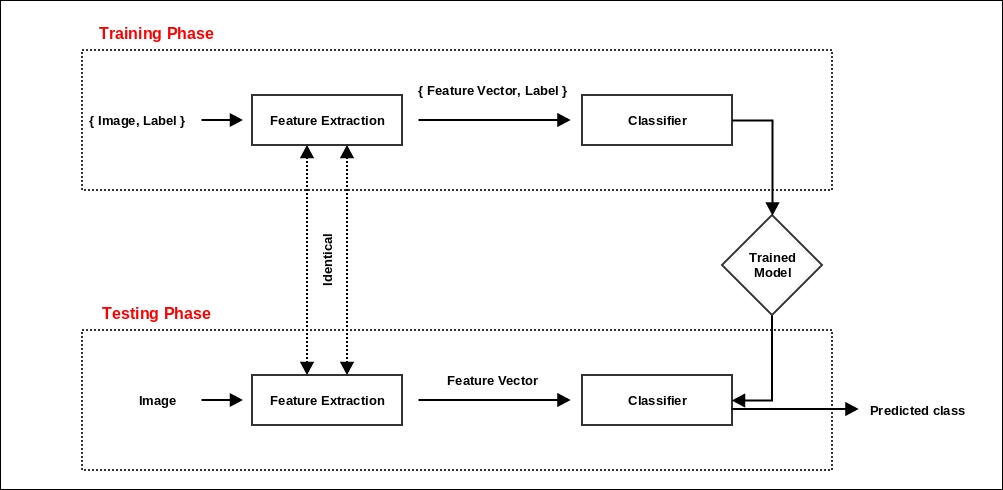
After having covered the major parts of the OpenCV toolkit, it was time to dig into a real-world project. Using the example of gender classification from facial images, we demonstrated the concept of feature detectors, especially digging deeper into the nuances of the uniform pattern LBP histograms. This chapter will witness a...